




- @bjbz_cxy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目录概述一、什么是计算机视觉?二、计算机视觉实现起来难吗?1.外部噪声:2.内部噪声(分为四种):3.网络噪声4.根据特征切割场景重建二维图1. opencv还可以很好的修复图像中的畸变三.Opencv发展历程1.起源2.可移植性3.运行效率4.应用领域5.Opencv目标6.Opencv库组成体系(取自:学习Opencv图1-5)7. 版权8.预备四、什么是数字图像处理?它和计算机视觉的区别在哪
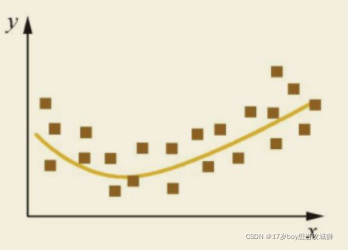
前言拟合从数学图像角度来说就是将一组平面图像上的点用平滑的曲线连接起来。在深度学习中平面图像上的点就是数据特征(验证集样本特征值),然后用线将已经学到的数据特征连接起来,这样才称为拟合。拟合也分三种:正确拟合、欠拟合、过拟合。正确拟合正确拟合是将样本特征学习的非常平滑,也就是学习到的样本与验证样本特征差距不大,经过算法学习样本特征值与验证集样本特征值差距并不大如下图是一个正确拟合的数据曲线图:从上
c++是基于c语言的扩展语言,本质上它继承了c语言许多特性,同时也继承了C语言特性,在c语言中stdio为输入输出缓冲区,stdin是输入缓冲区,stdout是输出缓冲区,C++不与C语言使用同一个缓冲区,这就出现了一个问题,当使用printfcouttest2test1可以看到test2早于test1输出了,这是因为c语言的机制,c语言缓冲区只有在遇到\n程序结束缓冲区满时才会刷新缓冲区。
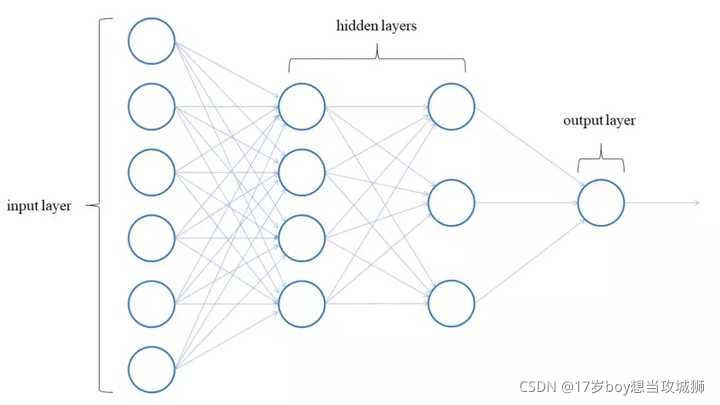
在神经网络中卷积是最常见的操作,通常情况下它应用在神经网络的Input层后面,所以我们多数情况下称这一层为卷积层或隐藏层,这里提一句什么是隐藏层,在神经网络中有输入层和输出层,这两层对于外界是可见的,并且它接收来自外界的输入或输出到外界里去,当然一个完整的神经网络不可能只有输入层和输出层,就以CNN卷积神经网络来说当图像输入到输入层之后会被传递给下一层做特征提取下一层一般是卷积层,随后卷积层会传递
前言Stm32 Cube MX是Stm32公司推出的一款专门为Stm32平台开发的IDE,通过它能够快速构建集成开发环境,与早期的STM32外设库相比,Cube MX更为简单,Cube MX做了更多层的封装,使的用户可以不用太关心MCU底层的实现,通过调用相关API即可完成工作,新手不建议直接使用它,新手可以先从最基本的GPIO口操作,在到外设库,然后在到Cube MX,否则你在开发过程中对底层硬
