- @HJS123456780
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在人工智能技术飞速发展的今天,大语言模型不再局限于对话问答,技术让大语言模型的能力边界不断拓展。(关于技术大家不了解的可阅读我的文章从0到1开发DeepSeek天气助手智能体——你以为大模型只会聊天?Function Calling让它“上天入地”然而,复杂的开发逻辑始终困扰着程序员和企业——如何让"聪明"的模型高效可靠地与外部世界进行交互呢?2024年底,由Anthropic(开发出Claude
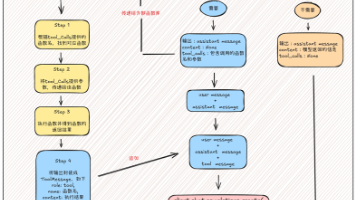
在本文中,我们探讨了 LoRA 微调方法,并以 StarCoder 模型的微调为例介绍了实践过程。通过实践过程的经验来为大家展示一些细节及需要注意的点,希望大家也能通过这种低资源高效微调方法微调出符合自己需求的模型。。
同时课程详细介绍了。
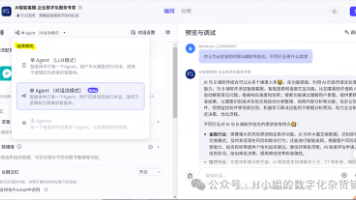
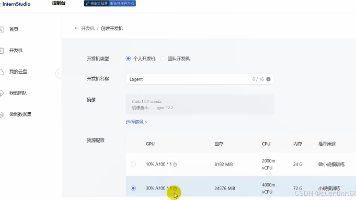
同时课程详细介绍了。

AI Agent代表了人工智能从"工具"向"助手"再到"代理"的进化过程,标志着AI正逐步从被动响应走向主动行动。随着技术的不断发展,AI Agent将在更多领域发挥作用,为人类提供更智能、更高效的服务。尽管AI Agent技术前景广阔,但我们也需要正视其面临的挑战,包括数据隐私、伦理问题以及技术可靠性等。未来的发展方向应是建立人机协作的模式,让AI Agent成为人类的得力助手,而非替代者。
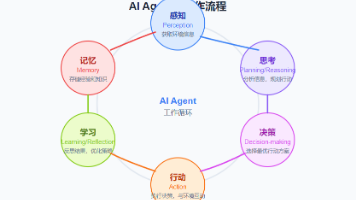
同时课程详细介绍了。
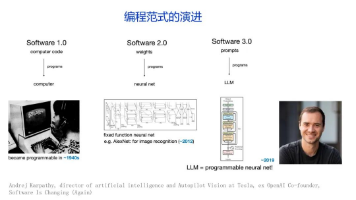
origin_url=.%2F(39%20%E5%B0%81%E7%A7%81%E4%BF%A1%20_%2089%20%E6%9D%A1%E6%B6%88%E6%81%AF&pos_id=img-j3HbTCH8-1761395904783) RAG、LangChain、Agent 到底有什么关系?有意思的是,系统检索了4个文档,发现有1个不太相关,自动触发了Web搜索补充。说实话,踩了不少坑,
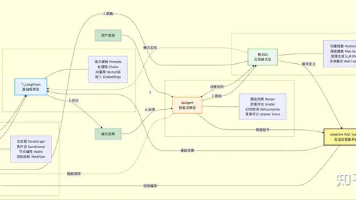
Agent 是一个能够自主感知环境、做出决策、执行动作并积累经验的闭环智能系统Agent = LLM(认知核心) + Memory(经验存储) + Tools(交互接口) + Planning(任务规划) + Action(执行引擎)自主性:无需持续人工干预即可完成设定目标环境交互:能感知外部信息并做出相应反应动态学习:通过记忆模块积累经验并优化行为目标导向:具备规划能力以实现复杂任务创建获取指定
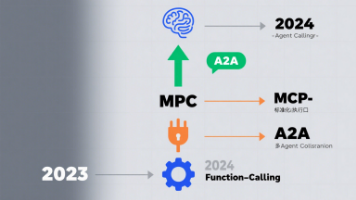
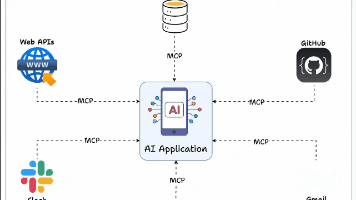
是一种面向AI Agent通信的轻量化协议,定义了统一的数据交换格式、消息调度策略以及连接管理机制。凌峰,博士,就职于985高校,长期从事机器学习、人工智能、计算机视觉及大语言模型方向的研发与教学工作。专注于模型优化、训练加速与数据驱动算法设计,具备扎实的理论基础与丰富的实践经验,主持及参与多项相关科研项目,致力于推动大模型及多模态技术在教学与产业中的落地应用。王伊凝,就职于中科院成果孵化企业,算