登录社区云,与社区用户共同成长
邀请您加入社区
Selenium 是一个用于自动化测试的开源框架。它提供了多种工具和库,用于模拟用户在不同浏览器和操作系统上的行为,并且可用于测试网页应用程序。
目录1、搭建并配置Keil嵌入式开发环境1.1 Keil MDK-ARM下载1.2 Keil MDK-ARM安装1.3 Keil MDK-ARM注册2、基于STM32汇编程序的编写2.1记录build生成的 hex文件各段的大小,了解Hex文件格式及其前8个字节内容含义2.2学习在没有硬件条件下进行仿真调试的方法,观察ARM寄存器变化状况。1、搭建并配置Keil嵌入式开发环境1.1 Keil MD
在某些情况下,消息是使用未加密的SMTP发送的,我们可以从感染主机的流量中导出这些邮件消息。使用wireshark打开例1.pacp文件,使用http.request过滤流量包,找到两个GET请求,第一个请求以doc文件结束,第二个请求以exe文件结束。在进行网络流量分析中,往往需要从获取到的流量包中导出文件,进行更仔细的检查。使用wireshark打开例3.pacp文件,点击文件—导出对象—SM
Wireshark是一款开源网络抓包分析工具,前身为Ethereal(1998年开发,2006年更名)。它支持分析网络模型中的2-5层协议(链路层至应用层),广泛应用于网络排障、安全分析和软件开发。安装时需从官网(https://www.wireshark.org)下载,注意选择非C盘的安装路径,并建议勾选USBPcap等组件。安装过程需同意协议,按指引完成即可。该工具是网络工程师和安全人员的必备
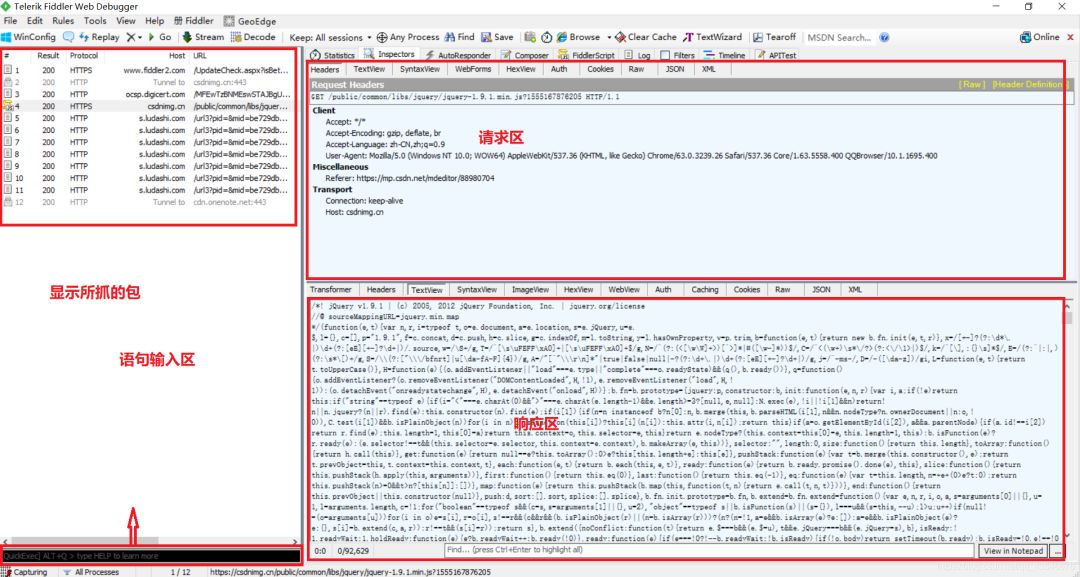
1.下载工具并安装如果我们要进行抓包分析,首先,我们必须要有一款抓包的工具,只有用工具抓到包,我们才能进行分析,在这里我介绍一款抓包软件Fiddler,我这里有这个软件的分享:
