




- @2401_84760719
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DeepSeek打爆全球,我们试试做片子怎样?本文将介绍如何运用DeepSeek 进行分镜写作、通过 Comfy UI 特别是 FLUX 工作流生图,以及利用可灵生成视频,同时确保整个过程中的一致性调教,打造出风格统一、令人惊叹的作品。

hello,大家好**今天我带来了一款专注电商写真摄影XL大模型——真境写真XL-vone,该模型是一款探索写真(摄影)方向的模型,在摄影写真上有较好的表现,适合工作流出图及写实重绘,更适合“电商”,“摄影”流使用,在服装及家居写实上融合了自用lora,有独特的优势。基于作者**“imaginruau”**描述,该模型属于融合模型,底膜采用主宰x,主宰v9,及老白的whitev10三个模型融合后再

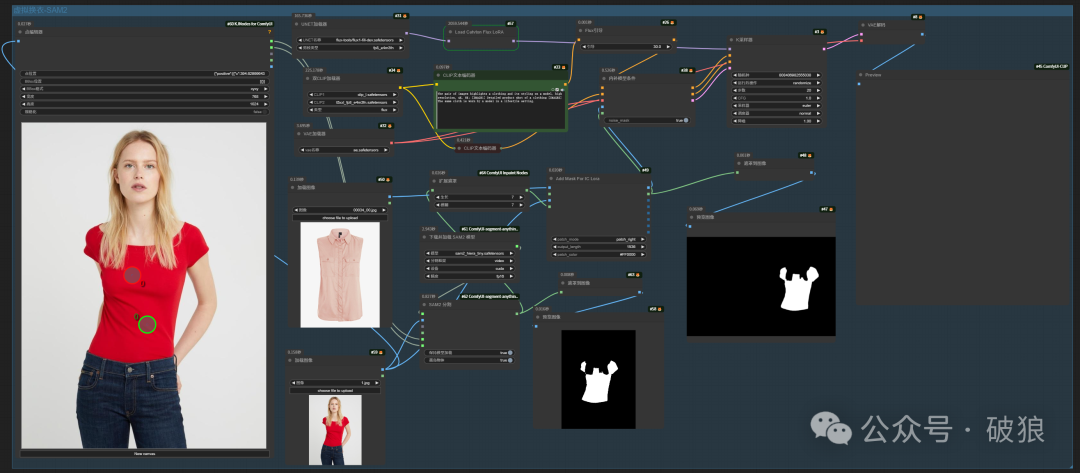
comfyui教程:今天文章给大家介绍一款最新的优秀的虚拟试穿解决方案,这是一款结合了的强大功能和Flux重绘修复模型,以实现真实且准确的衣物转移。同时解决方案还受到阿里In-Context LoRA提示工程的启发([阿里InContextLoRA:更强ID一致性!基于黑森林F1身份一致性连贯视频分镜图集,10组风格无限创意]
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,

Midjourney 和 Stable Diffusion 都是目前流行的 AI 图像生成工具,它们能够根据文本描述生成高质量的图像。都是基于深度学习技术的文本到图像生成模型,但它们各自基于不同的大模型。但最近推出了一款比前两者更强大,生成图像更加逼真,在细节上更符合现实世界的模型,就是FLUX!

Stable Diffusion是基于人工智能技术开发的绘画工具,用户可以根据任意文本输入生成高质量、高分辨率的逼真图像。目前Ai绘画火爆,不少用户咨询我们关于Ai绘画的配置要求和电脑配置方案,下面装机之家分享一下stable diffusion AI绘图电脑配置要求,顺便推荐几套组装电脑主机配置推荐。stable diffusion AI绘图配置要求CPU:intel 酷睿12代i3四核处理器;

本教程专为初学者设计,详细介绍了 2024 年最新版的SD ComfyUI的使用方法。通过逐步指导,让你无需任何基础,快速学会并使用这一强大的AI绘图工具。ComfyUI就像拥有一支神奇魔杖,可以轻松创造出令人惊叹的AI生成艺术。从本质上讲,ComfyUI是构建在Stable Diffusion之上的基于节点的图形用户界面(GUI),而Stable Diffusion是一种最先进的深度学习模型,可

共同研发的的网安视频教程,内容涵盖了入门必备的操作系统、计算机网络和编程语言等初级知识,而且包含了中级的各种渗透技术,并且还有后期的CTF对抗、区块链安全等高阶技术。汇编的核心是“寄存器”和“指令”——寄存器是CPU的“临时仓库”,指令是CPU的“操作命令”。Pwn核心逻辑:栈溢出漏洞,就是让“局部变量”的输入超出分配的内存空间,覆盖到“返回地址”——把返回地址改成我们想执行的代码地址,程序就会按

共同研发的的网安视频教程,内容涵盖了入门必备的操作系统、计算机网络和编程语言等初级知识,而且包含了中级的各种渗透技术,并且还有后期的CTF对抗、区块链安全等高阶技术。汇编的核心是“寄存器”和“指令”——寄存器是CPU的“临时仓库”,指令是CPU的“操作命令”。Pwn核心逻辑:栈溢出漏洞,就是让“局部变量”的输入超出分配的内存空间,覆盖到“返回地址”——把返回地址改成我们想执行的代码地址,程序就会按
对大学生来说,找副业最核心的需求是“时间灵活、门槛低、能兼顾学习、有长期成长”,而SRC漏洞挖掘正是完美契合这些需求的选择——无需编程基础、无需行业经验,利用课余时间就能上手,既能锻炼技术、丰富简历,还能通过提交漏洞获得现金奖励,月入1k-5k(新手水平),是大学生零基础切入网络安全领域、实现“边学边赚”的最优副业路径。声明:本文所有漏洞挖掘内容、工具使用、实操练习,均基于合法合规的授权场景(各厂
