- @Bbbbei_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Data Agent 是一款基于大语言模型的企业数据智能助手,提供免费版、个人版和企业版三种版本,分别满足个人用户的基础使用、进阶需求及企业的多用户协作、安全管控与私有化部署等场景,支持通过自然语言对话完成数据查询、分析与处理,无需编写代码,助力各层级用户高效实现数据驱动决策。其中,只有Data Agent 企业版支持本地、它云、ecs自建等常见数据库,如:MySQL、PostgreSQL、Hol
Data Agent 是一款基于大语言模型的企业数据智能助手,提供免费版、个人版和企业版三种版本,分别满足个人用户的基础使用、进阶需求及企业的多用户协作、安全管控与私有化部署等场景,支持通过自然语言对话完成数据查询、分析与处理,无需编写代码,助力各层级用户高效实现数据驱动决策。其中,只有Data Agent 企业版支持本地、它云、ecs自建等常见数据库,如:MySQL、PostgreSQL、Hol
RDS AI 助手旗舰版在 RDS AI 助手专业版智能运维能力的基础上,提供灵活模型选择、智能模型路由、多模型灾备、API Key 集成等更自主可控、灵活便捷的模型服务,并支持纳管运维各类环境部署的数据库。
PolarDB AI 能力是指基于阿里云原生数据库 PolarDB 构建的一个“AI 就绪的一体化数据底座”,通过软件与硬件的深度融合、资源解耦与池化,让多模态数据在入库之后,都能够被高效地与模型、算力融合处理,从而支撑推理、搜索及面向 AI 应用开发的快速迭代。重点解读了 PolarDB 面向 AI 的关键能力,给出了可复用的解决方案与架构路径,覆盖典型场景的选型、集成与落地要点;站在 AI 与

本书系统阐述了阿里云核心自研云原生数据库 PolarDB 与 AI 融合的技术路径、核心场景及未来趋势。重点解读了 PolarDB 面向 AI 的关键能力,给出了可复用的解决方案与架构路径,覆盖典型场景的选型、集成与落地要点;希望本书能成为您探索 AI 实践的指南针——无论是开发者、架构师,还是企业决策者,都能从中找到属于自己的“数据智能跃迁之路”。站在 AI 与数据库融合的拐点,我们相信:谁掌握
是基于大模型技术,融合了阿里云10万+工单和专家经验的智能数据库运维大脑,专注于解决云数据库的日常运维及稳定性问题。全新智能化运维体验,7*24小时扫描,助力万千企业迈入 AI-Native 运维时代,以深度诊断,运维提效,多引擎覆盖能力,实现企业运维能力平权,保障企业核心数据库业务持续在线。:RDS MySQL、PolarDB MySQL版、其他云厂商的MySQL、本地自建MySQL;
哔哩哔哩联合阿里云 PolarDB for AI,构建“大模型+小模型”协同的全域内容洞察体系,基于去标识化公开互动数据,实现视频、评论等内容的结构化分析,精准识别品牌、类目、用户反馈属性,助力营销效果量化与策略优化。
龙虾的记忆问题相信大家都遇到过 — 对话经常从零开始,记不住你说过什么。是一个开箱即用的解决方案 — 只需一句话,你的龙虾就能自己完成全部安装和配置。
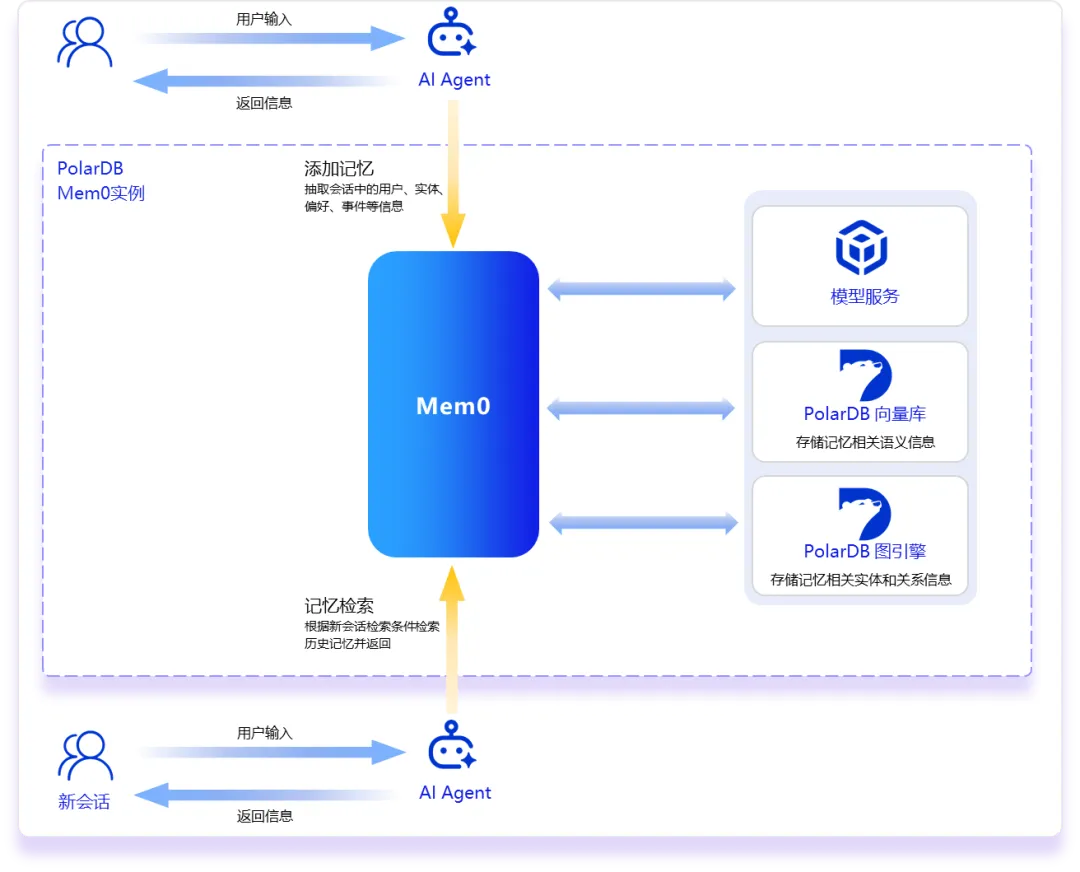
模型在记忆管理中扮演了核心的角色,其中:大语言模型LLM负责从用户与智能体的对话中自动提取出具有长期价值的关键事实与偏好,同时用于新记忆与已有记忆的融合(增删改)以及基于图的实体三元组信息抽取;PolarDB-PG记忆管理真正融合了图+向量一站式记忆库 + 开放记忆引擎 + 模型算子能力,提供了全面白屏化的参数配置,提示词策略管理以及模型算法混池加速能力,支撑“记忆读写 → 上下文注入 → 模型推
阿里云 PolarDB MySQL 版推出 Mem0 托管服务,专为 AI Agent 打造长期记忆能力。融合向量库与图引擎,100%兼容开源 Mem0,支持语义提取、多模态检索与记忆演进,存储成本降30%+,助力 Agent 实现“千人千面”的持续学习与智能进化。