Wireshark是一款开源的网络协议分析器,可以捕获并显示网络上经过的数据包。它支持实时网络监测、数据包捕获以及详细的协议分析。Wireshark可以应用于多种网络场景,如以太网、无线网络等,并支持广泛的网络协议,如TCP/IP、HTTP、DNS等。
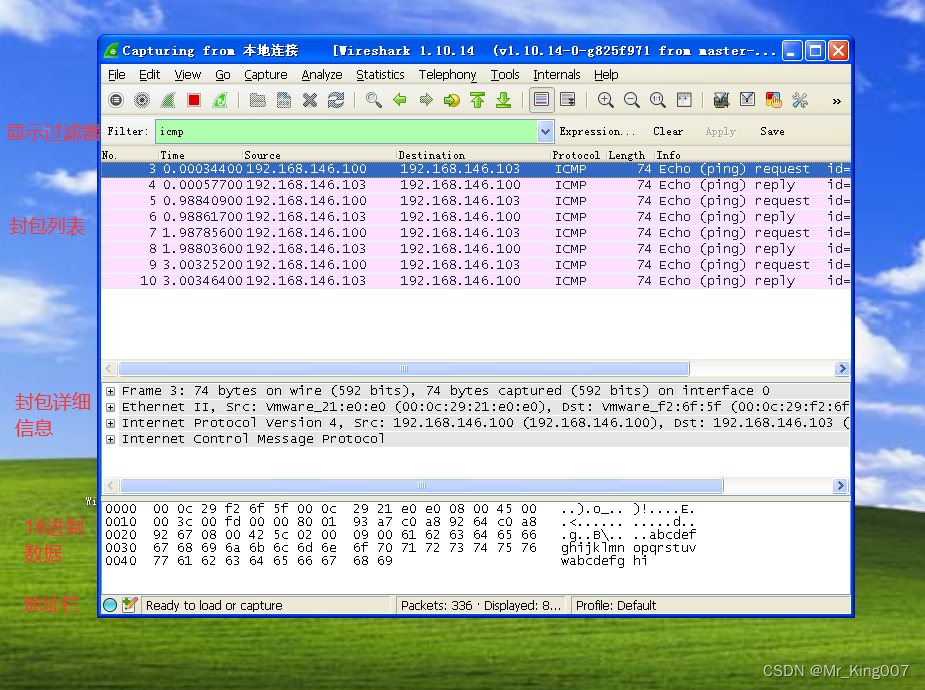
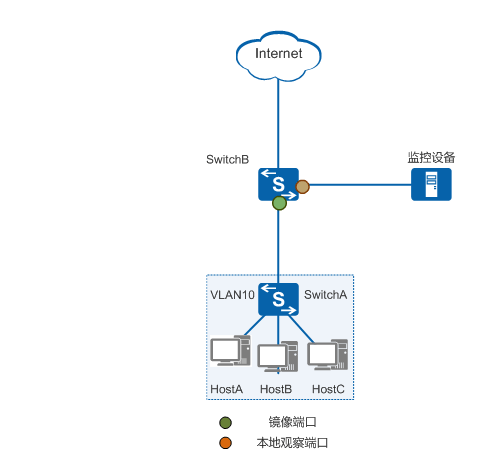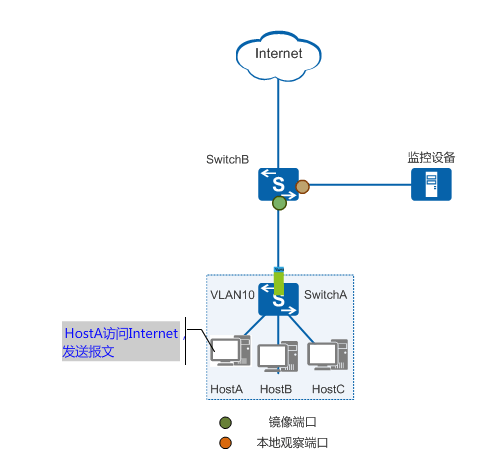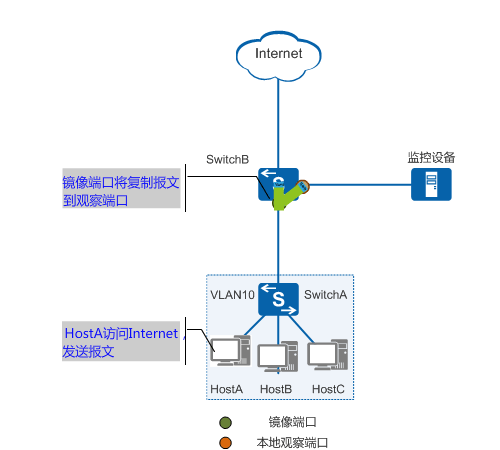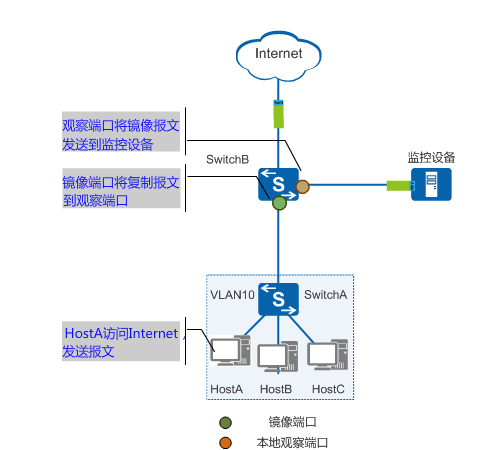
在windowsXP局域网环境中使用wireshark软件进行网络检测,捕获并分析icmp数据包。
本文介绍了开源网络分析工具WireShark的实用指南,涵盖安装配置、基础操作和实战应用。通过网页浏览案例,详细解析了TCP握手、HTTP请求等关键数据包,并提供了网络拥塞诊断方法,包括带宽利用率计算和ACK延迟分析。文章还介绍了高级功能如复杂过滤器、统计报告和脚本自动化,强调WireShark在网络故障排查、性能优化中的重要作用,同时提醒使用者需遵守法律和道德规范。
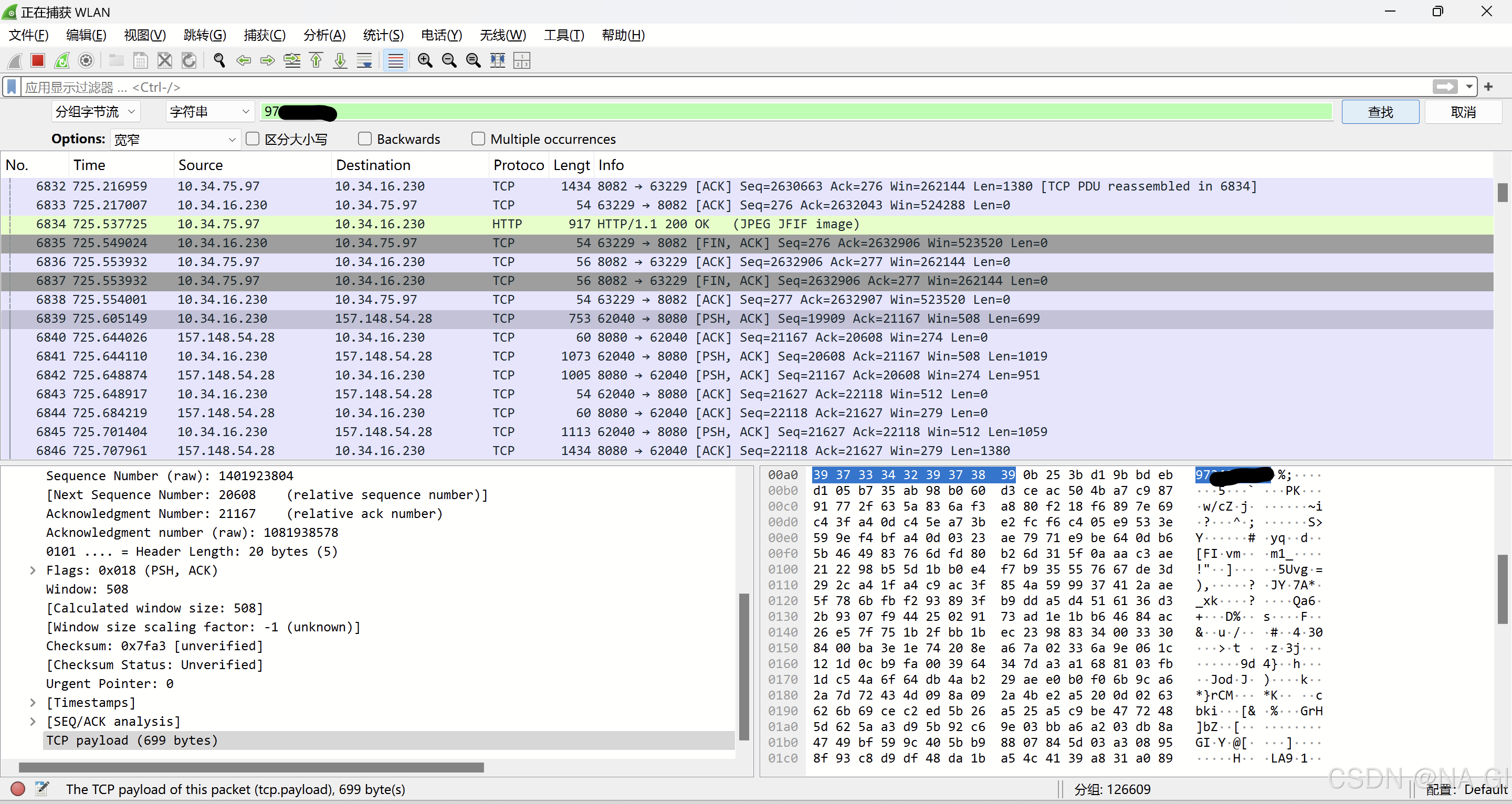
选中你找到的目标数据包,然后右键单击它。在弹出的菜单中,你会看到 “追踪流”(Follow Stream)选项。打开010,将刚刚保存的文件放入其中,把FF D8 FF 前的数据删除。将显示为改成原始数据,然后将数据另存为.jpg后缀的文件。Ctrl + f 打开搜索栏,输入自己的QQ号。删除后保存,重新打开图片后即可得到原图。
本文介绍了Wireshark网络封包分析工具的安装与基本使用方法。文章首先详细说明了Wireshark在Windows系统下的安装步骤,包括协议确认、组件选择等关键环节。然后通过一个简单的ping命令抓包示例,展示了Wireshark的基本操作流程。最后解析了Wireshark界面的主要组成部分,包括显示过滤器、数据包列表区和详细信息面板,并重点介绍了TCP数据包各层级(物理层、数据链路层、网络层
