




- @Zlyzjiabjw547479
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
思维链(CoT)是一种提升大语言模型推理能力的关键技术,通过引导模型展示逐步推理过程而非直接给出答案。文章介绍了CoT的核心原理(中间推理步骤、Few-shot/Zero-shot实现)、实际应用示例(数学问题、常识推理)及其优势(提升复杂任务表现、增强可解释性)。同时分析了CoT的局限性(任务适应性、模型依赖)和未来发展方向(自动提示工程、多模态CoT等)。文章建议开发者通过开源模型实践CoT技
强化学习(RL)的主流架构可分为基于价值(Value-Based)、基于策略(Policy-Based)、演员-评论家(Actor-Critic)和基于模型(Model-Based)四类。基于价值的方法(如DQN)通过优化Q函数间接推导策略;基于策略的方法(如PPO)直接学习策略函数,擅长连续动作和随机策略;演员-评论家架构(如A3C、SAC)结合两者优势,通过Actor生成动作、Critic评估
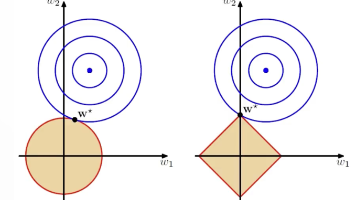
正则化:机器学习中的抗过拟合利器 正则化是机器学习中防止模型过拟合的核心技术。本文从过拟合问题切入,深入解析L1和L2两种正则化方法。L2正则化(Ridge)通过权重平方和惩罚项使参数趋近于零但不为零,适用于一般防过拟合场景;L1正则化(Lasso)采用绝对值惩罚项,能将不重要特征权重压缩至零,实现自动特征选择。二者关键区别在于:L1产生稀疏模型,适合特征选择;L2保持所有特征但缩小权重,更适合常
本文说明了二分类情况下Softmax函数与Sigmoid函数的等价性,或者说:Softmax函数可以认为是Sigmoid函数从二分类到多分类的推广。

强化学习(RL)的主流架构可分为基于价值(Value-Based)、基于策略(Policy-Based)、演员-评论家(Actor-Critic)和基于模型(Model-Based)四类。基于价值的方法(如DQN)通过优化Q函数间接推导策略;基于策略的方法(如PPO)直接学习策略函数,擅长连续动作和随机策略;演员-评论家架构(如A3C、SAC)结合两者优势,通过Actor生成动作、Critic评估
