




- @lady_mumu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
算子融合优化的核心洞察是:深度学习模型的推理瓶颈往往在显存带宽而非计算能力。通过将多个细粒度操作编译为单个融合内核,可以减少内核启动开销和中间结果的HBM往返次数,从而实现显著的加速。工程落地上有三个层级的选择:(1) 使用+Inductor的自动融合——零代码改动,适合快速验证和通用场景;(2) 使用FlashAttention等第三方优化库——在attention等关键路径上获得手工优化的极致
LlamaIndex和LangChain在RAG领域的竞争反映了两种工程哲学的分歧:数据索引视角 vs. 链式组合视角。LlamaIndex的优势在于文档处理的开箱即用性(语义分割、多样化检索后处理)和数据资产的持久化管理。LangChain的优势在于管道的可组合性和灵活性(每个组件可替换)。在实际项目中,两者并非互斥——可以在LlamaIndex中管理索引,在LangChain中编排Agent逻
高并发大模型在线推理的工程痛点在于消灭由于低批次带来的 GPU 算力严重空转以及前/后处理造成的 CPU 串行阻塞。Triton Inference Server 凭借其高性能的 C++ 异步调度引擎,在运行时利用动态批处理(Dynamic Batching)与滑动排队延时机制,在毫秒级内实现了请求的高效合并与 Tensor Core 计算饱和;同时,其多模型管道(Ensemble)技术,成功将多