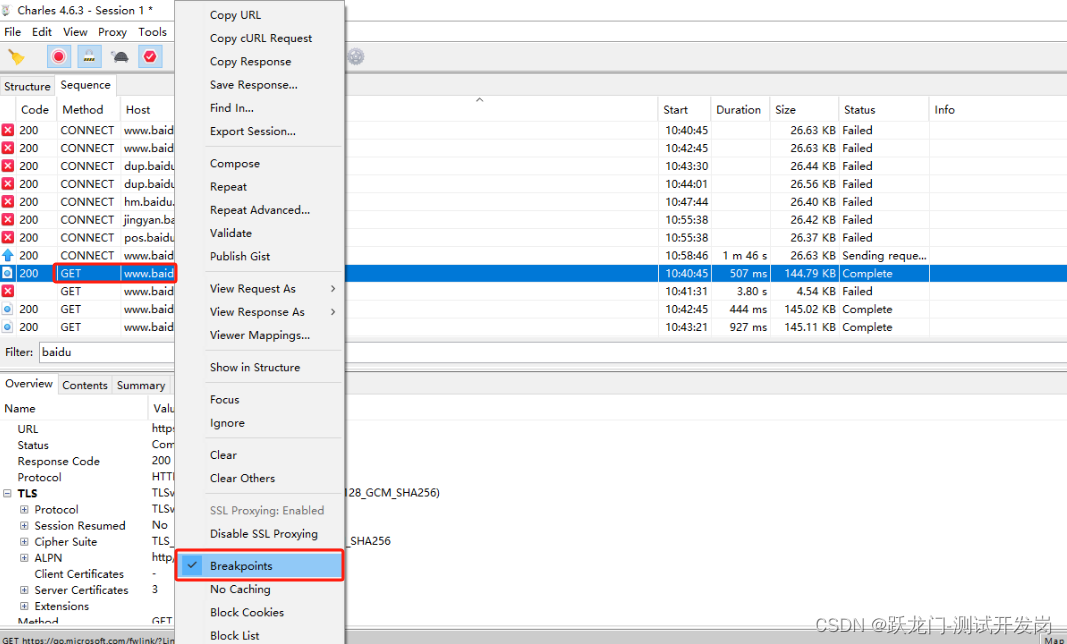
断点设置好后,此时通过浏览器访问https://baidu.com时,触发设置的断点,请求无响应。通过charles抓包,选择需要断点的接口,右键,选择“Breakpoint”如图。charles点击Execute按钮(执行),手动跳过断点,接口正常返回。程序需要考虑接口延迟时的处理逻辑,或接口异常时程序无严重问题。断点接口用来验证接口延迟时,程序是否正常。也可以通过“Add”按钮,增加断点接口。
Charles的基本操作:重定向,mock,以及限速限流,抓取数据包
说明:数据包列表区中不同的协议使用了不同的颜色区分。协议颜色标识定位在菜单栏View --> Coloring Rules。如下所示WireShark 主要分为这几个界面Display Filter(显示过滤器),用于设置过滤条件进行数据包列表过滤。菜单路径:Analyze --> Display Filters。Packet List Pane(数据包列表), 显示捕获到的数据包,每个数据包包含
Wireshark是我们最常使用的网络抓包软件,它是一款开源的免费软件,易于操作,初学者只需通过简单的学习就可以使用它来抓取数据包。其界面主要由数据包列表、数据包详细信息和数据包字节内容三部分组成。Wireshark的主要用途:网络管理员用来监测网络故障;网络安全工程师用来诊断安全问题;开发者用来调试协议的实现;人们用来学习网络协议。
【摘要】本文详细介绍了利用Wireshark抓取HTTP、MQTT和WebSocket流量的方法。对于HTTP抓包,需设置tcp port 80/443捕获过滤器,通过http显示过滤后可查看请求/响应内容;MQTT抓包需针对1883/8883端口,使用mqtt筛选查看PUBLISH消息;WebSocket则可通过websocket过滤,追踪会话消息。三种协议均支持数据包详细解析和会话流追踪功能,
