




- @2401_84830464
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

当你去学习一个新的东西,你需要先了解这个东西是什么,然后再去学习会更加简单,那什么是SD呢,stable diffusion是一款基于人工智能技术开发的绘画软件,最原始的stablediffusion 是基于命令行参数进行运行的,类似这样的,对于没有编程基础的小白玩家,学习AI绘画之前还要命令行参数,甚至还要记住各种参数的涵义stable-diffusion 命令行界面:

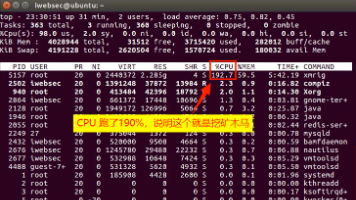
应急响应_挖矿木马_网络安全管理_木马查杀_挖矿木马处置_安全应急演练_木马排查_服务器挖矿木马_网安应急处理_木马实战教程_安全运维_病毒防范_恶意程序检测_网络安全入门_主机安全防护_木马清除方法_应急响应流程_企业安全运维_恶意木马分析_安全事件处置
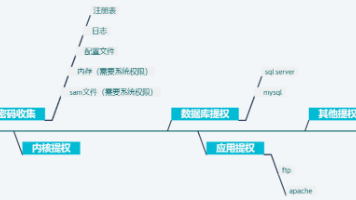
Windows 提权_系统提权_提权教程_权限提升_Windows 安全_网络安全_零基础入门_渗透实战_提权技术_系统权限_渗透教程_黑客技术_内网渗透_安全攻防_系统漏洞_提权方法_Windows 渗透_安全教程_入门到精通_渗透技巧
自学黑客_黑客学习步骤_网络安全自学_零基础入门_黑客技术_渗透测试_网络安全教程_新手学黑客_安全入门_漏洞挖掘_内网渗透_Web 安全_自学教程_全干货_网络安全学习_黑客入门_安全攻防_实战学习_零基础学安全_渗透学习

内网渗透_渗透学习_黑客技术_零基础入门_内网渗透教程_网络安全_渗透测试_内网攻防_实战教程_域渗透_横向移动_权限提升_信息收集_代理隧道_权限维持_痕迹清理_零基础学渗透_网络安全入门_渗透实战_内网安全
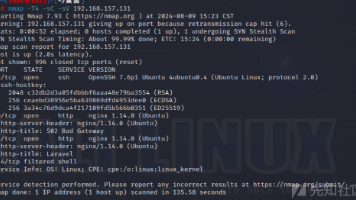
渗透测试_零基础入门_渗透测试是什么_渗透测试方法_渗透测试流程_渗透测试工具_白盒测试_黑盒测试_双盲测试_开灯测试_网络安全_漏洞扫描_安全测试_渗透测试步骤_渗透测试优势_渗透测试教程_渗透测试学习_内部安全测试_外部渗透测试_渗透测试实战
Kali Linux 工具_渗透测试工具_黑客工具_网络安全_零基础入门_黑客技术_渗透测试_Kali 教程_网络安全入门_漏洞挖掘_Web 渗透_内网渗透_信息收集_密码破解_漏洞扫描_流量分析_无线渗透_安全攻防_实战工具_零基础学黑客
