- @swingwang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一键式配置导入,方便渠道伙伴和客户快速部署OpenClaw。围绕OpenClaw支撑多Agent的场景,浪潮信息基于元脑x86服务器完成系统级压力测试与工程验证,正式发布业界首份智能体宿主机性能评测报告:在192核/384线程高密度算力配置下,元脑x86服务器单机可稳定运行96路Agent实例,并支撑数百路并发业务会话,支持DeepSeek、Qwen、Kimi等主流Agent基座大模型调用,满足企

【AI行业价格战全面爆发】DeepSeek-V4近日掀起降价风暴,Pro版价格降至首发价1/10,Flash版缓存命中价仅0.02元/百万token。此次降价源于技术突破:深度绑定华为昇腾950PR芯片,算力效率提升近3倍,成本降低73%。这标志着AI竞争进入效率战新阶段,RAG知识库、长文档分析等高成本场景将迎来商用爆发。官方暗示下半年将继续降价,预示着国产AI正通过"模型+算力+成本

摘要:DeepSeek-V4预览版突袭式发布,以1M上下文为标配刷新开源大模型天花板。该模型通过mHC多流约束残差、CSA+HCA混合稀疏注意力等创新架构,有效解决长上下文计算瓶颈,在编程、数学推理等任务中媲美闭源顶流。工程上采用Muon优化器、细粒度计算通信重叠等技术,实现高效推理。V4系列包含Pro和Flash两个独立预训练的MoE版本,证明开源模型通过架构创新可突破性能极限。
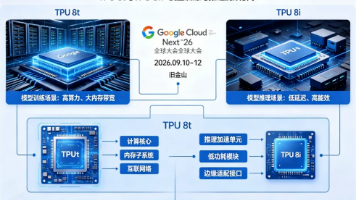
谷歌云发布第八代TPU系列,开创性推出专用于训练和推理的两款独立芯片:TPU8t主打大模型训练,性能提升3倍;TPU8i专注推理服务,延迟降低50%。该系列采用台积电2纳米制程,预计2026年下半年投入使用。谷歌同时宣布2026年将投入1750-1850亿美元用于AI基建,并透露75%的新代码由AI生成。此次发布标志着AI芯片进入专业化时代,挑战英伟达市场主导地位,推动AI产业加速发展。
摘要:DeepSeek-V4预览版突袭式发布,以1M上下文为标配刷新开源大模型天花板。该模型通过mHC多流约束残差、CSA+HCA混合稀疏注意力等创新架构,有效解决长上下文计算瓶颈,在编程、数学推理等任务中媲美闭源顶流。工程上采用Muon优化器、细粒度计算通信重叠等技术,实现高效推理。V4系列包含Pro和Flash两个独立预训练的MoE版本,证明开源模型通过架构创新可突破性能极限。
摘要:DeepSeek-V4预览版突袭式发布,以1M上下文为标配刷新开源大模型天花板。该模型通过mHC多流约束残差、CSA+HCA混合稀疏注意力等创新架构,有效解决长上下文计算瓶颈,在编程、数学推理等任务中媲美闭源顶流。工程上采用Muon优化器、细粒度计算通信重叠等技术,实现高效推理。V4系列包含Pro和Flash两个独立预训练的MoE版本,证明开源模型通过架构创新可突破性能极限。
华为昇腾950芯片推出PR和DT两款专用架构,分别针对大模型推理的两个关键阶段进行优化。PR芯片侧重Prefill和推荐场景,以计算密集见长,具备128GB内存和1.6TB/s带宽,主打首Token响应速度和性价比;DT芯片则专注解码和训练任务,拥有144GB大内存和4TB/s超高带宽,确保长文本生成流畅性和训练稳定性。这种"一芯双构"设计突破传统全能芯片思路,通过场景化细分实

华为昇腾950芯片推出PR和DT两款专用架构,分别针对大模型推理的两个关键阶段进行优化。PR芯片侧重Prefill和推荐场景,以计算密集见长,具备128GB内存和1.6TB/s带宽,主打首Token响应速度和性价比;DT芯片则专注解码和训练任务,拥有144GB大内存和4TB/s超高带宽,确保长文本生成流畅性和训练稳定性。这种"一芯双构"设计突破传统全能芯片思路,通过场景化细分实
华为昇腾950芯片推出PR和DT两款专用架构,分别针对大模型推理的两个关键阶段进行优化。PR芯片侧重Prefill和推荐场景,以计算密集见长,具备128GB内存和1.6TB/s带宽,主打首Token响应速度和性价比;DT芯片则专注解码和训练任务,拥有144GB大内存和4TB/s超高带宽,确保长文本生成流畅性和训练稳定性。这种"一芯双构"设计突破传统全能芯片思路,通过场景化细分实
比如对于端口数为 40 的交换机,两层胖树架构可容纳的 GPU 卡的数量是 800 卡,三层胖树架构可容纳的 GPU 卡的数量是 16000 卡。不同GPU编号的智算节点间,借助NCCL通信库中的Rail Local技术,可以充分利用主机内GPU间的NVSwitch的带宽,将多机间的跨卡号互通转换为跨机间的同GPU卡号的互通。网络可承载的 GPU 卡的规模和所采用交换机的端口密度、网络架构相关。网