




- @text2203
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在当前的电商领域,呈现高质量的服装图像对于吸引客户和提升销量至关重要。ComfyUI工作流提供了一种高效的解决方案,使电商平台能够通过AI技术快速为模特换装,展示多种服装。以下是使用ComfyUI工作流进行模特换装的详细指南,包括如何使用最新技术来改善电商模特的试穿体验和服装展示。

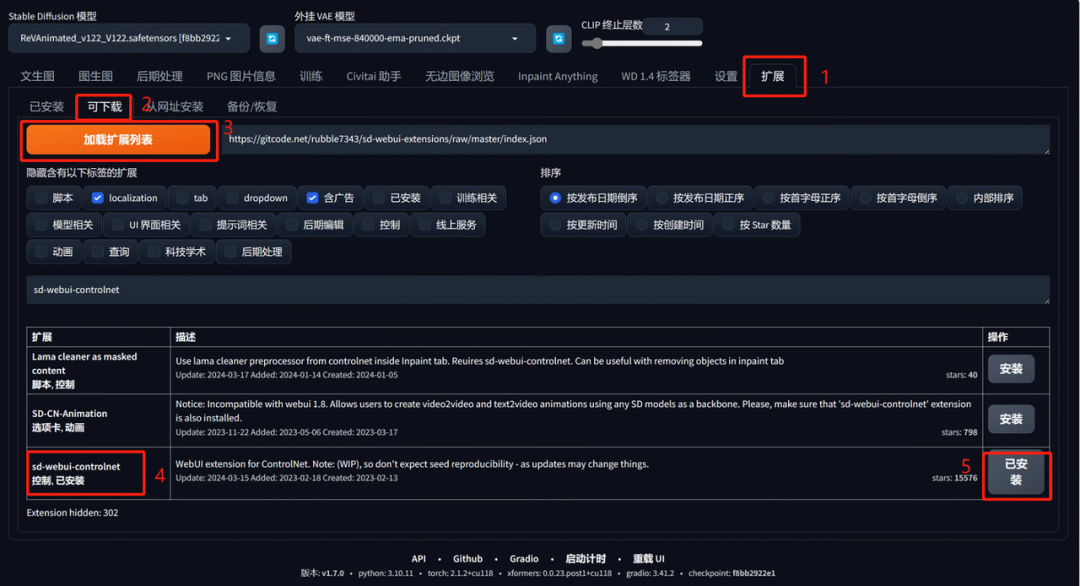
ControlNet是一种强大的SD webui插件,它通过神经网络模型来实现对生成图像的精确控制。当然,它本身的应用远不止与此,ControlNet 在许多领域中都具有广泛的应用,包括艺术创作、图像修复、虚拟场景生成等等。在传统的图像生成任务中,我们通常使用提示词(prompt)来引导模型生成特定类型的图像。通过输入适当的提示词,我们可以约束模型生成与提示词相关的图像内容。然而,只使用提示词来引

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。感兴趣的小伙伴,赠送
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,
SD全套资料,包括汉化安装包、常用模型、插件、关键词提示手册、视频教程等都已经打包好了,无偿分享,有需要的小伙伴可以自取。感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智

