登录社区云,与社区用户共同成长
邀请您加入社区
本研究深入探讨了基于机器学习的手机评论文本情感分析以及利用随机森林算法进行评论量预测的问题。在情感分析部分,首先对收集的大量手机评论文本进行了预处理,包括文本清洗、分词、去停用词等步骤,以净化和规范数据。随后,提取了关键词、词性、情感词等多种特征,有效提升了手机评论文本情感分析的准确性和效率。在评论量预测部分,采用了随机森林算法对手机评论量进行预测。通过构建特征集,包括时间特征、文本特征和用户特征
本文研究基于机器学习的微博情感分析方法,提出从微博文本中提取词频、词向量等特征,采用支持向量机、朴素贝叶斯等算法进行情感分类。实验表明该方法具有较高准确率和泛化能力。系统设计包括数据爬取、HDFS存储、Spark处理和Django可视化模块,通过饼状图、柱状图展示手机品牌评论数、点赞数等数据分布。研究发现微博情感分析在用户心理研究、热点话题挖掘等方面具有重要应用价值。
对于ReLU激活函数,推荐使用“He初始化”:W[l] = np.random.randn(shape) * np.sqrt(2 / n[l-1])对于tanh或sigmoid,推荐使用“Xavier初始化”:W[l] = np.random.randn(shape) * np.sqrt(1 / n[l-1])## 代码示例一:实现深度神经网络的前向传播下面是一个简单的深度神经网络前向传播代码,包
本文用通俗易懂的方式向高中生科普了大语言模型的核心原理。文章首先指出,像ChatGPT这样的AI本质上是一个"下一个字预测器",通过不断预测最可能的下一个字来生成连贯文本。然后解释了神经网络如何通过组合无数简单函数(神经元)来逼近这个复杂的概率函数,这得益于数学上的"万能近似定理"。进一步介绍了Transformer结构及其关键组件——自注意力机制,它让模型能动态关注上下文中最重要的信息。最后用流
本文从神经风格迁移的原理出发,深入浅出地讲解了如何利用OpenCV DNN 模块轻松实现静态图像和实时摄像头的风格迁移。全部代码不超过 30 行,却展现了人工智能与艺术的奇妙结合。无论你是计算机视觉的初学者,还是想快速开发一个创意应用,这都是一份极佳的参考。未来,随着等轻量级网络的出现,风格迁移将变得更加高效,甚至可以运行在微型设备上。而结合GAN的CycleGANAnimeGAN等技术,更是让实
