登录社区云,与社区用户共同成长
邀请您加入社区
海光DCU BW1100多实例测试显示:单卡144GB HBM显存可在8卡节点上高效运行4个Qwen3.6-35B-A3B模型实例,峰值吞吐达5348.25 tok/s,较单实例提升147%,扩展效率达87%。多实例并发下单路吞吐稳定在8-9.64 tok/s,延迟控制在48-58秒,显存利用率达92%。测试表明BW1100具备接近线性的多任务扩展能力,其超大显存和成熟的ROCm生态为国产AI算力
在深度学习工程落地的过程中,硬件选型往往决定了项目的成本上限与扩展边界。随着 AMD ROCm 生态的日益成熟,越来越多的团队开始尝试将原本基于 NVIDIA CUDA 构建的大模型训练与推理 pipeline 迁移至 AMD GPU 平台。这不仅仅是更换几行代码或修改几个环境变量那么简单,它涉及到从底层算子适配、编译工具链切换,到上层框架兼容性验证的全链路改造。许多开发者在初次接触时,常会被复杂
海光DCU BW1100成功验证FP8量化技术在大模型推理中的优势:在Qwen3.5-122B-A10B模型测试中,FP8相比FP16在GSM8K、MMLU和HumanEval三项基准上平均精度损失不到1%(代码生成任务甚至反超1.28%),同时在4K输入/1K输出场景下实现吞吐量2984.18 tok/s,性能提升高达147.3%。测试结果表明,海光BW1100的FP8支持成熟可靠,可显著降低大
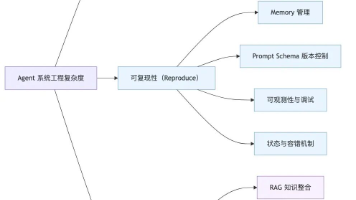
文章探讨了AI Agent系统开发的复杂性,指出虽然框架如LangChain降低了入门门槛,但真正的复杂性并未消失,只是被转移或推迟。Agent系统需要具备可运行、可复现、可进化的特性,开发过程需经历从简单Demo到系统化工程的四个阶段。作者强调Agent开发需要将智能不确定性转化为工程确定性,通过系统化方法确保Agent的稳定性、可控性和可进化性,而非仅依赖prompt工程。
上下文工程是从提示工程演进而来的系统化方法,旨在设计动态信息环境,为LLM提供正确信息、工具、时机和格式。文章提出六层上下文模型(指令、用户提示、短期记忆、长期记忆、检索信息、可用工具和结构化输出),并介绍三种核心策略:压缩整合、结构化笔记和子代理架构。通过系统化上下文工程,可构建更强大的AI应用,解决长上下文中的注意力分散问题,实现从"廉价Demo"到"魔法Agent"的转变。
Claude Code是一款基于终端的智能编程工具,它能理解您的代码库并通过自然语言命令执行常规任务、解释复杂代码和处理…
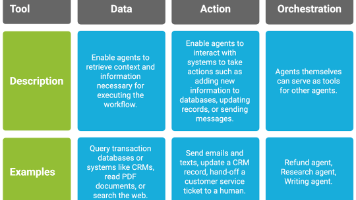
文章介绍了AI智能体的设计原则、核心组件和实现方法,包括如何评估适合智能体的应用场景、选择合适的模型、定义工具和配置指令。详细阐述了主管模式和群体模式两种编排架构,提供了代码实现示例,并讨论了多智能体系统面临的挑战及应对策略。最后提出了构建可扩展AI Agent的路线图,从LLM选择到多智能体团队扩展,为开发者提供了全面的指导。
本文提供了2025年AI大模型产品经理高频面试题及参考答案,涵盖基础认知、技术理解、Prompt工程和模型定制化等核心领域。重点解析了AI产品经理与传统产品经理的区别,强调技术可行性、数据闭环和伦理安全等关键考量。技术部分详细解释了Token、上下文窗口等术语对产品设计的影响,并给出模型评估和幻觉管理的实用策略。交互设计方面展示了Prompt工程的实际应用案例和复杂AI助手的UX设计思路。最后对比