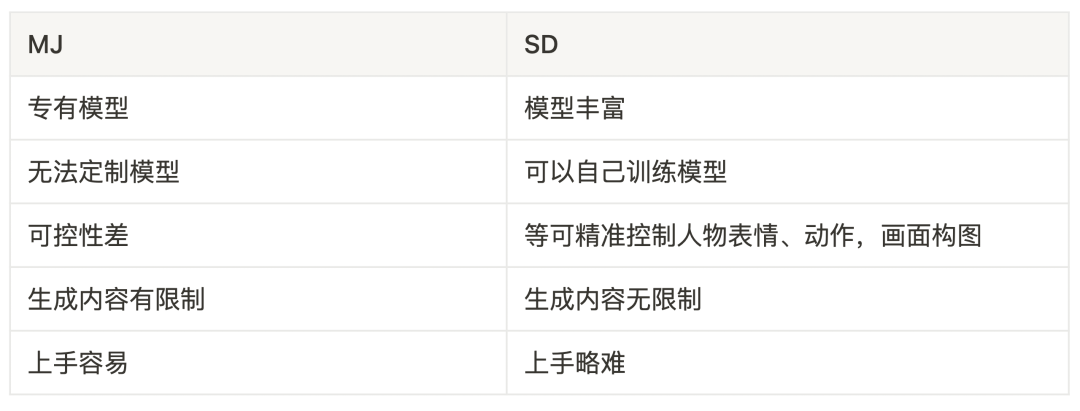
Stable Diffusion凭借其卓越的图生图功能,极大地提升了图像生成的可控性与输出品质,赋予用户前所未有的个性化创作风格表达能力。这一革新特性使得Stable Diffusion不仅能精准地捕捉用户的艺术愿景,更能以数字化手段孕育出新颖且极具创意的画作。本篇教程将深入剖析图生图的原理,聚焦于Stable Diffusion的图生图AI绘画技巧,助力您在创作独特数字艺术作品时拓宽灵感源泉,精
ControlNet是一种辅助式的神经网络模型结构,它的主要作用是在Stable Diffusion模型中引入额外的条件控制,以更精细地控制AI绘画的生成过程。ControlNet通过在Stable Diffusion模型的基础上添加辅助模块,复制出两个相同的部分:一个是“锁定”副本,另一个是“可训练”副本。ControlNet主要在“可训练”副本上施加控制条件,然后将施加控制条件后的结果与原始S
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。感兴趣的小伙伴,赠送
