登录社区云,与社区用户共同成长
邀请您加入社区
这类 Markdown Skill 是“提示型技能”,不会执行外部命令或暴露工具调用;需要真实工具能力时仍建议实现。当某个 Skill 被选中时,它的工具会进入 LLM tools,,避免多个 MCP Server 之间的工具名冲突。当该 Skill 被选中时,Markdown 正文会注入系统提示。、目录中的 Markdown Skill、以及外部 MCP Server 暴露的工具。每轮都会重新计
通过上述策略的组合运用,动态路由能够将大语言模型调用成本显著降低。企业可根据自身流量模式(如简单请求占比 )和业务目标,定制路由规则,在保障关键业务效果的同时,实现总体成本的最优控制。
BeeQuant通过智能核心BeeAgent降低量化交易门槛,用户只需用自然语言描述交易思路,AI即可自动生成完整策略。平台支持可视化调整、多维数据融合和主流AI模型调用,特别擅长代币化美股策略开发。提供从回测到实盘的一站式闭环服务,并构建策略分享生态,让普通投资者无需编程基础也能实现专业量化交易。
是一个基于Flask框架的扩展库,专门用于实现实时通讯。传统的HTTP协议是“请求-响应”模式,服务器只能在客户端请求后进行响应,而WebSocket可以让服务器主动推送数据给客户端,实现双向实时通信。Flask-SocketIO不仅支持WebSocket,还支持长轮询等多种通信方式,它会自动选择最佳方式,不用我们手动配置。除了message,我们可以定义更多自定义事件,帮助实现更细化的实时功能。
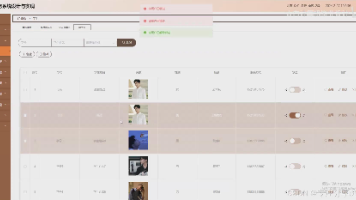
普通用户、贡献用户、管理员三类群体,提供差异化服务。普通用户能浏览非遗资讯、参与交流论坛;贡献用户除基础操作外,还可进行举报反馈;管理员则拥有全方位管理权限,从非遗项目、活动的审核管理.............
平台覆盖了化妆、发型设计、穿搭技巧、护肤知识、健身指导、摄影艺术以及多样化的技能学习等多个方面...............
PYblogbackend:Flask API 服务(统一提供公开接口、管理接口、小程序接口)frontend:博客前台站点(面向读者)admin:后台管理系统(面向管理员):微信小程序端(面向移动端微信用户)低门槛搭建完整博客体系(内容、分类、标签、评论、留言)支持后台可视化管理(文章编辑、配置管理、媒体上传)支持移动端和微信场景(微信登录、激励解锁隐藏正文)
的完整步骤 + 代码 + 接口文档 + 页面代码!
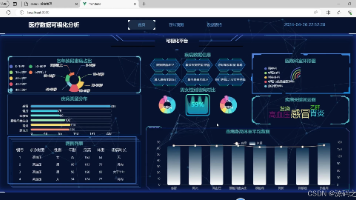
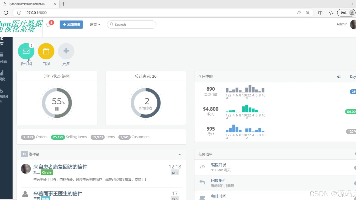
本文介绍了一个基于Python的医疗数据分析与预测系统,采用Flask+Vue+MySQL技术栈,集成随机森林算法实现疾病预测。系统包含四大功能模块:1)可视化大屏展示患病占比、疾病分布、科室数据等图表;2)基于随机森林的病情在线预测功能;3)病例数据表格展示与搜索;4)后台数据管理模块支持增删改查。项目解决了医疗行业数据整合困难、决策支持不足等问题,通过数据可视化与智能预测提升医疗数据分析效率。
异步编程是一条充满挑战但回报丰厚的技术路径。在 9 年的 Python 后端开发生涯中,我见证了异步编程从边缘技术到主流选择的转变,也亲身经历了无数个深夜调试异步 bug 的痛苦时刻。但正是这些经历,让我深刻理解了计算机科学的本质——一切性能优化,最终都是对有限资源的更高效利用。asyncio 不是银弹,它只是我们工具箱中的一件强大工具。真正决定系统性能的,是我们对问题本质的理解和对技术细节的把控
注意:实际开发中需根据团队技术栈调整框架选择,例如Django可替代Flask提供更完整的Admin后台。数据库工具:Navicat for mysql。开发软件:PyCharm/vscode。框架:flask/django。数据库 mysql 版本不限。前端开发框架:vue.js。开发语言:Python。
基于Flask框架的农村养殖管理系统旨在解决传统养殖业信息化程度低、管理效率不足的问题。系统采用B/S架构,前端使用Vue.js实现动态交互界面,后端基于Python的Flask框架开发,数据库选用MySQL存储养殖数据。系统设计遵循模块化原则,涵盖用户管理、养殖档案、饲料管理、疾病防控、销售记录等核心功能模块。用户管理模块实现多角色权限控制,区分管理员、养殖户和兽医等角色,确保数据安全与操作合规
