




- @xxue345678
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果你问我:测试开发转AI最好的路线是什么。我会给你一句特别简单的话。不要从Agent开始。不要从大模型原理开始。不要从论文开始。Prompt↓LangChain↓RAG↓评测体系↓Agent↓LangGraph↓MCP↓工程化↓上线当你走完整条路线。你会发现。原来企业里的AI项目,远远没有网上说得那么玄学。本质上还是那套熟悉的软件工程。只是把“代码逻辑”变成了“模型能力”。而真正拉开差距的,从来

如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
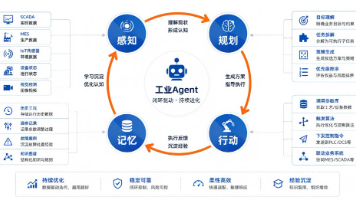
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
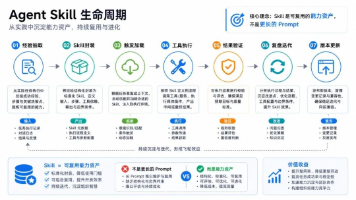
本文深入探讨了AI Agent的核心技术,从ReAct、Plan-and-Execute到Reflection等理论模式,详细解析了主流AI Agent框架的对比与选择建议。文章重点阐述了AI Agent框架的核心要素,包括LLM Call、Tools Call和上下文工程,并通过实例展示了如何设计和实现一个极简的AI Agent框架。此外,还讨论了Agent Loop在上下文管理中的关键作用,以

本文深入探讨了AI Agent的核心技术,从ReAct、Plan-and-Execute到Reflection等理论模式,详细解析了主流AI Agent框架的对比与选择建议。文章重点阐述了AI Agent框架的核心要素,包括LLM Call、Tools Call和上下文工程,并通过实例展示了如何设计和实现一个极简的AI Agent框架。此外,还讨论了Agent Loop在上下文管理中的关键作用,以
本文深入探讨了AI Agent的核心技术,从ReAct、Plan-and-Execute到Reflection等理论模式,详细解析了主流AI Agent框架的对比与选择建议。文章重点阐述了AI Agent框架的核心要素,包括LLM Call、Tools Call和上下文工程,并通过实例展示了如何设计和实现一个极简的AI Agent框架。此外,还讨论了Agent Loop在上下文管理中的关键作用,以
到了 2026 年,随着模型能力越过某个门槛,Agent 产品设计已经不像一年前那样高度依赖基础模型迭代,模型输出也开始达到相对稳定的工程可用状态。Agent 工程师的重心越来越多地从“技术探索”转向“应用落地”。对大多数企业团队来说,问题已经很具体:从 0 开始做一个 Agent,到底是什么流程,到底应该怎么把它做成能上线、能复用、能评估、能被业务长期使用的产品?
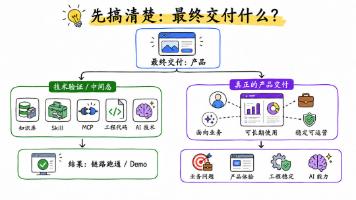
到了 2026 年,随着模型能力越过某个门槛,Agent 产品设计已经不像一年前那样高度依赖基础模型迭代,模型输出也开始达到相对稳定的工程可用状态。Agent 工程师的重心越来越多地从“技术探索”转向“应用落地”。对大多数企业团队来说,问题已经很具体:从 0 开始做一个 Agent,到底是什么流程,到底应该怎么把它做成能上线、能复用、能评估、能被业务长期使用的产品?
到了 2026 年,随着模型能力越过某个门槛,Agent 产品设计已经不像一年前那样高度依赖基础模型迭代,模型输出也开始达到相对稳定的工程可用状态。Agent 工程师的重心越来越多地从“技术探索”转向“应用落地”。对大多数企业团队来说,问题已经很具体:从 0 开始做一个 Agent,到底是什么流程,到底应该怎么把它做成能上线、能复用、能评估、能被业务长期使用的产品?