评测通常是指对产品、系统、服务等进行系统的测试和评估,以确定其性能、功能、质量等方面是否符合特定的标准或要求,通过测试和评估来得出对产品或系统的具体评价。信创产品的评测现状目前国内信创评测对于确保信创产品的质量和性能至关重要,但目前国内在信创环境下的信息化系统质量评估方面缺乏统一的质量评估体系和测试工具,导致信创软件的评测标准不统一,评测内容和依据多为通用性标准,对特定行业技术应用场景的针对性不强
移动端抓包1.条件:需要保证手机跟电脑在同一个局域网内2.点击help–>SSL Proxying–> Install Charles Root Ceriticate on a Mobile Device or Remote Browser安装手机证书3.手机配置代理长按连接上的wifi--选择修改网络--显示高级选项--选择代理为手动--服务器主机名输入框中输入电脑ip地址,服务器端
WireShark是非常流行的网络封包分析工具,可以截取各种网络数据包,并显示数据包详细信息。常用于开发测试过程中各种问题定位。本文主要内容包括:1、Wireshark软件下载和安装以及Wireshark主界面介绍。2、WireShark简单抓包示例。通过该例子学会怎么抓包以及如何简单查看分析数据包内容。3、Wireshark过滤器使用。通过过滤器可以筛选出想要分析的内容。包括按照协议过滤、端口和
•。
安装好Charles之后,还只能捕获电脑的接口请求,想要抓取移动设备的APP还需要设置代理、安装证书。
摘要:人工智能从机器学习到深度学习的演进正深刻改变软件测试行业。机器学习早期应用于缺陷预测,而深度学习凭借多层神经网络在UI测试中实现突破,通过图像识别提升测试稳定性。AI技术推动测试用例自动生成、精准缺陷检测和智能监控发展。未来,多模态融合、智能体技术和可解释AI将成为测试领域重点方向,测试从业者需持续学习以把握技术变革机遇。(149字)