摘要:大模型存在幻觉问题和知识断层两大痛点,RAG(检索增强生成)通过先检索外部知识库再生成答案的方式有效解决。文章推荐了和鲸社区@云逸~的LangChain RAG实战项目,该项目结合LangChain框架与Qwen3模型,实现了从数据索引到接口服务的完整RAG问答系统。系统采用三步流程:构建索引(文档向量化)、检索精排(提升结果相关性)、生成回答(降低幻觉)。项目亮点包括Embedding+R
本文详细介绍了如何利用字节跳动的AI编程工具Trae Solo构建多模态RAG系统的前端界面,并分享了"三步走"的Vibe Coding最佳实践:构建结构化提示词、提示词优化和精准问题定位。通过实际案例演示了使用Trae Solo快速开发前端应用的全过程,包括模块化架构设计、流式对话交互实现和PDF引用溯源功能等,为AI辅助编程提供了实用方法论。
文章讲述了传统产品经理面临的挑战与AI产品经理的机遇,详细介绍了AI产品经理的四大分类及转型路径。文章强调AI领域投入持续增加,传统产品经理应拥抱AI转型,通过确定方向、构建AI知识体系、学习专业能力和实践项目来实现转型。核心是精准定位与持续学习,通过亲手打造AI项目来检验所学并理解产品全生命周期。
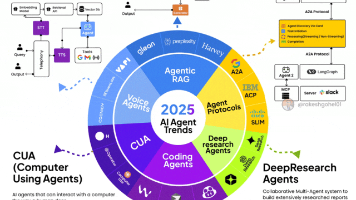
AI智能体时代来临:2025年AI技术正从生成式AI向Agentic AI快速转型,智能体将重构人机协作模式。报告显示,52%企业已部署生产级AI智能体,88%早期采用者获得显著投资回报。文章系统分析了六大智能体类型(检索增强型、语音交互型、协议标准化型等)及其在金融、医疗等领域的应用价值,同时指出数据隐私、系统集成等挑战。未来将形成智能体商店生态,企业需建立责任自治框架,确保AI安全与伦理。AI
文章分析了AI行业突然爆发现状,指出AIGC领域岗位需求激增,存在人才缺口。详细介绍了AI产品经理的定义、工作内容与分类,强调其需兼具技术理解力与产品思维。为转行AI产品经理提供了具体准备建议,包括学习AI基础知识、熟悉产品流程、积累项目经验和保持学习心态。最后分享了AI大模型学习路线与资源,帮助读者抓住AI发展机遇。
很多AI Agent团队做着做着,会陷入一种“看起来很忙、其实很虚”的状态:项目一个接一个,交付也都能交付,但每次立项都像从荒地里重新搭帐篷——需求换个行业、换个客户、换个说法,代码重写一遍;Prompt改到深夜,第二天又推翻;知识散落在群聊、会议纪要和某个同事的脑子里。最要命的是,团队会越来越像外包:干一单结一单,越干越累,越累越不敢停下来做沉淀。
文章详细介绍了产品经理转型AI产品经理的路径,包括AI产品经理的定义、四大类别(视觉、机器学习、应用、语义)、必备技术基础知识及工作日常。同时提供大模型AI四阶段学习体系:初阶应用(10天)、高阶应用(30天)、模型训练(30天)和商业闭环(20天),帮助读者系统掌握从基础应用到模型训练再到商业部署的全流程技能,成为被AI武装的产品专家。
大模型本地部署的核心在于协议兼容与推理可控性,尤其当面向代码助手等强交互场景时,单纯‘能跑通’远不足够。本文聚焦于Qwen3.5-9B在消费级显卡(如RTX 4090)上的稳定落地,深入解析sglang作为系统级框架如何通过reasoning-parser与tool-call-parser实现原生工具调用支持,并结合LiteLLM完成Anthropic协议到OpenAI接口的无损桥接。技术价值体现
演讲中回顾了其在龙蜥社区孵化并向上游贡献的 SGLang Tracing 可观测性建设历程,并结合具体案例探讨如何利用 AI Agent 实现 SGLang 框架的性能优化。