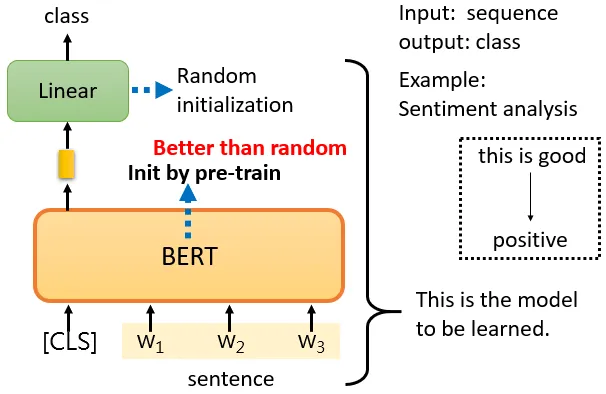
下游模型(Downstream Model)是指在预训练模型基础上,通过微调(Fine-tuning)或迁移学习方法,针对特定任务进行优化的模型。下游任务是指我们真正想要解决的具体应用任务,如文本分类、命名实体识别等。在自然语言处理领域,下游任务建立在预训练模型之上,利用预训练模型学习到的语言知识来解决特定问题。预训练模型通过大规模语料库学习通用语言表示,而下游任务则利用这些表示来解决具体应用场景
正则化:机器学习中的抗过拟合利器 正则化是机器学习中防止模型过拟合的核心技术。本文从过拟合问题切入,深入解析L1和L2两种正则化方法。L2正则化(Ridge)通过权重平方和惩罚项使参数趋近于零但不为零,适用于一般防过拟合场景;L1正则化(Lasso)采用绝对值惩罚项,能将不重要特征权重压缩至零,实现自动特征选择。二者关键区别在于:L1产生稀疏模型,适合特征选择;L2保持所有特征但缩小权重,更适合常
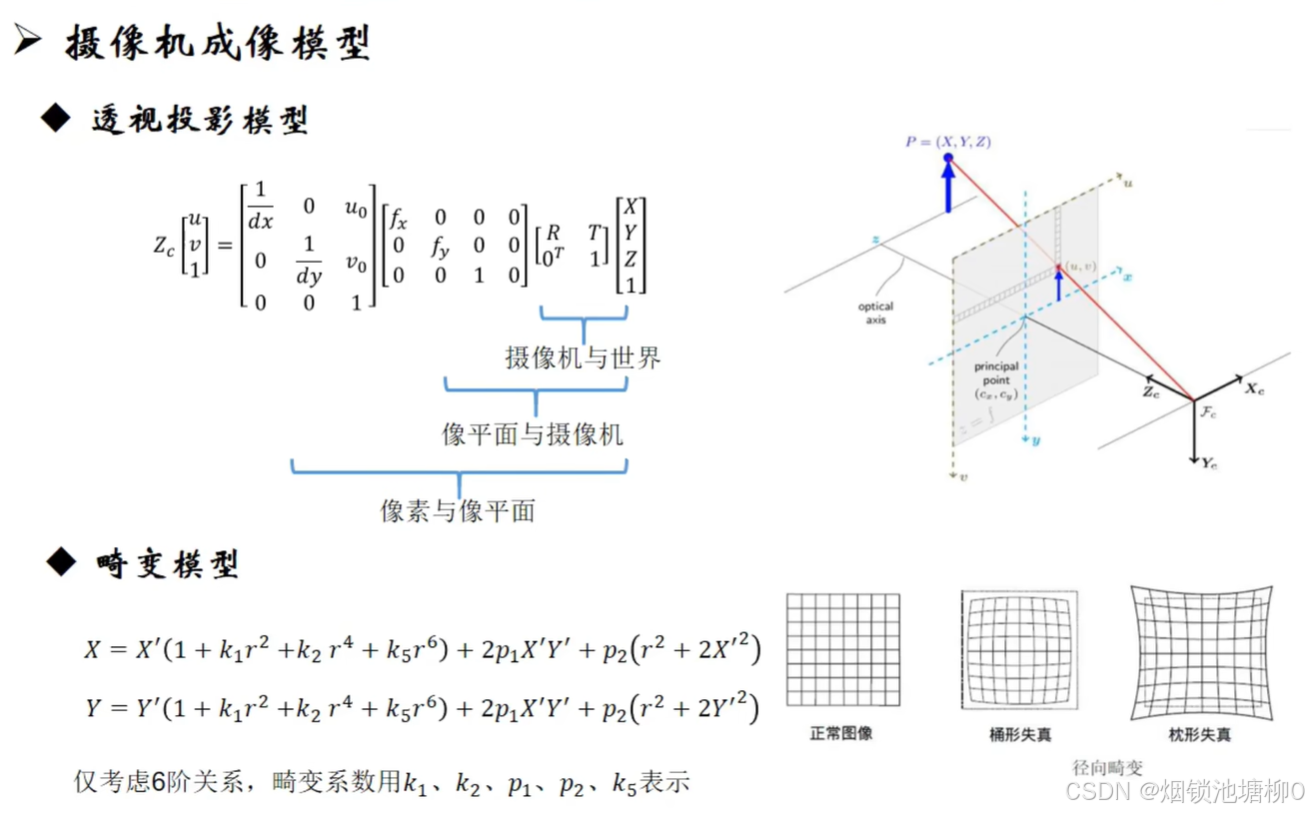
本文介绍了张正友标定法的原理,并循序渐进地介绍了针孔相机模型(透视投影模型)、相机畸变、相机的内方位元素(内参)和外方位元素(外参)、相机标定等前置知识。
本文系统梳理了内容创作领域的各类"GC"模式,包括UGC(用户生成内容)、PGC(专业生成内容)、PUGC(专业用户生成内容)、OGC(职业生成内容)、MGC(机器生成内容)、BGC(品牌生成内容)和AIGC(人工智能生成内容)。文章从创作者身份、生产方式、内容特点和典型案例等维度进行对比分析,揭示了从UGC到AIGC的内容生态演进路径。随着AI技术的发展,未来将呈现人机协同创
本文介绍了在数学建模领域常用的最大最小化模型。最大最小化模型是一种强大的决策算法,在博弈论、人工智能和多智能体系统中有广泛应用。通过理解其基本原理并掌握相关优化技术,我们可以开发出高效的对抗性决策系统。虽然最大最小化算法在计算复杂度方面存在挑战,但通过 Alpha-Beta 剪枝、深度限制和启发式评估等优化技术,可以显著提高其实用性。随着人工智能技术的发展,最大最小化模型及其变体将继续在各种应用场