PHP的开发入门门槛低,部署简单,拥有大量成熟的Web开发框架(如Laravel、Symfony),使其在中小型Web项目和企业官网开发中依然保持着强大的生命力。尽管在面对极其复杂的业务逻辑或高性能要求的现代Web应用时,其性能和处理能力可能不如Java或Go等语言,但凭借其庞大的现有用户群和丰富的资源,PHP依然是Web领域的重要力量。其严格的类型系统和较强的封装性有利于构建大规模、可维护的代码
作者按:实际开发中建议搭配 C++20 Concepts 和 `std::ranges::actions` 对象(如 `drop` , `append` )使用,以充分释放潜力。- 视图适配器(Adapters):`filter`, `transform`, `take_while`, `join` 等,支持无缝扩展。- `take`, `drop`, 和 `cartesian_product`
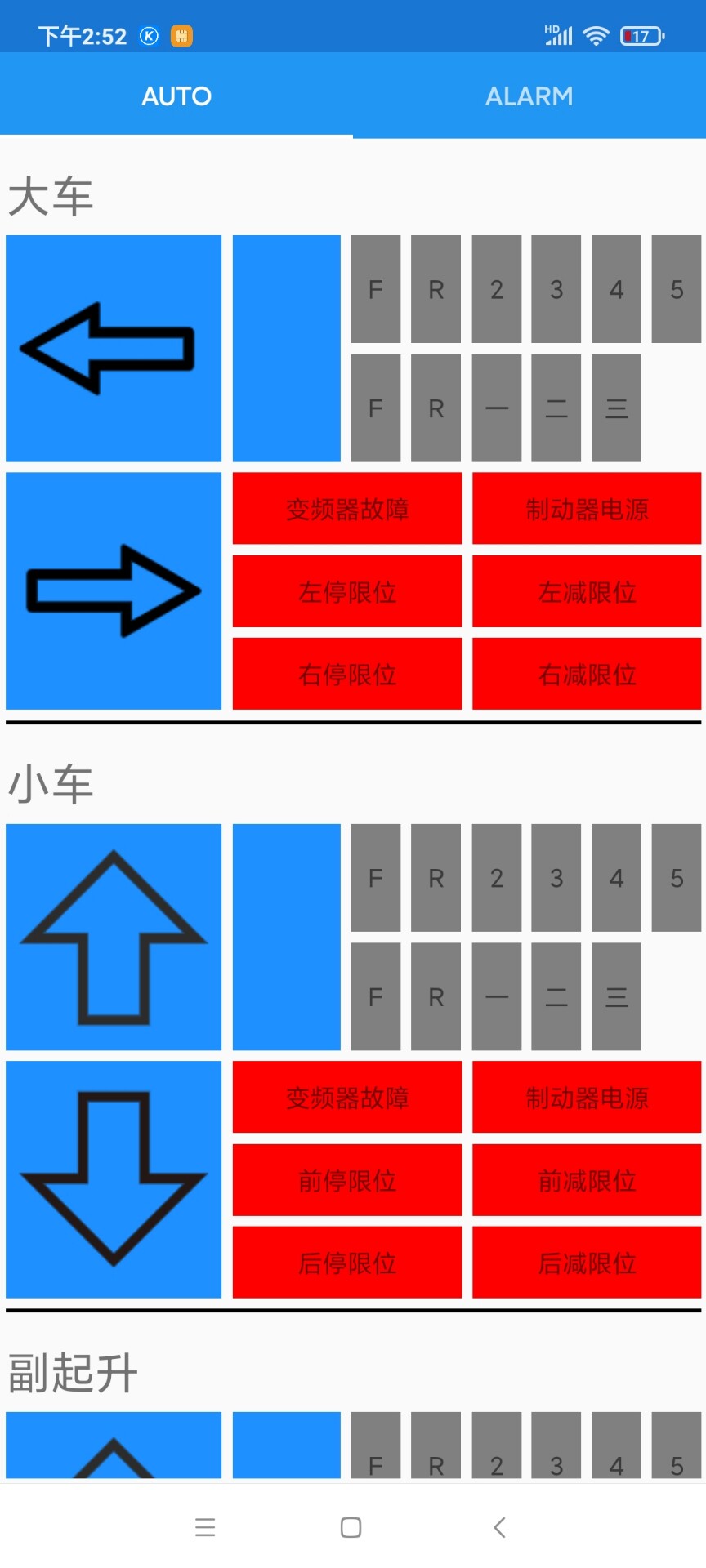
至此,JXQZ Android 端不仅是一个“遥控界面”,而是集高可靠通信、零延迟报警、企业级安全于一体的工业级移动终端,为起重机智能化提供了可复制的移动范本。JXQZ 起重机遥控 APP —— Xamarin.Android 端架构与运行时剖析。5,项目完整架构,本项目是针对起重机高空不易维护问题开发的。1,C#开发上位机手机APP,自己写的程序可提供部分。6,功能完善,数据库,语音报警,数据报
本文介绍了一个基于Django框架开发的课程教学评价系统,旨在通过线上化管理实现教学评价的高效整合与个性化服务。该系统采用Python语言开发,结合MySQL数据库,提供了用户管理、评价数据处理、论坛交流等核心功能模块。通过Django的MTV模式设计,系统具有良好的可扩展性和安全性,能够满足高并发访问需求。项目实现了教学评价数据的可视化展示与智能预测,突破了传统管理模式的局限,提升了用户体验和平
某天盯着易拉罐上的红色波浪Logo突然想:要是摄像头能自动识别这个标志,联动自动售货机补货该多有趣。最后来个冷知识:用C++的OpenCV处理200ms每帧,换成C#+EmguCV可能变成300ms。不是语言问题,而是托管代码的GC在作妖,实时系统记得用Native代码+内存池优化。模板匹配像是精准的狙击枪,特征匹配像霰弹枪——没有绝对的好坏,关键看场景。下次在便利店看到自动识别Logo的机器,说
从Key帧检索到场景匹配,教你如何在海量视频库中,用一张图片定位到精确帧!