摘要: 开源框架Slime重塑大模型强化学习训练范式,以简洁的三模块架构(训练、推理、数据缓冲)实现生产级RL流水线,核心设计包括正确性优先、原生透传和开放数据接口。其工程化能力支撑智谱GLM-5.2仅用2天完成OPD后训练,性能提升显著,并兼容多款主流基座模型。围绕Slime已衍生12个生态项目,覆盖全模态RL、智能体优化等场景,形成技术生态位。开源后引发行业热议,智谱创始人唐杰与马斯克就中国模
本文对比了vLLM和SGLang两款高性能LLM推理框架在个人开发者场景下的表现。评测聚焦吞吐量和首Token延迟两大核心指标,分析了两者在技术架构上的差异:vLLM凭借PagedAttention和ContinuousBatching技术在高吞吐量和显存管理方面表现突出,适合批量处理任务;而SGLang的Pythonic API设计使其在首Token延迟和交互体验上更具优势,更适合实时应用场景。
大模型推理的三大瓶颈:内存、吞吐、延迟传统推理框架的局限性新一代推理框架的兴起吞吐量(Tokens/s)延迟(P50/P90/P99)内存使用效率成本效益分析各项指标冠军汇总框架优势领域性能短板分析。
SGLang(Structured Generation Language)是伯克利 LMSYS 团队推出的高性能大模型推理框架,最新稳定版 v0.5.6(2026),2026/06 推出新一代投机解码 DFlash 与 Spec V2,2026/04 实现 DeepSeek-V4 Day 0 支持,2026/02 在 NVIDIA GB300 NVL72 上达成 25x 推理性能。与 vLLM
vLLM与SGLang推理框架性能横评摘要 本文对比了两种主流LLM推理框架——vLLM(聚焦高吞吐)和SGLang(侧重低延迟)的核心特性和性能表现。测试在相同硬件(A100 GPU)和模型(LLaMA-2-7B)下进行,评估了吞吐量、延迟、内存效率和扩展性。 关键发现: 吞吐量:vLLM凭借PagedAttention技术,在长文本推理和大规模并发请求中表现更优;SGLang的动态批处理则在高
GPUStack 支持可插拔的推理引擎架构,允许自定义推理后端及其版本,用于引入 GPUStack 未内置的vLLMSGLangMindIE版本,或接入其他自定义推理引擎镜像。为了部署模型,这里以SGLang最新v0.5.12CUDA 版本官方镜像地址国内镜像地址cu130cu129对于其他 GPU,可前往查找 SGLang 官方打包的专用镜像。在推理后端菜单,编辑 SGLang,在版本配置中选择
同时,FlagGems 新增 6 大领域算子库——FlagDNN、FlagBlas、FlagSparse、FlagFFT、FlagTensor、FlagAudio,覆盖科学计算与信号处理场景,共计 102 个领域算子,从"大模型专用"走向全领域覆盖。厂商目录放置后由插件自动发现加载,vLLM-Plugin-FL、SGLang-Plugin-FL、Megatron-LM-FL、Transformer
测试先于选型:不要只看 Benchmark 跑分,一定要拿你们自己真实业务的 Prompt 分布去压测。短文本和长文本的配比,直接决定了最终的吞吐表现。监控指标抓重点:别光盯着 QPS,核心盯住GPU 显存占用率KV Cache 命中率P99 延迟。尤其是 P99,业务方对卡顿极其敏感。部署隔离:长短文本请求务必分开部署到不同的推理集群,千万不要把它们塞进同一个框架实例中,否则调度器会让你痛不欲生
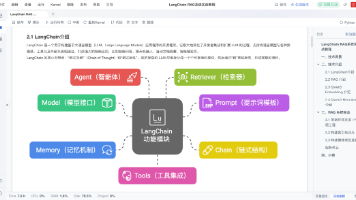
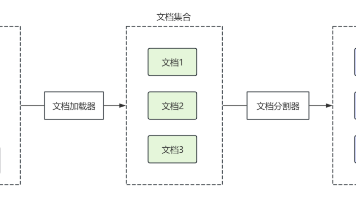
