复合智能体开发路线图:从核心原理到工程实现(文末送书)
【摘要】系统介绍了构建复合智能体的技术框架与实践方法。指出单一LLM在复杂业务场景下的局限性,提出通过模块化设计实现可控性、工具化、可组合性和可审计性的目标。核心部分详细解析了六大组件:LLM作为基础接口层、RAG增强事实检索、Memory管理系统状态、Tooling实现外部调用、MCP/A2A标准化交互协议,以及LangChain等编排框架的使用。随后对比了三种典型架构模式的适用场景,并举例说明
目录
摘要
复合智能体将大语言模型从“会说”升级为“会做、会协同、可审计”的工程系统。本文面向工程实践者,从体系化组件(LLM、RAG、Memory、Tooling、MCP/A2A、编排框架)切入,详解构建复合智能体的技术路线、架构模式与实现要点,并给出可落地的代码示例与流程图,帮助读者把理论转为工程产物。文末附书籍推荐,便于系统学习。
一、为何需要“复合智能体”——问题与目标定位
单一 LLM 在生成与问答上表现优秀,但企业级应用面对的是复杂业务:跨系统调用、长会话记忆、事实校验、审计合规、多任务并行等。复合智能体(composite agent)旨在把这些能力工程化,即构建由多模块、多策略和多能力协同工作的系统,目标包括:
- 可控性(减少幻觉、可校验输出)
- 工具化(可靠调用外部 API/DB/服务)
- 可组合性(任务拆分与协作)
- 可审计性(每一步有证据链路)
在此背景下,开发者需要理解从模块设计到端到端流转的每个技术细节,而不是仅依赖 Prompt 的“技巧”。
二、复合智能体的核心组件详解
下面逐一拆解构成复合智能体的关键模块,并说明实现要点、权衡与示例。
2.1 LLM:智能体的大脑(接口层与能力层)
职责:理解自然语言、生成文本、做链式推理。
工程关注点:
- 模型来源:商业 API(如 OpenAI)与本地/自研模型(如 Qwen、DeepSeek)之间的成本、延迟与合规取舍。
- 推理方式:同步调用 vs 流式输出(streaming);流式能改善首字节延迟体验。
- 精度提升:结合指令集、few-shot、chain-of-thought(需权衡可解释性与引导误差)。
示例(伪代码):
# 简化的 LLM 调用接口(伪)
response = llm.chat(messages=[system_prompt, user_prompt], stream=True)
for chunk in response:
process(chunk)
2.2 RAG(检索增强生成):事实增强的标准方案
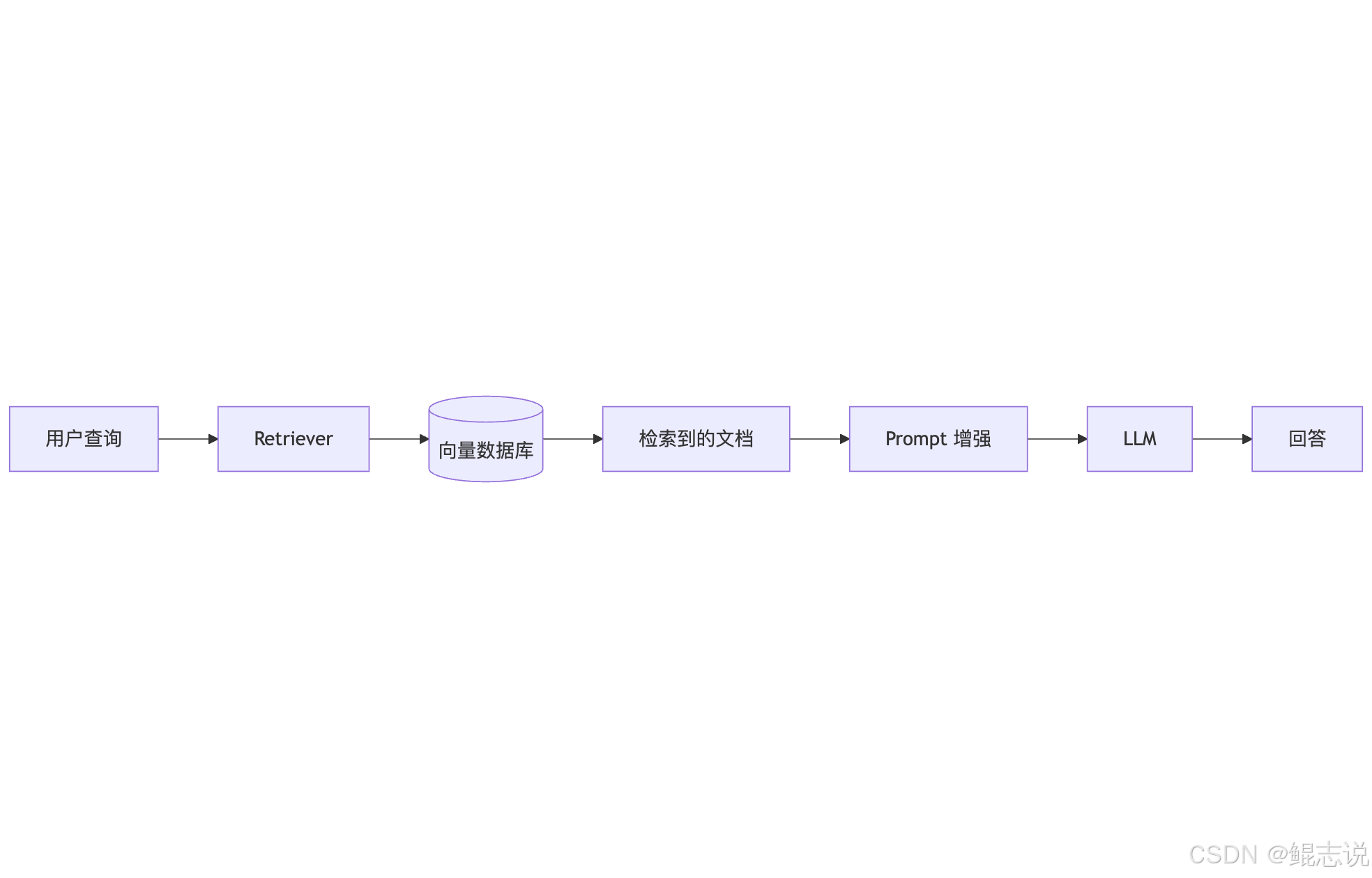
