




- @Liudef06
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出了一种基于大语言模型(LLM)的LoRA训练集自动化评估框架,通过多模态技术解决传统人工评估效率低、主观性强的问题。该框架整合图像描述生成(BLIP模型)、视觉特征提取(CLIP模型)和元数据分析,构建四大核心评估维度:内容相关性、视觉一致性、样本多样性及技术质量。系统采用模块化设计,首先通过深度学习模型处理图像数据,再结合精心设计的提示工程,利用LLM进行综合质量评分并生成改进建议。实验

DeepSeek-V3.1与R1对比测评摘要(150字) DeepSeek-V3.1相比R1版本实现三大突破:1)创新混合推理架构,单模型支持思考/非思考双模式,通过动态门控机制切换;2)思维链压缩技术减少20-50%冗余输出,保持同等推理质量;3)编程智能体能力显著提升,SWE-bench测试通过率提高15%。评测显示,V3.1在数学推理(GSM8K 92.5%→94.1%)、代码生成(Huma
AI海报设计工具Qwen-Image技术解析与应用指南 本文系统介绍了如何利用通义千问多模态模型Qwen-Image实现专业级海报设计。主要内容包括: 技术架构:解析Qwen-Image基于Transformer的视觉-语言对齐机制,包含图像编码器与文本解码器的协同工作流程 环境配置:详细说明硬件需求、Python依赖安装及模型初始化方法,提供完整的代码实现 设计原理:结合视觉层次、对比原则等设计

AI重塑企业应用:DeepSeek R1大模型落地实践 DeepSeek R1作为国产领先大语言模型,正通过三大核心技术推动企业智能化转型:1)参数高效微调(PEFT)技术,包括LoRA和QLoRA,实现千亿参数模型的轻量化适配;2)结构化提示词工程(CRISP框架)与思维链优化,显著提升任务准确率;3)多模态能力在工业质检、零售推荐等场景的实践应用。文章提供了完整的微调代码示例和行业数据增强方案

苹果在WWDC25上发布的Swift 6带来了开发生态的系统级革新。该版本通过三大核心突破重构全平台开发:1)革命性并发模型,引入编译时数据竞争检测和完全内存安全保证;2)强大的宏编程系统,支持类型安全的编译时代码生成和DSL构建;3)全面提升的跨平台能力,实现单一代码库无缝部署到iOS/macOS/watchOS等全平台。这些改进显著降低了并发编程复杂度,提高了代码安全性和开发效率,同时通过统一
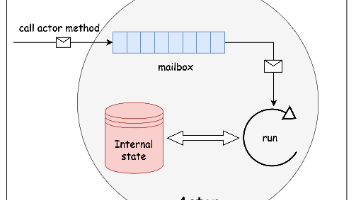
图生图技术正彻底改变视觉内容创作方式。本文深入探讨了生成式AI如何通过深度学习实现从文字到图像的精准转换。文章首先概述了图生图技术的发展历程,从早期自编码器到现代扩散模型,展示了技术演进的里程碑。随后重点解析了扩散模型的核心原理,包括前向噪声添加和反向去噪过程,以及通过交叉注意力实现的条件控制机制。技术实现部分提供了PyTorch代码示例,演示了噪声调度和多头注意力计算等关键环节。这些突破性技术正
构建下一代AI开发环境:Python与HTML打造轻量级AI IDE 本文介绍了一种基于Python和HTML构建轻量级AI集成开发环境的方法。通过前后端分离架构,采用HTML5/CSS3/JavaScript实现响应式前端界面,后端使用Python Flask框架处理AI计算任务。关键技术选型包括Monaco Editor作为代码编辑器、Bootstrap 5构建UI组件、WebSocket实现
摘要 本文介绍了一种基于 DeepSeek V3.1 的智能工具开发方案,用于自动推导数列通项公式并生成结构化 JSON 结果。文章详细阐述了系统架构设计、JSON 数据结构、API 调用策略以及实现步骤。该工具利用 DeepSeek V3.1 强大的数学推理能力,能够识别数列模式、推导通项公式并提供详细的推导过程和相关知识点。通过斐波那契数列等示例,展示了如何将复杂的数学推理过程封装为标准的 J

本文介绍了一个基于SpringBoot和DeepSeek V3.2 API构建的论文解析工具,能够自动提取学术论文关键信息并输出标准化JSON数据。该系统采用分层架构设计,支持批量处理、数据标准化和容错重试机制,利用DeepSeek V3.2的混合推理架构和成本优势处理复杂论文内容。文章详细讲解了项目配置、技术栈选型(包括Spring AI集成)以及核心功能实现,如领域模型设计和API调用参数设置

摘要: MiniMax-M2模型的发布为RAG系统带来重大突破。本文详细介绍了基于这一全球领先开源模型构建企业级检索增强生成系统的完整方案,包括其128K上下文支持、动态Interleaved Thinking能力和卓越的经济效益。文章剖析了传统RAG系统的局限,提出融合安全防护、自适应检索和事后验证的现代架构,并提供从环境配置到安全防护层的具体实现代码。该系统特别强化了企业级需求如PII保护、访