RAG(检索增强生成)技术通过结合信息检索与大语言模型生成能力,有效解决了大模型的四大痛点:知识边界限制、信息更新滞后、幻觉问题及专业领域知识不足。其实现流程分为准备阶段(文档收集、处理、向量化)和使用阶段(相似性检索、提示词构建、结果生成)。LangChain框架提供了一套完整的RAG实现组件,涵盖文档加载、文本分割、向量存储到检索生成全流程,极大降低了开发门槛。该技术使大模型具备了实时获取和利
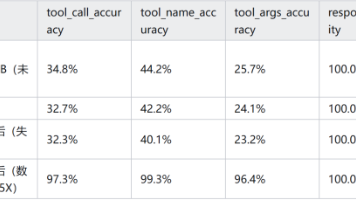
本文探讨了垂直领域Agent落地中的稳定性问题,指出大模型在复杂上下文中工具调用不稳定是主要障碍。作者提出用小模型(Qwen3-8B)进行后训练,通过SFT注入领域知识,DPO对齐工具调用偏好,使工具调用准确率从30%提升至97%-99%。该方法将工具调用契约固化进模型参数,提高了系统的可回归性和工程落地能力,为垂直Agent落地提供了新思路。
文章分享零基础获取算法实习的"从0到1"路径:重塑简历创造经历、夯实基础应对面试、用项目打造机会、调整心态把握机遇。同时提供AI大模型应用开发六大学习模块,强调找实习最大障碍是信息差与勇气,而非能力,鼓励读者把握AI时代机遇实现职业跃迁。
本文系统梳理了当前主流的大模型推理部署框架,包括vLLM、SGLang、TensorRT-LLM、Ollama、XInference等。vLLM基于PyTorch,采用PagedAttention和ContinuousBatching技术,适合高并发企业级应用;SGLang通过RadixAttention优化缓存复用,擅长多轮交互场景;TensorRT-LLM由NVIDIA深度优化,在GPU上性能
没有"最好",只有"最适合"
Transformers 的 Beam Search 实现集中在的 GenerationMixin 类中,核心方法是。与 vLLM 不同,Transformers 的 Beam Search 是纯张量操作的实现——所有 beam 的扩散、评分、剪枝都通过 PyTorch 张量运算完成,没有面向对象的序列管理,也没有 HTTP 层的编排开销。和 vLLM 老版本的实现一样,支持 early_stop
## 总结2026年四大主流 LLM 推理框架已各有明确的工程定位:vLLM 是生态最完整的全能选手,SGLang 在高并发和结构化生成上独树一帜,LMDeploy 是国产生态的最佳搭档,TensorRT-LLM 是吞吐量的性能天花板但部署成本最高。建议团队以 vLLM 作为默认起点,根据具体业务瓶颈(延迟/吞吐/量化/国产GPU)再针对性切换到专项优化的框架。与此同时,框架能力分化加剧:有的擅长
SGLang 与 vLLM 并非替代关系,而是同源互补的推理框架:vLLM 擅长通用高并发推理,是简单对话场景的高效选择;SGLang 聚焦复杂结构化任务,通过前端 DSL 与 RadixAttention 技术,实现“可编程性+高效性”的统一,是 Agent 等复杂 LLM 应用的最优解。
sglang
——sglang
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AMD开发者中国社区
AMD开发者中国社区


 DeepSeek技术社区
DeepSeek技术社区


 AI Agent技术社区
AI Agent技术社区








 龙虾开发者社区
龙虾开发者社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区









 脑启社区
脑启社区



 2048 AI社区
2048 AI社区