Token是什么?Token 是在服务端产生的。如果前端使用用户名/密码向服务端请求认证,服务端认证成功,那么在服务端会返回 Token 给前端。前端可以在每次请求的时候带上 Token 证明自己的合法地位。Token就是一个临时的牌子,用于验证身份的牌子,有了它用户就不需要每次访问网站时都输入账号与密码,用这个牌子就能证明你是这个网站的用户。GitHub添加ToKen方法首先进入你的Gitub,
目录概述一、什么是计算机视觉?二、计算机视觉实现起来难吗?1.外部噪声:2.内部噪声(分为四种):3.网络噪声4.根据特征切割场景重建二维图1. opencv还可以很好的修复图像中的畸变三.Opencv发展历程1.起源2.可移植性3.运行效率4.应用领域5.Opencv目标6.Opencv库组成体系(取自:学习Opencv图1-5)7. 版权8.预备四、什么是数字图像处理?它和计算机视觉的区别在哪
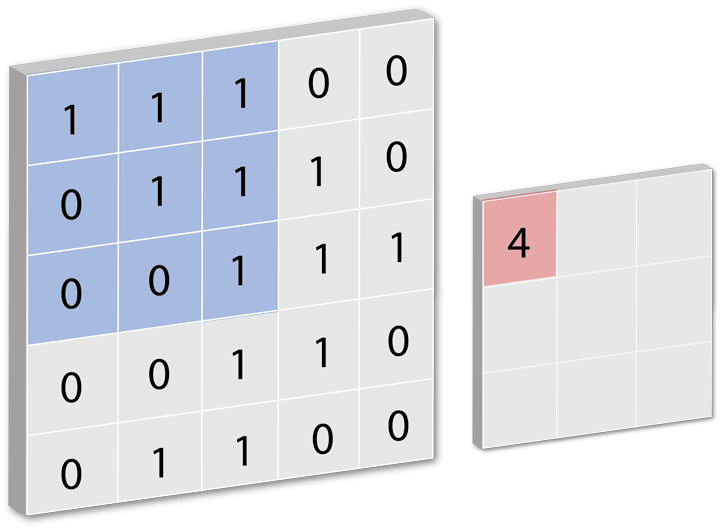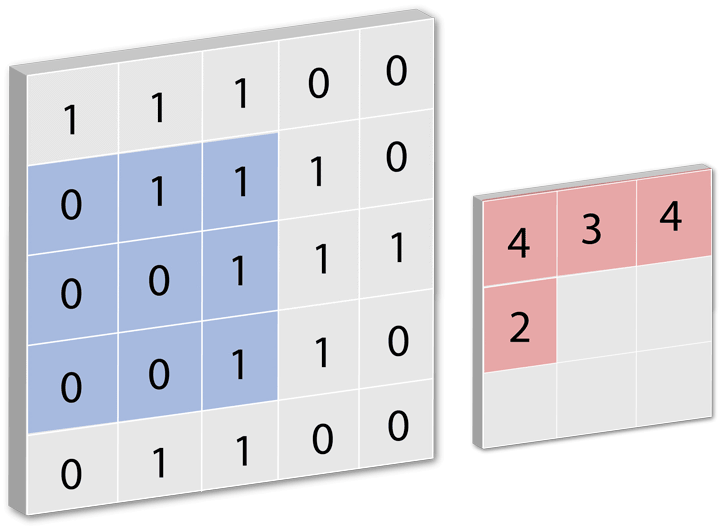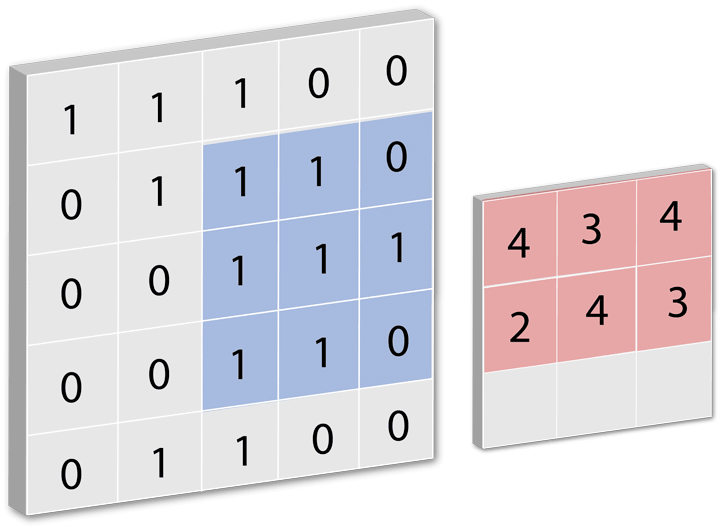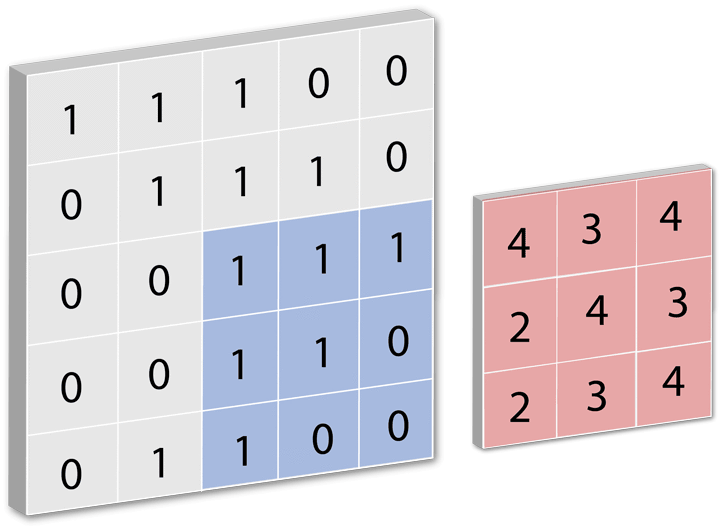
全连接层即:每一个节点都与上一层的节点相连,每个节点都视为一个特征点,当产生一个输入源后会对全连接层做卷积操作,卷积核多大取决于你的全连接层每层数据表有多大,全连接层里每一层都是一组数据,这组数据里包含了每次训练的结果,通俗易懂的说就是当输入一个数据后,对全连接层进行循环遍历的操作,每次遍历时对每层进行卷积运动若每层中有相似数据则记录为1,然后遍历完所有层后将所有记录值集合成一个值输出。下面用一个
前言拟合从数学图像角度来说就是将一组平面图像上的点用平滑的曲线连接起来。在深度学习中平面图像上的点就是数据特征(验证集样本特征值),然后用线将已经学到的数据特征连接起来,这样才称为拟合。拟合也分三种:正确拟合、欠拟合、过拟合。正确拟合正确拟合是将样本特征学习的非常平滑,也就是学习到的样本与验证样本特征差距不大,经过算法学习样本特征值与验证集样本特征值差距并不大如下图是一个正确拟合的数据曲线图:从上
前言拟合从数学图像角度来说就是将一组平面图像上的点用平滑的曲线连接起来。在深度学习中平面图像上的点就是数据特征(验证集样本特征值),然后用线将已经学到的数据特征连接起来,这样才称为拟合。拟合也分三种:正确拟合、欠拟合、过拟合。正确拟合正确拟合是将样本特征学习的非常平滑,也就是学习到的样本与验证样本特征差距不大,经过算法学习样本特征值与验证集样本特征值差距并不大如下图是一个正确拟合的数据曲线图:从上