- @m0_71745754
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
短视频时代,AI工具已经成为设计师和视频创作者的“神助攻”!尤其是像DeepSeek这样的AI平台,凭借其强大的AI创作能力,正在改变全行业创作的面貌。今天,我们将通过一个实际案例——制作一个在抖音投放的短视频,来分享如何利用DeepSeek + comfy UI + 可灵,高效产出AI视频内容。从分镜设计到生图咒语优化,再到视频生成与后期合成,更先进的AI工具能够帮助我们提升效率,释放更多创意空

如图片过大被平台压缩导致看不清的话,点击**CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享**视频配套资料&国内外网安书籍、文档&工具当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。一些我自己买的、其他平台白嫖不到的视频教程:需要的话可以点击**CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享**
要想做好UX测试,我们必须先去了解产品是怎样设计产品的,知道了正确的交互设计是什么样的我们才能更好的提出问题(即从根本原因去寻找问题)。日常工作中我们会做一些用户体验测试(UX测试),把我们自己当做用户去体验产品,通常会对界面是否简洁美观、文案是否正确、界面按钮布局是否合理、操作上的交互是否友好及使用感受上不易操作等等地方进行测试。这是最简单的用户体验测试,要想真正的UX测试这远远是不够的。虽说这
这个过程就像是雕刻:原始噪声图就像是雕刻的原料,去噪的过程就像是用雕刻刀去除废料,最后生成的图片就像是雕刻成型的作品。一个节点包含不同的数据和控件,节点通常包含入口和出口,不同的节点相互连接,就组成了工作流,可以实现特定的任务。所谓文生图,就是根据想要的画面,输入画面上的元素、风格等词汇(正向提示词),同时输入不希望画面出现的元素(负向提示词),Comfyui经过一系列流程,生成一幅画面。这个节点
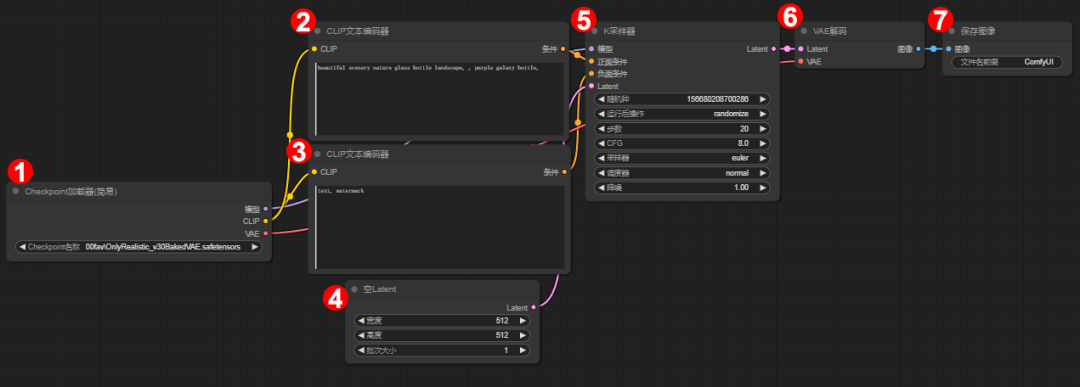
ComfyUI 是一个开源的、基于节点的程序,主要用来根据提示词生成图像。它利用诸如 Stable Diffusion 这样的免费扩散模型作为基础,通过图形用户界面(GUI)让用户能够以一种更加直观和灵活的方式操作和管理图像生成的过程。工作原理ComfyUI 基于节点架构运作,界面元素被表示为相互连接的节点。每个节点都封装了特定的功能或行为,通过调整模块连接可以达到不同的出图效果。用户可以通过连接
1.FLUX大模型本身就可以生成高质量、风格一致人物图片的大模型。2.推荐使用麦橘超然majicFlus大模型,人物风格更自然,更加一致3.提示词比较重要,如”A 6-grid photo”,这样才能生成6宫格的图片。为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了。