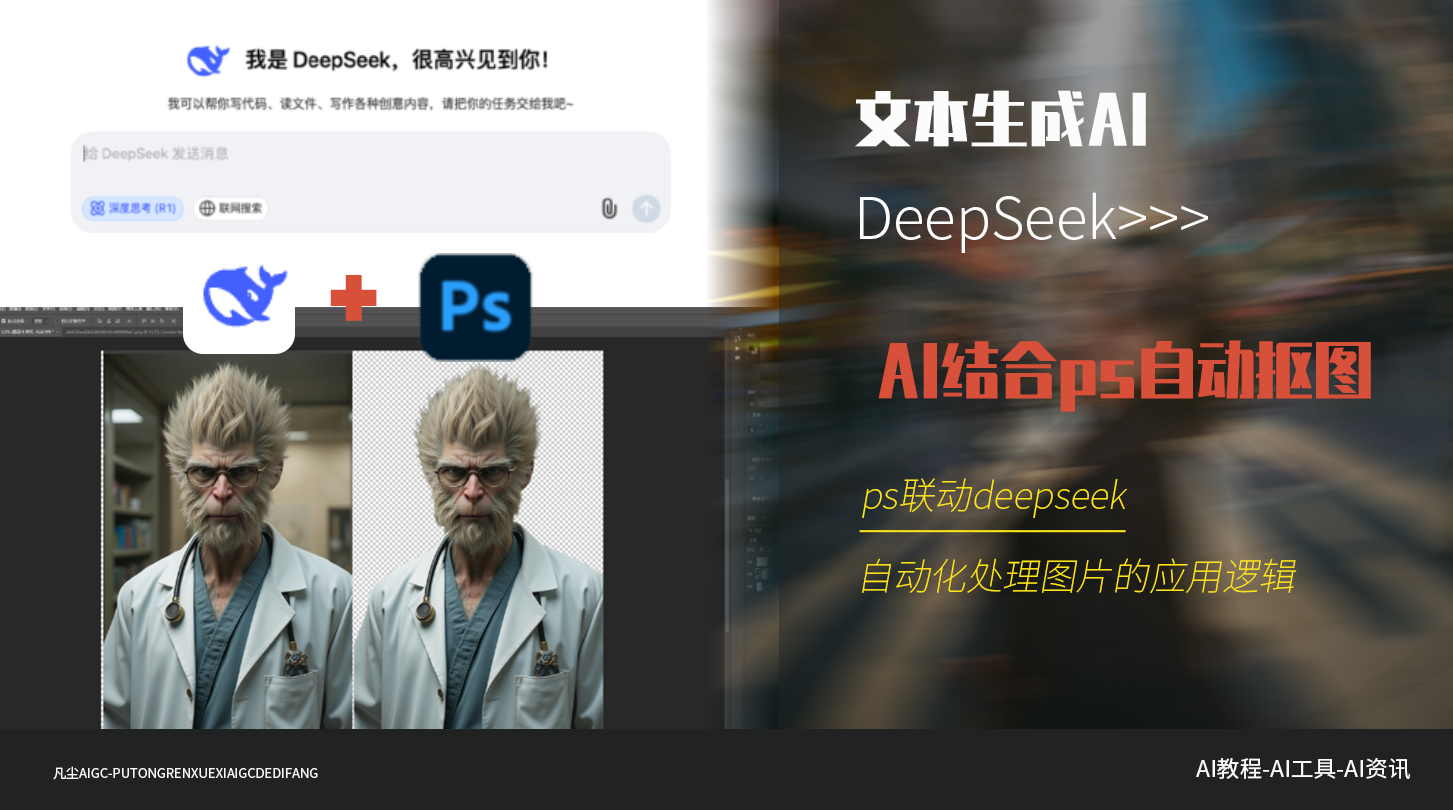
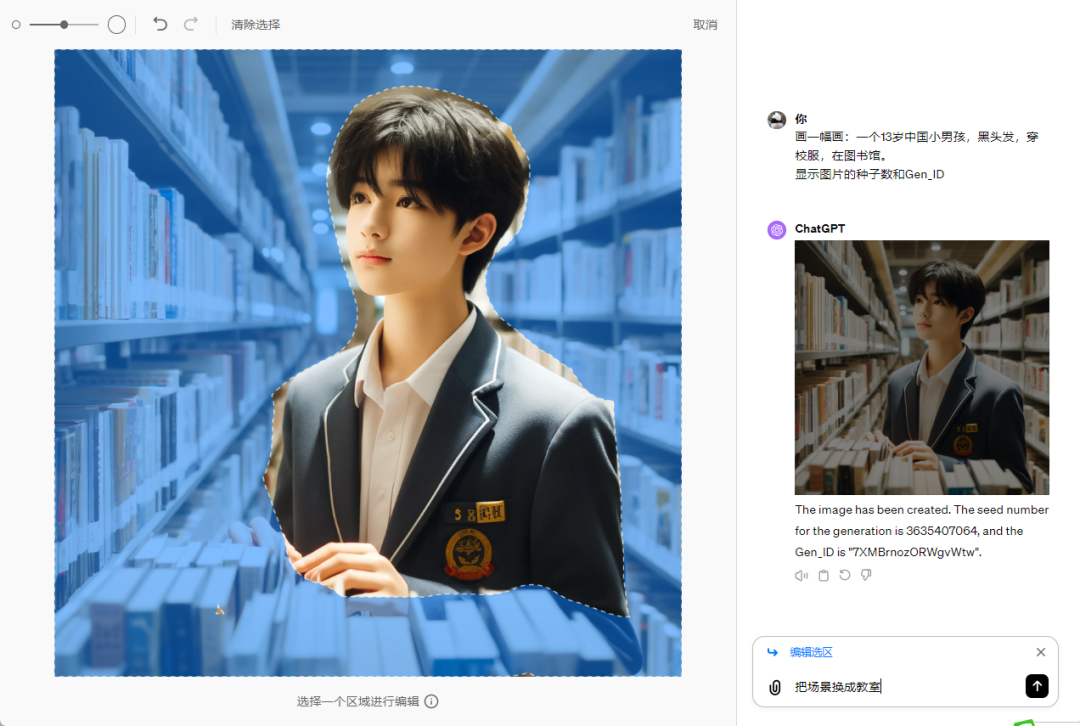
短视频时代,AI工具已经成为设计师和视频创作者的“神助攻”!尤其是像DeepSeek这样的AI平台,凭借其强大的AI创作能力,正在改变全行业创作的面貌。今天,我们将通过一个实际案例——制作一个在抖音投放的短视频,来分享如何利用DeepSeek + comfy UI + 可灵,高效产出AI视频内容。从分镜设计到生图咒语优化,再到视频生成与后期合成,更先进的AI工具能够帮助我们提升效率,释放更多创意空

本文向大家介绍了图像生成领域最前沿的Stable Diffusion模型。本质上Stable Diffusion属于潜在扩散模型(Latent Diffusion Model)。潜在扩散模型在生成细节丰富的不同背景的高分辨率图像方面非常稳健,同时还保留了图像的语义结构。因此,潜在扩散模型是图像生成即深度学习领域的一项重大进步。Stable Diffusion只是将潜在扩散模型应用于高分辨率图像,同