高校比赛服务系统作为数字化校园建设的重要组成部分,旨在为学生、教师和管理员提供高效的比赛信息发布、报名、评审及结果查询服务。基于Python的Django和Flask框架,设计并实现了一套功能完善、扩展性强的高校比赛服务系统。系统采用B/S架构,结合MySQL数据库,实现了前后端分离开发模式,提升了系统的可维护性和用户体验。系统核心功能模块包括比赛信息管理、在线报名、评审管理、成绩查询和通知推送。
本文介绍了一个基于Python Flask框架的医疗数据可视化系统。系统采用Echarts实现数据可视化,包含六大功能模块:首页数据概览、患者信息管理、医疗数据可视化、患者信息添加、医疗工作安排和疾病关联分析。核心功能包括通过图表展示患者数据趋势、表格管理患者信息、日历管理医疗事务以及关系网络分析疾病关联。系统后端使用Flask处理请求,前端结合HTML和Echarts实现交互式可视化,旨在帮助医
本文介绍了一个基于Python的医疗数据可视化系统,采用Flask框架和Echarts技术栈开发。系统包含六大功能模块:首页数据概况展示关键指标与待办事项;患者数据管理支持搜索与状态标记;医疗数据可视化通过多种图表呈现患者分布与趋势;添加患者信息表单实现便捷录入;医疗工作安排提供日历视图管理;疾病关联分析利用网络图揭示患者间关系。该系统帮助医护人员直观分析医疗数据,优化决策与工作流程,提升医疗服务
本文介绍了一个基于Python的医疗数据可视化系统,采用Flask框架、Echarts和HTML技术栈开发。系统包含六大功能模块:首页数据概况展示关键指标图表、患者数据管理表格、医疗数据可视化分析图表、患者信息添加表单、医疗工作安排日历以及疾病关联分析网络图。通过数据采集、处理与可视化,帮助医护人员高效分析病历、诊断和治疗信息,发现潜在健康问题,预测病情趋势,优化医疗决策和服务质量。系统提供完整的
本文介绍了一个基于Python Flask框架开发的医疗数据可视化系统。系统采用Echarts实现数据可视化,包含六大功能模块:首页数据概况展示关键指标、患者数据管理表格、医疗数据可视化分析(折线图/饼图等)、患者信息添加表单、医疗工作日程安排日历、疾病关联分析网络图。系统通过多种图表形式帮助医护人员直观分析患者数据变化趋势、分布特征及关联规律,提升医疗决策效率。后端使用Flask处理请求,前端结
Python三大Web框架对比:Django、Flask和FastAPI各有特色。Django是"大而全"的全栈框架,适合复杂后台开发;Flask轻量灵活,适合小型项目和快速原型;FastAPI专为高性能API设计,支持异步并自动生成文档。选择依据:Django适合电商/CMS等复杂系统,Flask适合小型应用/学习,FastAPI适合高并发API服务。初学者可从FastAPI入门,再逐步掌握其他
花了一整天踩完所有坑,写了这份指南。面向新手,每一步都有解释,跟着操作就能上线。
今天,我们要探讨的不是普通的“重启大法”,而是Azure如何利用其深厚的PaaS与SRE(站点可靠性工程)能力,赋予Java应用一种近乎科幻的“自愈能力”。我们将深入Azure App Service的自动修复规则、Azure Spring Apps的熔断机制以及Application Insights的智能洞察,通过硬核的Java代码与Azure配置,看看如何让应用具备“自我手术”的能力。但在云
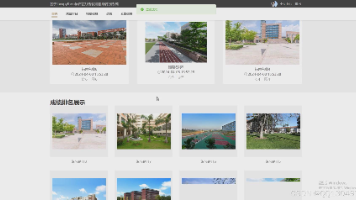
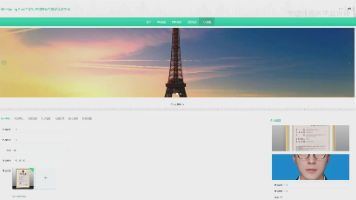
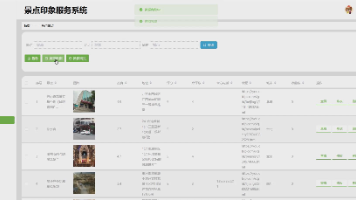
Flask Python旅游景点印象服务系统是一个基于Flask框架开发的Web应用,旨在为用户提供景点信息浏览、印象分享、评论互动等功能。系统通过轻量级的Flask后端实现数据管理,结合前端技术展示动态内容,适合作为学习Flask开发或旅游类应用的实践项目。
flask
——flask
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 龙虾开发者社区
龙虾开发者社区

 MCP技术社区
MCP技术社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区