




- @z551646
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如何学习AI大模型?01引言你是否见过这样的场景?一段简单的指令输入,AI就能自动分析数据,撰写报告并发送邮件,像一位隐形助手般完成全套工作,比如最近比较火的AutoGPT,或者国内的Manus;在ChatGPT中安装“旅行规划”插件,只需要说“帮我订一个去杭州的机票和酒店”,那么他就会自动调用订票网站的接口,实时比价下单....这些看似科幻的背后,实际上是AI Agent(智能体)技术的爆发。为
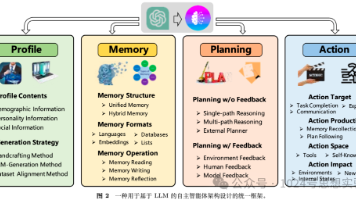
首先快速过一下基础概念。LLM Agent 不仅仅是能生成文本的大模型,它们更像是能自主决策、有记忆、会规划、还能调用外部工具(比如 API、数据库)来完成任务的智能系统。基础模型 (Foundation Model)提供核心的理解和推理能力;记忆系统 (Memory Systems)分短期和长期,保证对话连贯和知识积累;规划能力 (Planning)把复杂任务拆解成小步骤;工具使用 (Tool-
刚刚,AI大牛吴恩达官宣创业公司新成果——(Agent目标检测)。无需标注训练数据,模型就能在图片中定位指定物体。举个栗子,在一张长满草莓的图片中,提示词为“未成熟的草莓”,AI模型立马分分钟帮你找出。据吴恩达介绍,以前视觉AI要想识别物体,需要在大量标注数据上训练,而现在AI只需瞥一眼图片,短暂思考后(当前约20~30s)就能立刻输出正确内容。而的方法也令一众网友感到兴奋,未来应用潜力巨大。目前

是将接入层的元数据二次建模,以星型模型或雪花模型方式构建模型关联关系,此处可使用拖拽建模和自动建模两种方式完成维度建模。首先,维度建模将复杂的业务抽象,以数据明细表或轻度汇总表的方式描述业务数据,降低了数据使用的难度。然后,基于数据标准体系规范元数据定义,消除理解歧义,提高模型的分析效率和准确性。最后,将标准的维度模型转化为可执行的SQL脚本,并封装成数据服务,交由联邦查询计算引擎调用。
具身智能,英文Embodied AI,简称EAI, 依靠物理实体(如机器人、自动驾驶车辆等)与环境交互来实现智能增长的智能系统。在智能体与环境的交互过程中,通过感知、控制和自主学习来积累知识和技能,形成智能并影响物理世界的能力。其核心在于将感知、决策和执行紧密结合,主要挑战在于硬件性能、算法泛化能力与系统集成水平。

AI技术一路发展至今,推理优化是一个永存的话题,尤其是面临算力有限的情况下,如何将有限的计算资源利用最大化,是需要持续努力去实现的。今天我们来探讨一下大语言模型(LLM)推理缓存优化技术的演进和未来展望。本文主要进行原理性的探究,下一期会有相关的落地实践方案。缩略词解释LLM:大语言模型, Large Language ModelTTFT:首Token延迟, Time to First Token
本人是某双一流大学硕士生,也最近刚好准备参加 2024年秋招,在找大模型算法岗实习中,遇到了很多有意思的面试,所以将这些面试题记录下来,并分享给那些和我一样在为一份满意的offer努力着的小伙伴们!!!
本文介绍了如何通过`C#`结合`Ollama`实现本地大语言模型的部署与调用,重点演示了在`C#`应用中集成该功能的具体步骤。通过详细的安装指南与代码示例,帮助开发者快速上手。首先我们介绍了Ollama的安装及基本设置和命令的使用。然后介绍了如何通过Ollama调用大模型,比如使用命令行Http接口服务可视乎界面。再次我们我们通过C#使用了Ollama SDK来演示了对话模式文本嵌入多模态模型如何

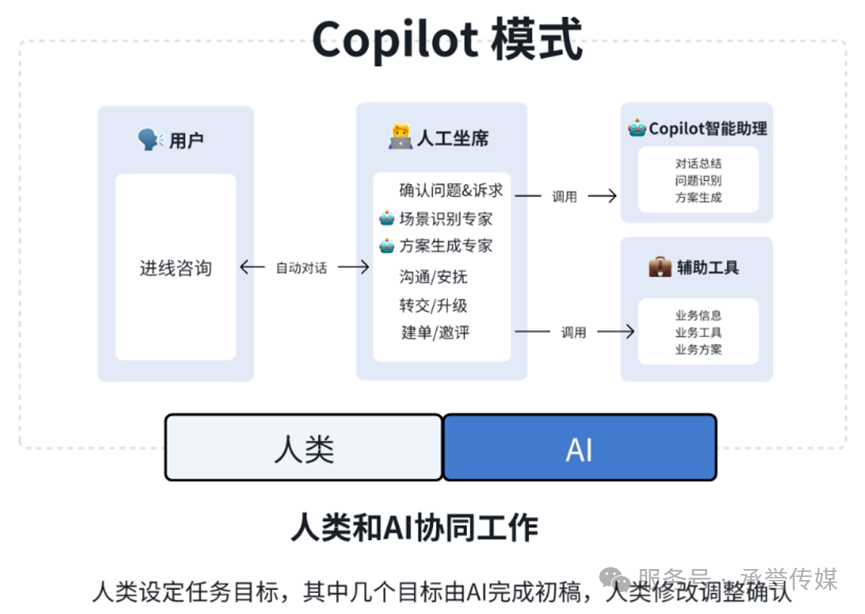
技术终将回归服务本质”——抖音电商的实践证明,AI客服不仅能降本增效,还能通过精准推荐、情绪共鸣提升用户体验。上Coze平台,用AI重构你的客服体系吧!
吴恩达教授开源了一个专注于翻译的 AI Agent——translation-agent。这个 translate-agent 主要以 AI 大模型为翻译引擎,再通过在工作流中增加一些针对性的建议和反思,辅以:提示词设定输出风格处理习语和特殊术语指定语言使用或方言等使之更易于翻译出比较符合当地语言的内容。今天在 Dify 中通过可视化工作流的方式来重现一下这个 AI Agent~Dify 是一款开