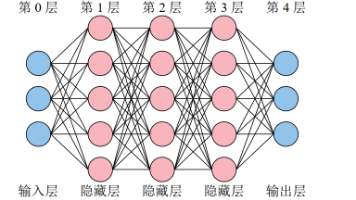
前向传播是指:数据从输入层经过各层神经元的加权求和与激活函数运算,逐层传递,最终在输出层得到预测结果的过程。它可以看作是一种函数复合x 为输入,L为网络层数,f(l) 表示第 l 层的非线性变换。深度神经网络通过多层结构和非线性映射实现了对复杂问题的强大建模能力,而前向传播是其中最基本、最核心的计算过程。它不仅是模型训练的起点,也是模型推理的关键步骤。随着计算能力和数据规模的提升,前向传播在更深层
本周阅读了一篇关于使用GNN进行时间序列预测的论文。该论文模型的主要实现了在捕获时间序列不同尺度上的时间依赖关系外,还捕获了在不同尺度上变量之间的内部联系,例如空间上的依赖关系。同时还编写了论文提供的相关代码,了解了论文模型的定义。
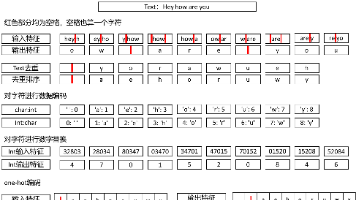
自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个分支,专注于使计算机能够理解、分析和生成人类自然语言的文本或语音数据。NLP致力于构建能够处理自然语言的智能系统,使计算机能够与人类进行自然而流畅的交流,而不仅仅是执行预定义的任务。以下是关于NLP的一些关键概念和应用:1. 文本分析:NLP技术可用于文本分析,包括文本分类、情感分析、主题建模和实体识
本文介绍了深度神经网络(DNN)的基本原理和实现流程。主要内容包括:1)DNN通过样本学习输入输出特征关系;2)实现步骤:数据生成(随机数X1-X3及对应Y1-Y3)、数据集划分(70%训练)、网络构建(4层全连接结构)、参数设置(MSE损失函数+SGD优化器);3)训练过程(1000次迭代)及测试结果(准确率约67%);4)模型保存与重载验证。所有操作均使用PyTorch在GPU上完成,并提供了
生成器的任务是从随机噪声中“创造”出一张看似真实的图片,而判别器则负责判别一张图片是真实的还是生成的。生成器和判别器之间展开了一场“智力博弈”:生成器不断提升生成图片的质量,试图骗过判别器。经过这种反复对抗的过程,生成器最终学会了生成极其逼真的图片。当我们用GAN 生成人脸时,一张随机噪声图片可以被看作是一组生成因子的组合,生成器将这些因子“转化”成一张人脸。当训练数据足够丰富时,生成器可以产生几
dnn
——dnn
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区


 AtomGit AI 社区
AtomGit AI 社区

 AMD开发者中国社区
AMD开发者中国社区
 AI Agent技术社区
AI Agent技术社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 DAMO开发者矩阵
DAMO开发者矩阵