




- @m0_68036862
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
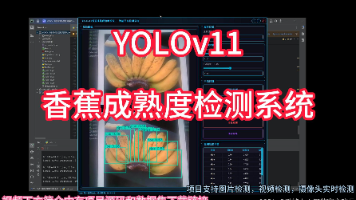
本项目开发了一套基于深度学习YOLOv11算法的香蕉成熟度自动识别检测系统,能够高效准确地识别香蕉的6种成熟度状态。系统整合了先进的计算机视觉技术、用户友好的UI界面以及完善的用户管理功能,为香蕉种植、仓储、物流和零售环节提供智能化的成熟度检测解决方案。
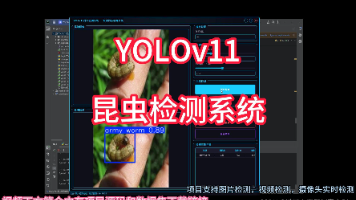
本项目基于YOLOv11深度学习模型,开发了一个高效的昆虫识别检测系统,能够自动识别10类常见农业害虫,包括army worm(黏虫)、legume blister beetle(豆芫菁)、red spider(红蜘蛛)等。系统采用PyTorch框架实现,并配备了用户友好的UI界面,支持登录注册功能,便于用户管理和使用。
本项目基于YOLOv11深度学习算法,开发了一套高效、实时的疲劳驾驶检测系统,能够准确识别驾驶员的疲劳状态,包括打哈欠(Yawn)、闭眼(close)、无哈欠(noYawn)和睁眼(open)四种关键行为。系统采用Python实现,并集成用户友好的UI界面,支持登录注册功能,便于多用户管理和数据记录。

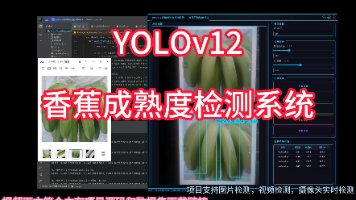
本项目基于YOLOv12深度学习算法,开发了一套高效、精准的香蕉成熟度智能识别检测系统。系统能够自动检测并分类香蕉的6种成熟状态,包括新鲜成熟(freshripe)、新鲜未熟(freshunripe)、过熟(overripe)、成熟(ripe)、腐烂(rotten)和未熟(unripe),可广泛应用于农产品质量检测、智能分拣、仓储管理及零售业商品品质控制等领域。
该系统创新性地集成YOLOv8、YOLOv10、YOLOv11和YOLOv12四种最新目标检测模型,专门针对"火焰(fire)"和"烟雾(smoke)"两类关键火情特征进行高精度识别。系统采用SpringBoot框架构建后端服务,结合前后端分离架构,实现了多模态火情检测功能(包括静态图像、动态视频流和实时监控摄像头),并将所有检测记录与用户数据持久化存储于MySQL数据库。为增强系统智能化水平,我

本文设计并实现了一个集成了最新多版本YOLO目标检测算法与SpringBoot后端框架的生菜生长周期智能检测与分析系统。针对现代农业中对作物生长状态自动化、精细化监控的需求,系统以生菜水培为典型场景,构建了包含‘Ready’(可采收)、‘empty_pod’(空定植篮)、‘germination’(发芽期)、‘pod’(定植篮)、‘young’(幼苗期)五类生长阶段的专属图像数据集,共计1410张

本文设计并实现了一个基于深度学习的数字多目标检测与识别系统。系统采用前后端分离架构,后端基于SpringBoot框架,前端采用现代化Web技术提供交互式界面,并利用MySQL数据库进行数据持久化管理。在核心识别算法上,系统创新性地集成并对比了当前最先进的YOLO系列目标检测模型(包括YOLOv8、YOLOv10、YOLOv11和YOLOv12),并针对数字识别的特点构建了涵盖0-9十个类别的专用数

本文详细介绍了一套功能完整、技术先进的“基于深度学习的安全帽佩戴识别检测系统”。该系统旨在解决工业生产、建筑工地、电力巡检等高风险场景下的人员安全监管难题。系统核心采用当下最前沿的YOLO系列目标检测模型(集成YOLOv8、YOLOv10、YOLOv11及YOLOv12),实现了对“安全帽”(helmet)和“头部”(head,即未佩戴安全帽)两类目标的高精度、实时检测。项目不仅构建了强大的算法后

本项目旨在设计并实现一个高效、精准、用户友好的无人机自动识别与综合管理系统。系统核心采用当前最前沿的YOLOv8/YOLOv10/YOLOv11/YOLOv12目标检测算法,构建了一个高性能的无人机检测模型。项目创新性地集成了DeepSeek大型语言模型的智能分析能力,赋予系统对检测结果的语义理解和生成式描述功能。系统架构采用前后端分离的现代化设计模式,后端使用Spring Boot等框架构建稳健

随着中国传统智力游戏数字化发展的深入推进,麻将作为极具代表性的国粹文化,其智能化识别与分析技术具有重要的应用价值。本研究设计并实现了一套基于深度学习与现代化Web架构的麻将牌智能识别系统,专门针对42种标准麻将牌型进行高精度检测与分类。系统创新性地集成了YOLOv8、YOLOv10、YOLOv11和YOLOv12四种先进的目标检测模型,构建了可灵活切换的多模型识别引擎。通过构建包含6731张高质量