在人力成本持续攀升、市场竞争日益激烈的当下,“超级员工”这一概念正从科幻走进现实。它不是简单的工具叠加,而是由人工智能驱动、能够自主完成复杂工作流程的数字化劳动力。对于劳务派遣、人力资源服务、本地生活等高频沟通型行业而言,超级员工的核心价值并非取代人类,而是将人类从重复性事务中解放,聚焦于更高价值的决策与关系维护。行业报告显示,部署此类系统的企业,其咨询响应效率平均提升超过70%,人力成本优化幅度
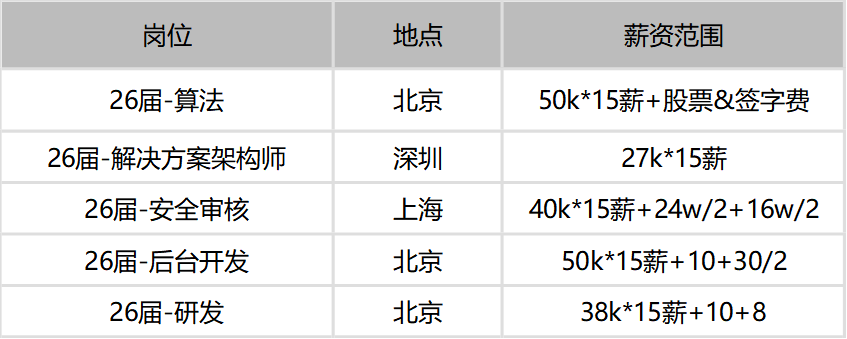
很多同学看到算法岗、AI岗薪资高,第一反应是:“那我是不是必须转算法?其实不一定。大厂研究院、基础模型、算法研究岗位,确实更看重学历、论文、数学基础和算法能力。但企业里更多的 AI 需求,并不是都在做底层模型。大量岗位其实是在做:AI应用开发AI工具平台AI测试平台智能客服系统企业知识库自动化办公流程数据分析智能体研发提效工具测试提效工具业务流程自动化也就是说,普通开发、测试开发、产品、运营岗位,
全球科技巨头争相布局AI基础设施,微软、谷歌、亚马逊等市值领先企业均在AI产业链占据关键位置,表明AI已成为下一代技术竞争的核心。企业正通过AI重塑业务流程,推动岗位结构变革——低效岗位压缩,高效人才需求激增。对测试开发等岗位而言,AI带来显著机遇:测试人员可借助AI优化用例生成、缺陷分析等环节,向质量效率工程师转型。当前AI产业更急需能将技术落地的应用型人才,而非仅关注理论研究。随着资本持续涌入
回归测试工具包括 Playwright、Lost Pixel、CueCast、Selenium、Ranorex、Katalon Studio 和 TestComplete。从开源/商业、代码/零代码、Web/桌面/移动等维度对比适用场景,帮助团队根据技术能力、测试范围和维护成本选择合适的回归测试方案。