Python 性能优化应遵循"测量优先"原则,用性能分析工具定位瓶颈后再针对性优化。四层优化策略(算法→向量化→内存→编译)按投入产出比排序,应从低层向高层逐步尝试。向量化是投入产出比最高的优化手段,能将循环开销下沉到 C 层;Numba 适合纯数值计算的热点函数;多进程适用于计算密集且 GIL 受限的场景。每次优化都需验证收益并评估可读性代价,避免过早优化与过度优化。建议在项目中建立性能基准测试
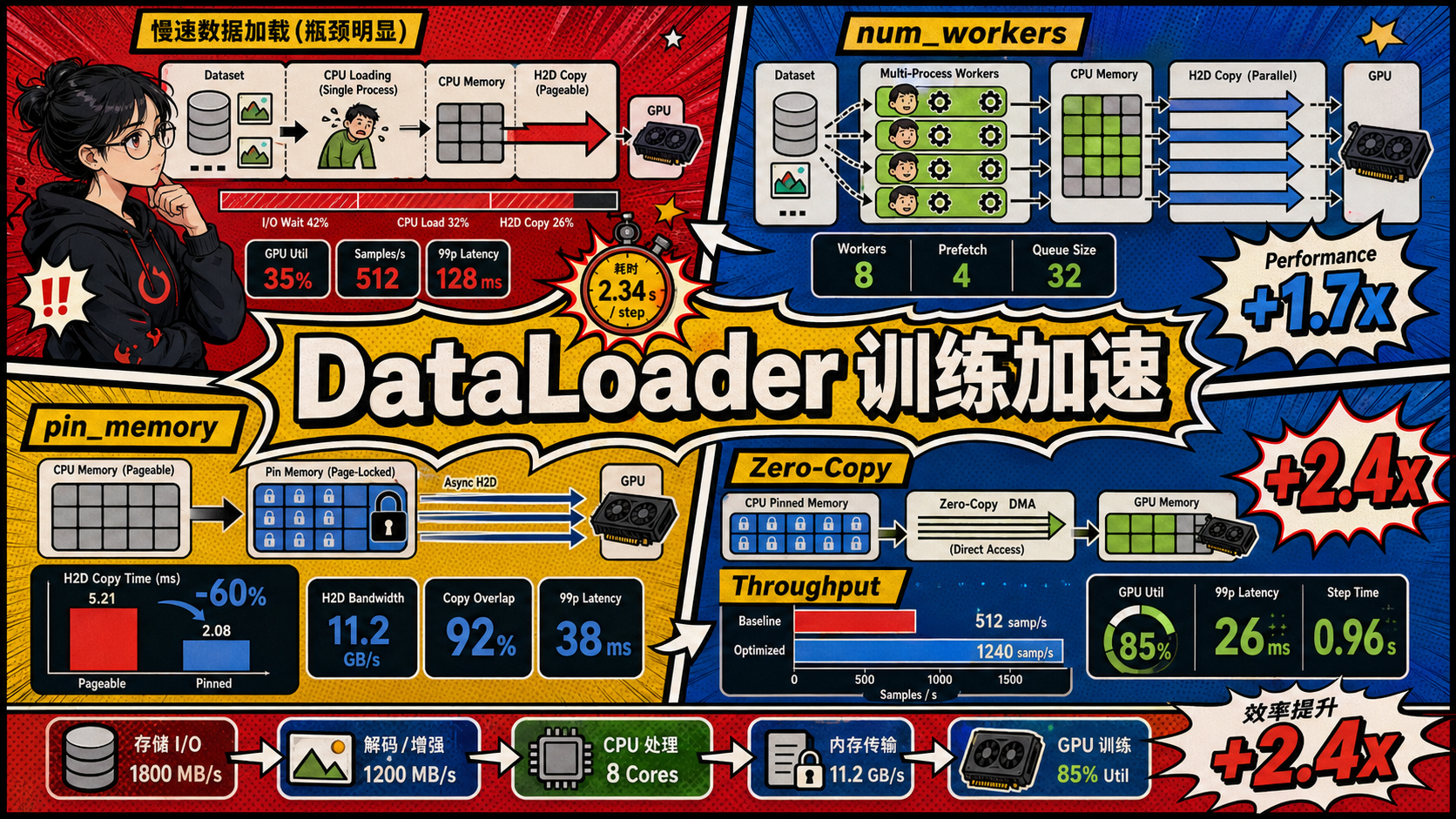
解决深度学习模型训练吞吐瓶颈的核心在于消除 CPU 预处理与 GPU 主机到设备间的数据搬运开销。通过在 PyTorch DataLoader 中开启多进程(),可以实现数据预处理与 GPU 前向计算的高效并行流水线重叠;而结合锁页内存()配置,则可促使操作系统物理锁定主机数据内存页,使 GPU 的 DMA 控制器通过 PCIe 总线执行高速的零 CPU 干预硬件拷贝,极大消除了多进程间的通信时延
KV Cache 是大模型推理的显存瓶颈,优化路径包括 PagedAttention 分页管理、前缀缓存复用和 KV 量化压缩。PagedAttention 消除了显存碎片,前缀缓存减少了重复计算,量化压缩降低了存储开销。落地时需关注块碎片浪费、缓存一致性和量化精度损失。建议从 PagedAttention + 前缀缓存开始,根据显存压力决定是否启用量化。

自回归推理的串行瓶颈是大模型服务化部署的核心挑战。推测解码通过草稿模型并行预取候选 Token 并批量验证,在不改变大模型结构的前提下实现了 2-3 倍的推理加速,其性能上限由草稿模型与大模型的能力差距决定。KV Cache 压缩通过量化、头剪枝和淘汰策略显著降低了显存占用,INT8 量化在大多数场景下能在 50% 显存节省的同时保持几乎无损的生成质量。在长文本和高并发推理场景下,将这些优化技术与

