- @2401_85390073
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI Agent在企业落地面临场景错位与技术瓶颈双重挑战。九科信息bit-Agent作为企业级GUI智能体,通过高精度界面操作和"能力固化"机制实现100%流程可控,兼容全主流大模型,轻量化部署。该方案聚焦单一场景深度优化,成功应用于上汽集团等企业,实现人机分工革命,有效提升企业效率,为智能办公提供新范式。

文章讲述35岁失业人群如何利用AI工具(如鲸歌AI助手)重新开始职业生涯,通过短视频、文章等内容创作获得收入。AI技术正在打破能力壁垒,让普通人也能高效创作变现。现在是抓住AI红利的最佳时机,借助AI工具开启副业之路,实现职业重生。
文章精选8个热门开源项目,包括老乡鸡开源菜谱、无代码数据库NocoDB、OpenAI终端编程助手、Web安全学习工具WebGoat、TEN语音AI框架、无限画板tldraw、阿里DeepResearch智能模型等。这些工具覆盖日常应用开发、AI语音交互、数据库管理、安全学习等多个领域,帮助开发者快速构建应用、提升编程效率,是技术爱好者不可多得的学习资源。
本文面向企业法务团队和管理者,系统介绍了AI的定义、分类、商业战略价值及实施方法。重点分析了AI在知识产权、数据安全、隐私保护、伦理合规等方面的风险,提出了相应的管理策略。同时探讨了AI对残障人士的影响及企业如何负责任地应用AI技术,为企业合规使用AI提供专业指引。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
上下文工程是筛选和管理AI可用信息的策略,区别于关注"怎么说"的提示工程。AI存在"上下文衰减"问题,注意力有限,处理长信息能力不足。做好上下文工程需:1)素材精准精简;2)按需即时检索信息;3)处理长任务采用上下文压缩、结构化笔记和子智能体架构。这本质是重塑人与AI的协作关系,将AI视为有注意力极限的队友,以最低信息成本实现最优结果。

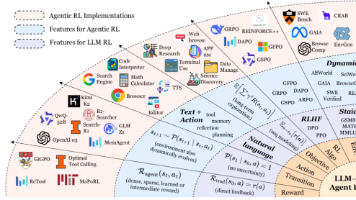
文章介绍了AI从"语言模型"向"智能体(Agent)"进化的新范式,核心驱动力是智能体强化学习(Agentic RL)。这种强化学习赋能智能体六大核心能力:规划、工具使用、记忆、推理、自我改进和感知,使其能在动态环境中自主决策、采取行动。Agentic RL正在各专业领域催生能力更强的专用智能体,展现出巨大应用潜力,但也面临可信赖性、训练规模化和环境规模化等挑战。
EPIC是上海交大等机构提出的渐进一致性蒸馏学习框架,通过token一致性蒸馏(TCD)和层一致性蒸馏(LCD)解决视觉token压缩导致的训练难题。该框架无需改动模型结构,兼容多种Token压缩方法,实验表明在保留128个视觉token时性能与原始模型相当,192个及以上时甚至超越原始模型,显著提升多模态大模型的效率与性能。

OpenAI发布Agent Builder,允许用户通过自然语言创建能自主执行复杂任务的智能代理。AI Agent从被动响应转向主动行动,可拆解目标、调用工具完成任务。文章详细介绍了50个应用场景,覆盖个人生产力、企业管理、市场分析、技术研发等多个领域,标志着AI从工具向"伙伴"的转变,未来核心竞争力将是定义问题和管理AI团队的能力。

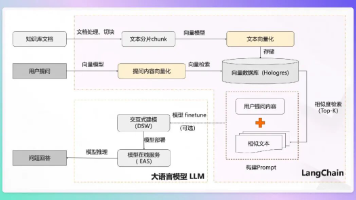
本文剖析了AI智能体框架的三层生态格局(学习、开发、生产框架),详解LangChain、LlamaIndex等主流框架特点与应用场景,提供基于需求、技术栈、学习曲线和生态成熟度的选型指南,帮助开发者把握AI智能体开发先机。