当前市场上,提供数字人及AI营销服务的公司如雨后春笋。其中既有百度和阿里云等大厂推出的通用型数字人平台,也有像硅基智能这类垂直领域的先行者。然而,对于高度依赖矩阵化运营、高咨询量及低客单价获客的劳务行业、本地生活服务、实体门店而言,大厂的通用方案往往存在“大而全、不够深”的问题,面对劳务场景中专用的“工时计算”、“安置费”等复杂规则,容易出现AI“幻觉”;而部分垂直服务商则更侧重于直播代播,缺乏完
劳务招聘正步入一个全新的“人机协同”时代。以“超级员工”为代表的AI数字人系统,不再是一个遥不可及的概念,而是帮助企业应对人力成本与运营效率挑战的成熟解决方案。它通过自动化、智能化地完成内容生产、流量承接与线索管理三大核心环节,为劳务公司提供了一条清晰、可复制的提质增效路径。对于身处变革中的从业者而言,拥抱技术、主动进化,才是穿越周期、立于不败之地的关键。{图片链接}
这比事后用Xfilm埃利四探针方阻仪抽检要高效得多,但精度标定和基准校准仍离不开接触式测量。两类方法互补,才是完整方案。AI预测负责快速筛查和实时监控,四探针负责精准标定和仲裁——银纳米线电极的方阻表征,正在从"碰不碰"走向"怎么碰"的新阶段。
混合同错位(cross-record hallucination 或 cross-record mixup)指模型在处理一批合同记录时,把 A 合同的 URL、B 合同的内容、C 合同的业务场景混在一起输出。这意味着:如果你给模型一次性输入了 200 条合同,模型不会理解“这是 200 条独立样本”,它会认为这是“一个巨大的语料库”,并在其中“寻找它认为合理的关联”。你之前遇到的这段就是典型“混合
默认参数往往只能保证“能跑”,要想“跑得好”,需要根据具体任务调整生成策略。generate: 控制随机性。设为 0.1 时输出确定性强,适合事实问答;设为 0.8 时更具创造性,适合写故事。: 从累积概率超过 p 的最小词集中采样。通常设为 0.9,与 temperature 配合使用效果更佳。: 惩罚重复内容。设为 1.1 到 1.2 可以有效减少模型车轱辘话。: 限制最大生成长度,防止无限生