模型量化的核心是"精度换速度换空间"。本文的三种量化策略为:动态量化(最安全,精度损失 < 0.5%)、静态量化(最实用,精度损失 1-3%)、GPTQ 4-bit(最激进,大模型专用)。选型建议:CPU 推理用动态量化,GPU 推理用静态量化,大语言模型用 GPTQ。量化后必须在验证集上评估精度,损失超过 3% 时应回退到更高精度或使用 QAT。group_size 建议默认 128,精度不足时
大模型极致量化技术是打破大显存与低访存带宽桎梏的关键突破口。通过将模型浮点权重合理压缩至低位宽的整型(INT8/INT4),量化技术不仅大幅缩减了内存开销以压降硬件采购成本,更完美释放了 Tensor Core 硬件级别的整型高密矩阵乘法吞吐。在落地实施中,需根据激活值数据特征的分布情况,科学权衡对称量化的高吞吐优势与非对称零点纠偏的极佳保留精度,结合 QAT 或静态 PTQ 剪裁,才能最终交付出
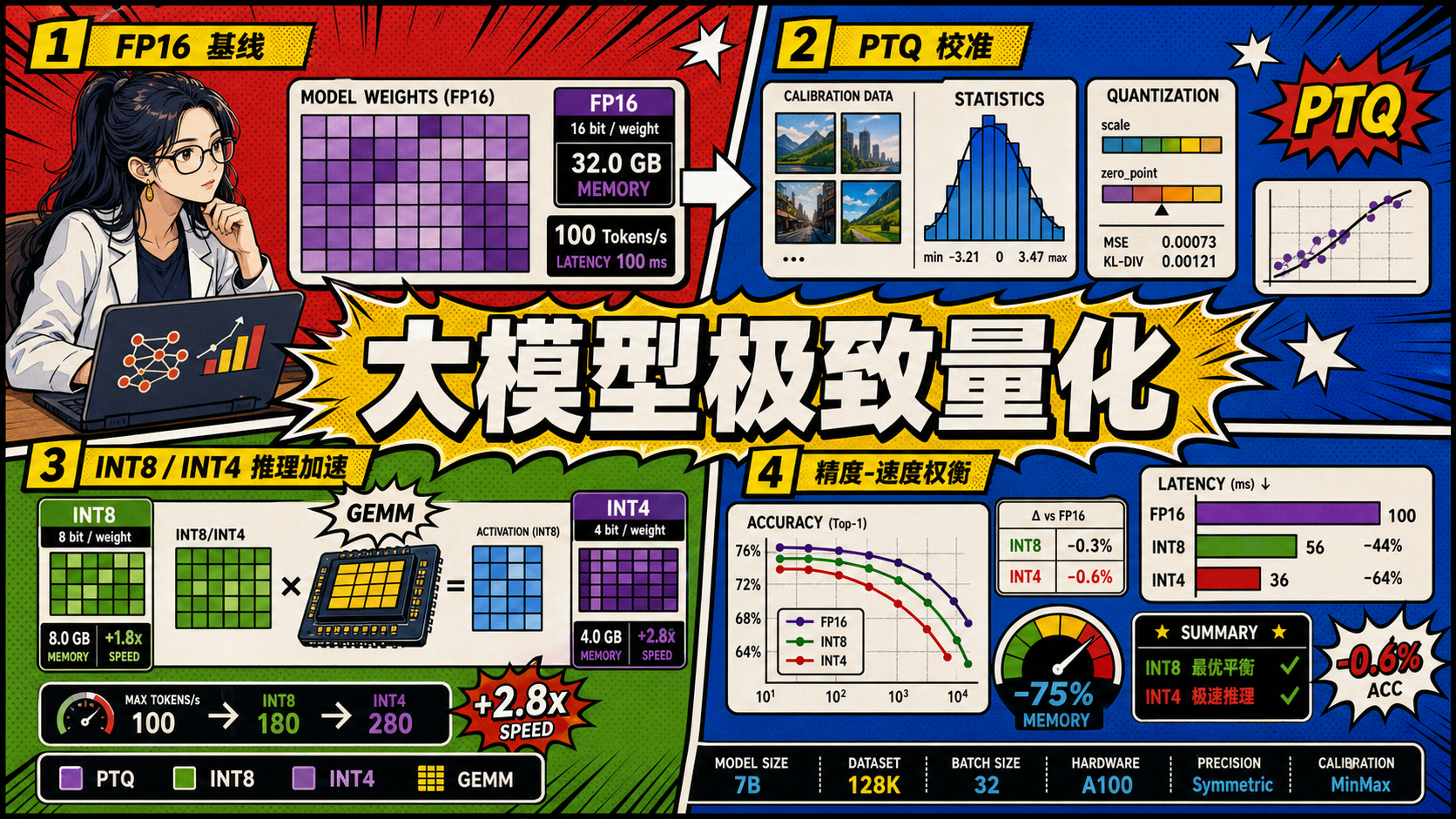
量化感知训练通过伪量化操作在前向传播中模拟量化效应,通过直通估计器在反向传播中近似传递梯度,使模型在训练阶段就适应低精度表示。按通道量化权重和按张量量化激活值是当前最主流的配置,在 Transformer 模型上通常可以在 INT8 精度下保持 1% 以内的精度损失。落地路线建议:第一步,先使用 PTQ(训练后量化)评估量化精度损失,如果损失在可接受范围内则无需 QAT;第二步,若 PTQ 精度不