- @weixin_45434953
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
P2P文件分发客户-服务器体系:极大的依赖与总是打开的基础设施服务器p2p体系:对总是打开的基础设施有着最小(甚至没有)的依赖P2P文件分发中,每个对等方能够向任何其他对等方重新分发他已经接收到的该文件的任何部分,从而从分发过程中协助该服务器目前最流行的P2P文件分发协议是BitTorrentP2P体系结构的扩展性传统的客户-服务器体系中,文件分发时间d会随着客户数量(接收方)的增加而线性增加。比
数据链路层中主要的数据单元是。报文(message)在数据链路层中被封装成帧然后传输。
和传统的神经网络不同,Generator除了接受x的输入之外,还会接受一个简单的分布作为z进行输入,从而使得网络的输出也是一个复杂的分布为什么输出需要时一个分布呢?以视频预测为例,比如说在糖豆人游戏中,我们需要预测视频的接下来的10帧是怎么样的问题是传统的神经网络(NN)训练出来的结果,在拐角处,一个糖豆人会分裂为两个糖豆人,一个向左一个向右,这是因为在普通NN中,糖豆人向左和向右都有可能,是概率

编译出来之后的U-Boot的文件结构及其作用如下:主要存放架构相关文件,存储着包括不同架构下不同CPU的内容,包括arm\x86等等。在存放着arm架构相关设置的文件夹arm下,(),包含着各个arm版本的设置文件夹,以及根本的ARM 芯片所使用的 u-boot 链接脚本文件u-boot.ldsboard 文件夹就是和具体的板子有关的,打开此文件夹,里面全是不同的板子,这是对开发板做的适配文件,本

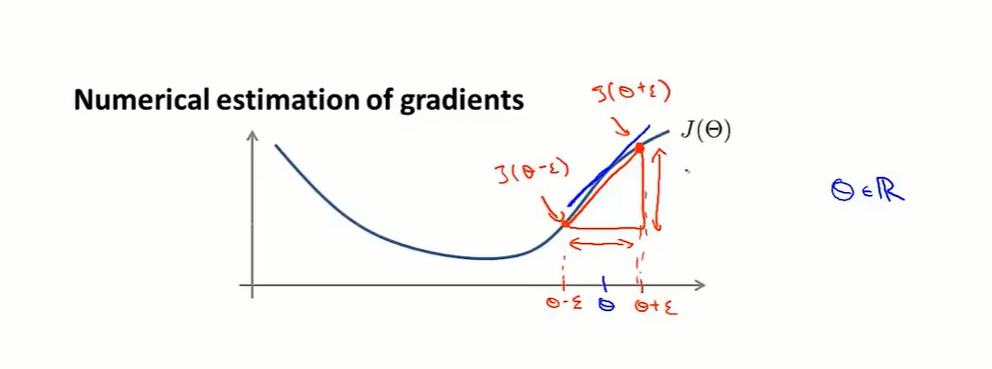
的取值是一个可行的方法,但是它很容易出错:因为在这个算法中含有海量的细节,容易产生微小而又难以察觉的bug。的方法赖解决这种问题,只要需要使用类似梯度下降或者反向传播的算法都可以使用这种方法,这种方法能够确保你的前向\反向传播完全正确。还是会照常迭代下降,但是得出来的结果的误差将会比正确的情况高出一个量级。,如果成立的话,则可以认为反向传播是正确的,把DVex用于梯度下降则可以得出较好的结果。是一
数据链路层中主要的数据单元是。报文(message)在数据链路层中被封装成帧然后传输。
设备树是是Linux中一种用于描述硬件配置的数据结构,它在系统启动时提供给内核,以便内核能够识别和配置硬件资源。设备树在嵌入式Linux系统中尤其重要,因为这些系统通常不具备标准的硬件配置,需要根据实际的硬件配置来动态配置内核。在Linux中,设备树源文件的扩展名为.dts,其二进制编码文件为.dtb,将.dts编译成.dtb需要使用DTC工具,位于Linux内核的文件夹下。

编译出来之后的U-Boot的文件结构及其作用如下:主要存放架构相关文件,存储着包括不同架构下不同CPU的内容,包括arm\x86等等。在存放着arm架构相关设置的文件夹arm下,(),包含着各个arm版本的设置文件夹,以及根本的ARM 芯片所使用的 u-boot 链接脚本文件u-boot.ldsboard 文件夹就是和具体的板子有关的,打开此文件夹,里面全是不同的板子,这是对开发板做的适配文件,本
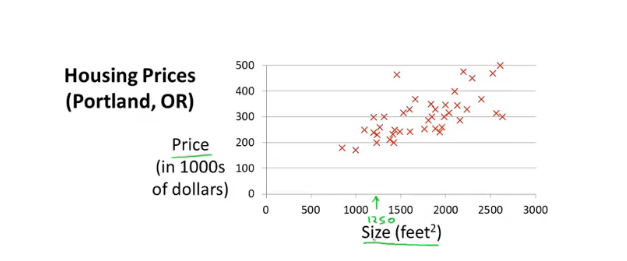
接下来我们将要学习我们的第一个模型——线性回归。比如说我需要根据数据预测某个面积的房子可以卖多少钱m:训练样本数量x:输入值,又称为属性值y:输出值,是我们需要的结果我们会用xy(x,y)xy表示一整个训练样本,使用xiyixiyi来表示第i个样例我们将上图用表格表示出来如下:那么线性回归的预测模型如下:训练集输入到学习算法中,然后学习算法会根据数据训练出函数h。作为一个线性回归模型,其输出的h应
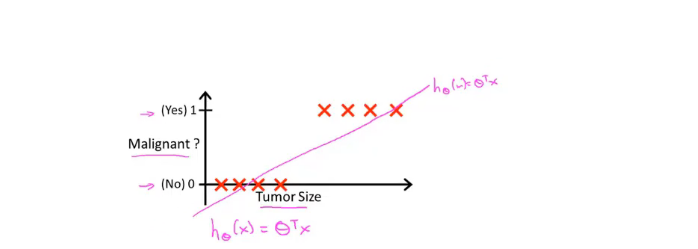
在阅读本文前,请确保你已经掌握代价函数、假设函数等常用机器学习术语,最好已经学习线性回归算法,前情提要可参考https://blog.csdn.net/weixin_45434953/article/details/130593910我们通常用y来表示分类结果,其中最简单y值集合为01,比如对于一个邮件是否为垃圾邮件,有“是垃圾邮件(1)”和“不是垃圾邮件(0)”两种y的取值。