




- @HUANGXIN9898
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我几乎每天都被问到这个问题。在 LangChain,我们开发工具,帮助开发者构建大型语言模型 (LLM) 应用。这些应用就像会思考的引擎,能与外部信息和计算资源互动。人们常把这类系统叫做 “代理”。对于 AI 代理 (AI Agent),每个人的理解都有些不同。我的理解可能更技术化:AI 代理是一个系统,它用 LLM 来决定应用程序的控制流程 (Control Flow)。即使这样,我也觉得我的定

随着大型语言模型(LLM, Large Language Models)在自然语言处理(NLP)领域的不断进步,越来越多的开发者对这一领域产生了浓厚的兴趣。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。作为一名从业五年的资深大模型算法工程师,我经常会收到

又到一年高考季,因为这几年一直在研究大模型,有好几个家长朋友都来咨询,要不要给自己孩子报考计算机专业?接到这个问题,面对“周更”、甚至“日更”的大模型浪潮,着实难给出一个准确的回答,只能说:编程作为一种抽象和拆解问题的方法论依旧重要,但写代码这件事正被重新定义——自然语言正快速变成新的最高级的编程语言。。Karpathy提出了vibe coding(氛围编程)的趋势,这也意味着用户可能会忘记代码的

图片来源:百度所谓智能体,指的是能独立采取行动以实现特定目标的 AI 实体。想象你有一个贴心的小跟班,你让他干啥他就干啥。比如你让他查明天的天气,他立马就给你整得明明白白。举个栗子,AI 面试官就是一个很棒的智能体。它能够根据招聘要求,自主给候选人发送试邀请,然后自主进行视频面试,再自主进行面试评价,自主发送 offer。最后把招聘的统计报告发送给你。是不是超省心?当然了,智能体也存在很多缺陷,特
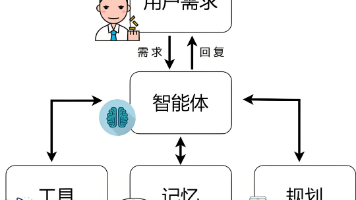

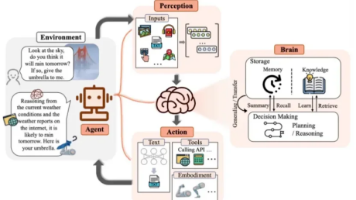
同时课程详细介绍了。

智能体简介会在首页以及名片页展示,需要简洁明了的介绍智能体用途。用第三人称的角度去说明你的智能体可以解决哪个问题,比如,输入一个课程题目为你生成课程大纲、说出一个主题为你生成一段脚本等。

同时课程详细介绍了。

同时课程详细介绍了。