本文探讨了temperature参数对AI模型(deepseek-v4-pro)处理不同复杂度任务的影响。通过测试创意写作、逻辑推理和电商报告三种任务(各运行2次),发现:1)所有任务在temperature=0.3和1.0时成功率均为100%,但电商报告的平均Token(556)显著高于创意写作(190);2)temperature对Token数的影响因任务而异,未呈现稳定规律;3)结构化任务(
它不是单一的AI功能,而是一支具备“专业分工、自动协作、持续优化”能力的数字员工团队。从热点监控、文案仿写、智能生图、口播视频生成、批量混剪,到全网分发、搜索拦截、AI流量入口占位……每个环节都有独立的智能体在协作运转。当大多数企业还在尝试“用AI做一个PPT”时,聪明的企业主早已用系统搭建起了一支“不会请假、不会涨薪、24小时在线的数字营销军团”。这或许就是铸云超级员工系统,多年后依然被用户坚定
│ ││ 输入质量决定输出质量(Garbage In = Garbage Out) ││ ││ AI负责"生成" + "穷举" ││ 人负责"判断" + "决策" ││ ││ 多轮迭代 > 一次性输出 ││ 分模块处理 > 全量输入 ││ 结构化Prompt > 随意提问 ││ │。
Mac Studio M3 Ultra明显占优。它拥有四倍内存容量和三倍理论内存带宽,特别适合单机加载超大模型、处理大型媒体工程和承担综合性专业工作。DGX Spark仍然有自己的护城河。CUDA、TensorRT-LLM、vLLM、NGC和NVIDIA服务器生态,使它更适合真正围绕NVIDIA平台进行模型开发、微调、验证和部署。Mac Studio是一座容量巨大、传送带很宽的全能仓库;DGX S
WHartTest 并不是简单地在旧系统上贴一个“AI”标签,而是将大模型能力深度植入到了测试的每一个环节。1. 需求阶段:AI是你的“找茬”专家在传统模式下,需求评审往往流于形式。而在WHartTest中,你可以直接上传PDF、Word或Markdown格式的需求文档。智能评审:系统会从完整度、清晰度、可测性等6个维度对需求进行打分,并生成专项分析报告。风险前置:AI能自动识别出逻辑矛盾或描述模