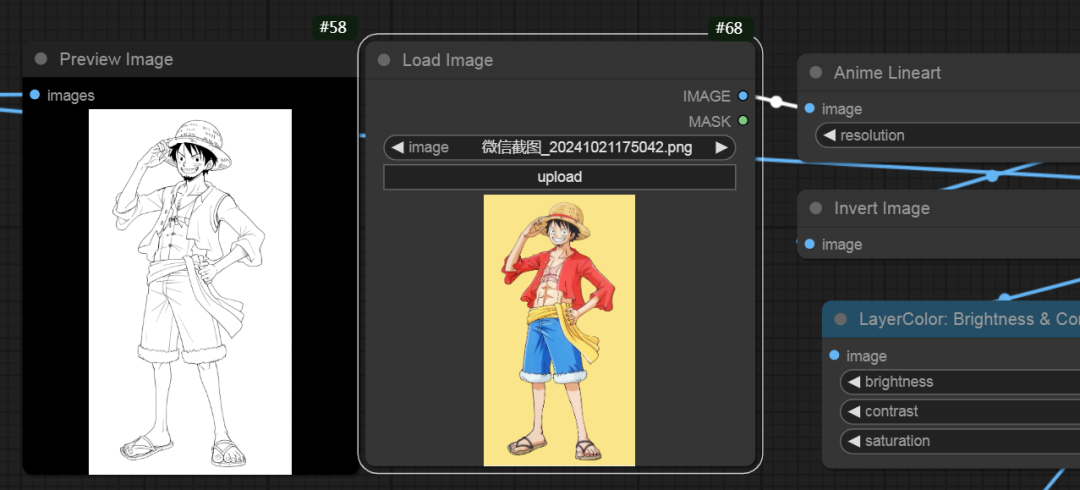
得益于AI技术的进步,图像处理的难度日益降低,特别是在动漫与插画风格的设计领域。我要向大家介绍一个既简单又高效的ComfyUI工作流程——图像转线稿工作流程(Anyline结合MistoLine)。此流程能够迅速将照片转化为动漫风格的线条图,同时保留其艺术韵味与可调节性,无需繁琐的步骤,极为适合创意专业人士及爱好者采纳。此工作流程的精髓在于AnimeLineArt动漫艺术线条预处理模块,它负责处理
在当今数字化的浪潮汹涌澎湃之际,人工智能技术正以令人瞠目结舌的速度迅猛发展,犹如一场席卷全球的科技风暴,为各个领域带来了前所未有的深刻变革。其中,ComfyUI 宛如一颗璀璨的新星,在这浩瀚的科技星空中熠熠生辉,它作为一款极具创新性的工具,正逐渐崭露头角,为创意的生成和实现开辟了一条崭新而充满无限可能的道路。这个工具凭借其超快的图像生成速度、流畅的操作体验,尤其是对低配置设备的友好支持,迅速在创作

LORA模型非常的多,很多的特效实现都是基于LORA来实现的。所以SD绘图要想制作非常优秀的图片,LOAR的使用是必须要掌握的内容。但是LORA很多时候都是拿来即用的,所以更多时候需要我们去尝试去使用体验,在具体场景使用哪些模型对应的哪些LORA,充分积累我们使用LORA解决问题的经验。拿到指南书的小伙伴们赶紧炼丹起来吧。

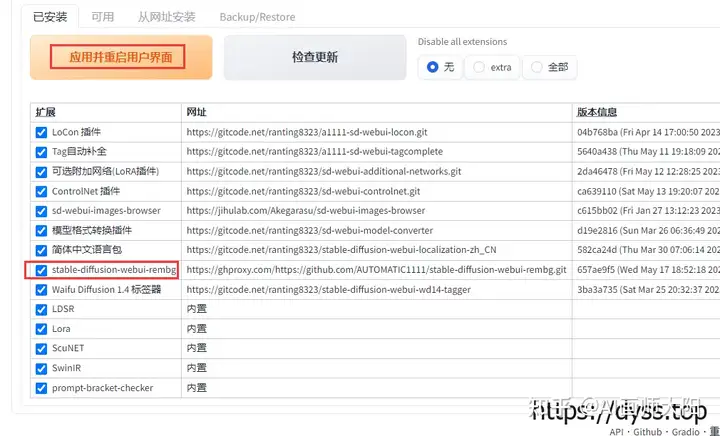
以前我们抠图要么用抠图网站要么就用PS自己扣,要么花钱要么就是慢,现在AI功能很强大,我们可以使用stable diffusion插件stable-diffusion-webui-rembg实现图片一键快速抠图,省时省力效果还很不错。下面演示一下具体操作。首先打开stable diffusion webui界面,如果没有安装sd的话,可以stable diffusion安装,查看具体安装教程。