




- @m0_64880608
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
第二步,用向量数据库存这些片段,说白了就是给每个片段标个 “标签”,比如 “2024 年 618 活动规则”“用户退款流程”,这样 AI 后来提问时,能快速找到相关的片段,不用翻遍所有文档;另一种是调用 API,比如 GPT-4o、通义千问或者智谱清言,不用管部署,拿来就能用,量小的话很便宜,我上周测试下来,50 块钱用了 3 天,回答了差不多 200 个问题,对个人用户来说完全够了。对了,要是你

我同事用它做 Excel 表格,比如把杂乱的销售数据整理成图表,只要跟模型说 “帮我写一段 VBA 代码,把 A 列到 E 列的数据按销售额排序,生成柱状图”,它就能直接出代码,复制到 Excel 里就能用,省了不少时间。而且你还能折腾点小玩法,比如给模型装个界面,用 Gradio 或者 Streamlit 弄个可视化窗口,这样不用每次都开终端,点鼠标就能用,看起来还更专业 —— 我闺蜜看我弄完,

这是因为 Java 里集合框架(包括 ArrayList)只能存对象,而 int 是基本类型,不是对象,Integer 是 int 的包装类,本质是对象,所以才能存。它的容量是 “动态变化” 的,你不用一开始就指定大小,直接 new ArrayList<>() 就行,想存多少元素就 add 多少,比如 add ("A")、add ("B"),存到第 10 个的时候,它会自动扩容(默认初始容量是 1

如果觉得每次写 if 麻烦,还能用上 Apache Commons Lang 工具包的 StringUtils.isEmpty (str),这个方法会自动处理 null,哪怕 str 是 null,调用也不会报错,比自己写判断省事儿多了。但如果换成 str.equals ("hello"),那肯定会炸,这就是空指针的关键:只有当你用 null 引用调用方法(比如 equals、length ())
小索奇之前帮同事排查过一个空指针问题,印象特别深:他写了个获取用户地址的方法,里面用 user.getAddress ().getCity (),平时用户都有地址信息,结果某天来了个新注册用户没填地址,address 直接是 null,一调用 getCity () 就报错,整个订单流程都卡住了。另外,尽量避免在集合里存 null,比如返回集合的方法,别直接返回 null,而是返回空集合(比如 Co

测试时,用户注册提示 “成功”,但数据库里没数据,查了半天日志才发现,是发送验证码时第三方接口超时,触发了IOException,但catch里只打印了堆栈,没中断注册流程,也没回滚已执行的 “生成用户 ID” 操作 —— 你看,就因为异常处理 “只打印不处理”,不仅掩盖了问题,还导致数据不一致,后续排查花了整整 2 小时。所谓 “吞异常”,就是在catch块里只打印堆栈(甚至不打印),不抛出自定
但 LinkedList 就惨了,它没有连续的内存空间,要找第 5 个元素,得从第一个节点开始,顺着指针一个一个数,直到数到第 5 个,要是找第 500 个,就得数 500 次 —— 小索奇之前做过测试,用 get (index) 访问 10 万条数据的第 8 万条,ArrayList 只要 1 毫秒,LinkedList 却要 120 多毫秒,差距不是一般大。再说说 “增删操作”,这部分很多人容

Java 异常处理总踩坑?吞异常、丢日志还崩服务!3 招避坑代码稳如狗。

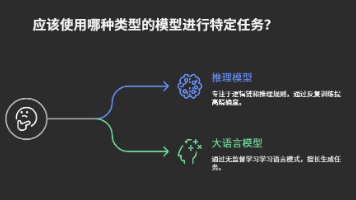
我们来看看什么是推理模型。推理模型的核心在于 多步骤推理,它不仅仅是接收输入并给出答案,而是在输入的基础上,模拟人类的思维过程,进行一系列的逻辑推理。推理模型的优势是,它能理解复杂任务中的各个层次,逐步推导出合理的结论。举个例子,推理模型常见的应用包括 数学证明、复杂的逻辑推理、以及 法律文书解读。这类任务往往不止依赖于简单的数据关联,而需要通过深入分析多种条件,逐步得出结论。
简单说,就是把原本要绑在子元素上的事件,绑到它们的父元素上,让父元素 “代收” 事件,再判断该处理哪个子元素的事件。其实解决这问题不用反复绑定事件,用 JS 的 “事件委托” 一招就能搞定,不管是 10 个按钮还是 100 个按钮,甚至后来新增的按钮,只要绑一次事件就行,今天咱们就把这事说透,代码少还实用。就这几行代码,不管原来有多少个删除按钮,还是后来新增多少个,点击都能用 —— 因为父元素.t