摘要: 本文针对大语言模型选型痛点,通过10个核心维度进行深度实测,包括架构解析、多轮对话、代码生成、创意写作、行业应用等,揭示不同模型在真实场景下的表现差异。测试发现,参数效率、长文本处理、幻觉控制等关键能力与宣传存在差距,而MoE架构、思维链提示词等技术创新显著提升实用性。文章强调模型选择需匹配具体场景——开发者应关注算法解题能力,企业需重视事实核查机制,创作者则需侧重风格模仿精度。最终建议通
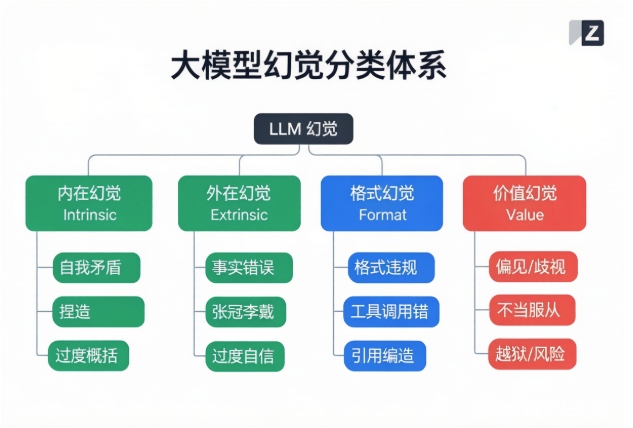
本文分享了团队搭建大模型幻觉测试体系的实践经验。首先提出了四种幻觉分类:内在、外在、格式和价值幻觉。随后介绍了测试环境准备要点及五种核心测试方法:1)基于知识库的事实性测试;2)逻辑一致性自检;3)对抗性测试;4)边界压力测试;5)RAG场景专项测试。重点强调了评估者校准的重要性,需建立人工标注金标准来校验自动化判分器。该方案通过多维度测试协同,形成覆盖90%以上问题的检测体系,并持续将新发现转化
TestOne基于Ai驱动的自动化测试平台,深度融合大模型,提供一站式自动化测试管理及脚本开发,助力企业显著提高测试效率的同时保证高质量交付。
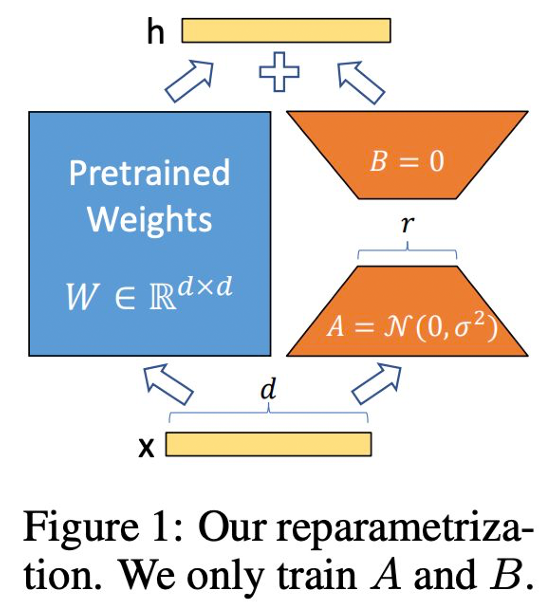
大家的显卡都比较吃紧,LoRA家族越来越壮大,基于LoRA出现了各种各样的改进,最近比较火的一个改进版是dora,听大家反馈口碑也不错。
测试工具
——测试工具
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 深开鸿 技术专区
深开鸿 技术专区




















 AI编程社区
AI编程社区

 AI Agent技术社区
AI Agent技术社区




 EazyDevelop社区
EazyDevelop社区

 智能体开发者社区
智能体开发者社区





 DeepSeek技术社区
DeepSeek技术社区