




- @m0_71745258
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
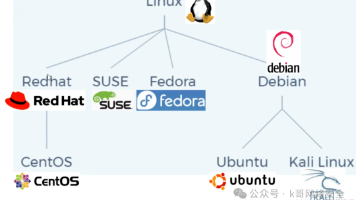
本文提供了2026版Kali Linux的详细安装教程,适合零基础用户。内容涵盖Kali Linux的基本介绍、起源及与Redhat系统的区别。重点讲解了下载方式(推荐Virtual Machines版本)、解压步骤以及使用VMWare打开镜像的具体操作。安装过程中需注意root密码修改指令(首次使用sudo passwd root)和XShell远程连接设置。教程提供了从官网获取镜像到成功启动虚
本文介绍了计算机专业学生值得参加的六大高含金量竞赛:ACM国际大学生程序设计竞赛(全球最具影响力的算法竞赛)、蓝桥杯(工信部主办的多项目比赛)、GPLT团队程序设计天梯赛(中国高校算法竞赛)、中国大学生计算机设计大赛(教育部认可的综合类竞赛)。这些比赛不仅能提升技术能力,还能获得奖金、保研加分和就业优势。文章详细说明了各竞赛的主办方、参赛要求、赛程安排和奖项设置,为计算机专业学生提供了有价值的参赛

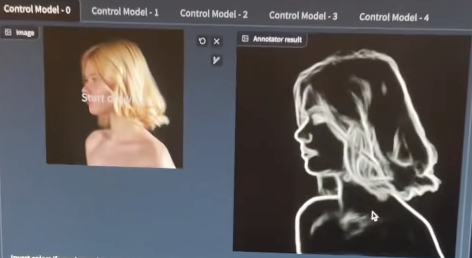
通过Stable-Diffusion结合ControlNet插件,我们可以得到一幅新的图像,该图像结合了两幅原始图像的特点,既具有内容图像的内容,又具有风格图像的风格。图像风格迁移也可以应用于其他的领域,比如电影、游戏、虚拟现实和动画创作等等。
无独有偶,OpenAI 的一位参与模型行为工作的人员在 X 上发推表示,团队正在逐渐删除 ChatGPT 上面那些恼人的"敏感检测"橙色提示,并向广大用户征集,还有那些讨人厌的敏感检测是大家希望去掉的。知乎从一个小众精英社区扩充到全民知识平台,逐渐失去了"垂类专业精英"的光环,取而代之的是"人在美国刚下飞机"的哀伤和"分享你刚编的段子"的无奈。这是最坏的时代,也是最好的时代。

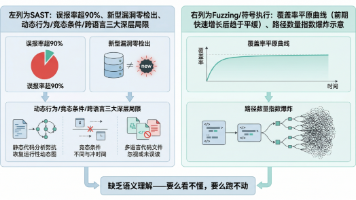
回到最初的问题:为什么大模型能做漏洞挖掘?从三个场景的分析中,可以看到一条清晰的线索。三个场景按可用信息量递减排列,大模型介入的方式也随之改变。在白盒场景下,模型面对的是完整的、人类可读的源代码,它的核心任务是在已有语义的基础上做深层安全推理,即追踪跨文件数据流、推演异常状态组合、发现深层逻辑缺陷。这里的进化方向很直接:模型越强、上下文越长、安全推理越深,效果就越好。框架在简化,模型能力在驱动一切
120万次代码提交,10561个高危漏洞——这不是某安全公司的年度报告,而是OpenAI新工具上线几天的成绩单。OpenAI 于 3 月 6 日发布 Codex Security,一个能自动扫描代码库、发现并修复安全漏洞的 AI 工具。它不是简单的模式匹配,而是能理解代码上下文、在沙箱中验证漏洞、按真实影响排序,误报率比传统工具降低了 50% 以上。
Claude Mythos Preview[1]新型的通用大模型的出现,无疑是对计算机安全领域的一枚重磅炸弹。Anthropic 明确表示:这是一个“不是让一个大模型直接“判断有没有漏洞”,而是让多个 Agent 围绕“证据、假设、验证、闭环”持续推进,直到得到可复现、可解释、可报告的漏洞结果。结合Claude Mythos Preview的核心思想,打算对当前的漏洞挖掘多agent系统先做一次架

故事要从 Anthropic 内部的安全评估和一个叫 CyberGym 的东西说起。2025 年底,Opus 4.5 在 CyberGym 上已经接近满分了。这里 CyberGym 是 UC Berkeley 搞的一个大规模网络安全评估框架,包含1507 个测试用例,来自188 个主流开源项目的真实漏洞。AI 拿到漏洞描述和未修补的代码库,要自己写出 PoC(概念验证)exploit 来复现漏洞。

先看看AI输出的漏洞审计报告,准确率基本达到80%,如果没有企业会员可以去闲鱼购买一个。
2025年计算机专业就业趋势及热门方向分析 在数字化浪潮下,计算机类专业已成为就业市场的"黄金赛道"。当前呈现两大趋势:AI岗位需求激增(80%技术岗要求AI能力,平均年薪40万+),传统开发岗位缩减30%。文章深度解析十大热门专业方向,包括:计算机科学与技术(25-60万年薪)、人工智能(50-120万年薪)、网络安全(行业缺口200万)、数据科学(起薪15-25万)等。特别
