




- @unique_zhao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
第三十九届美国人工智能协会(AAAI)人工智能大会于2025年2月25日至3月4日在宾夕法尼亚州费城举行。程序委员会主席为Julie Shah(美国麻省理工学院)和Zico Kolter(美国卡内基梅隆大学)。本次会议的范围涵盖机器学习、自然语言处理、计算机视觉、数据挖掘、多智能体系统、知识表示、人机协作人工智能、搜索、规划、推理、机器人与感知,以及伦理道德。除了专注于上述任一领域的基础研究工作外
深度学习开源视觉库对比,包含paddle,mmlab,detectron、huggingface等

使用深度学习模型推理,即使使用gpu,前几个批次也会格外的慢,使用预热来解决

利用这些强大的先验,我们开发了 DEEPTalk,这是一个会说话的头部生成器,它可以非自回归地预测码本索引以创建动态的面部运动,并结合了一种新的情绪一致性损失。广泛的实验表明,我们的方法获得了最先进的结果,保留了源身份,保持了细粒度的面部细节,并以非常高的准确性捕捉了细微的面部表情。此策略可增强 GAN 训练的稳定性,并确保生成的全身手势的表现力。例如,由于音频信号相对较弱,仅由音频驱动的方法有时

深度学习开源视觉库对比,包含paddle,mmlab,detectron、huggingface等
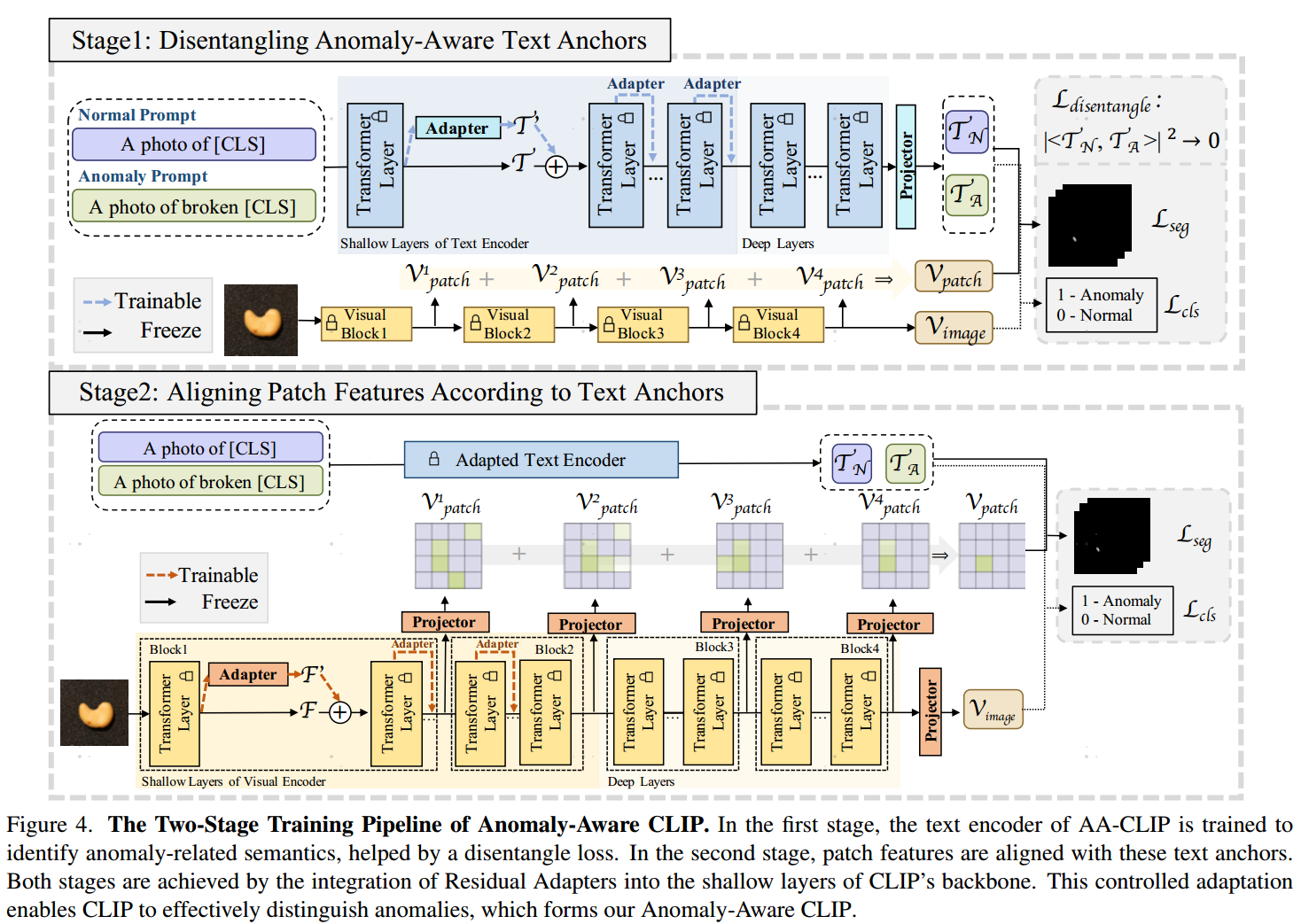
文章的核心在于原始的CLIP由于关注通用能力,缺乏对异常的感知,所以作者通过提升了文本分支对normal和abnormal的区分,提升了CLIP对异常的识别能力
简单总结本文的动机就是,transformer得益于自然语言的成功才被尝试用在视觉上,而在自然语言中,基于自监督预训练在transformer上取得了很大的成功(比如BERT),那在transformer用在视觉上是不是也可以用自监督取得好的效果呢?一、主要解决的问题ViT在视觉任务中的局限性监督学习下的Vision Transformer(ViT)相比卷积网络(ConvNets)尚未展现明显优势

工业质检领域,尤其是基于图像的工业缺陷检测领域,缺陷样本的收集可能非常困难,也就促生了无监督异常检测与zero-shot检测的研究方向,他们都不需要目标场景下的缺陷样本,因此大家可能会对他们的概念和具体使用场景存在疑问。因此本文重点对这两个任务进行介绍和对比。

torch转onnx中问题的解决思路,设计interpolate算子,instance norm, grid sampler

深度学习开源视觉库对比,包含paddle,mmlab,detectron、huggingface等