核心流程:文档分块 → embedding → 向量索引 → top-k 检索 → 将检索片段注入 Prompt → LLM 生成。
实现要点:
- 分块策略:句子/段落/滑窗,兼顾召回与上下文完整性;
- Embedding 对齐:Embedding 模型需与检索器/LLM 语义空间尽量对齐;
- 向量库优化:HNSW / IVF 参数、ef_search/ef_construction 调优以平衡延迟与准确率。
RAG流程图:
示例(Python 伪):
emb = embed(text_chunk)
index.add(emb, meta)
results = index.search(query_emb, top_k=5)
aug_prompt = build_prompt(user_query, results)
answer = llm.generate(aug_prompt)
2.3 Memory(短期/长期记忆):会话与用户画像的管理
类别:
- 短期记忆:session 层快速上下文(保留 recent turns),通常以 token-limit 或 sliding window 控制。
- 长期记忆:结构化事实或 embedding + 向量检索(用户偏好、历史事件)。
实现建议:
- 对长期记忆采用可索引的向量 + 元数据,支持 TTL & 手动修正;
- 对短期会话考虑自动摘要(summary)以降低 token 成本;
- 记忆修改需支持审计日志(谁改、改了什么)。
2.4 Tooling(工具调用):定义、沙箱与错误处理
形式:Function Call / API 调用 / DB 查询 / 外部 Agent。
关键点:
- 工具 schema:统一定义输入输出格式(JSON schema),便于模型生成可解析的调用指令;
- 安全隔离:请求必须经过网关或沙箱层校验,避免注入与越权;
- 错误恢复:工具失败需有回退策略(重试、退级、人工介入)。
工具 schema 示例:
{
"name": "query_order",
"input": {"order_id":"string"},
"output": {"status":"string","items":"array"}
}
2.5 MCP(Model Context Protocol)与 A2A(Agent-to-Agent)
MCP(模型上下文协议)旨在标准化模型之间与模型→工具的数据交换,包括:指令类型、意图标签、调用元信息、证据片段。MCP 的核心价值是可解析性与可追踪性。
A2A 描述 Agent 间协作:任务分配、结果集成、错误回滚。常见模式为协调者/调度器(orchestrator)或对等通信(peer-to-peer):
A2A 简化示意:
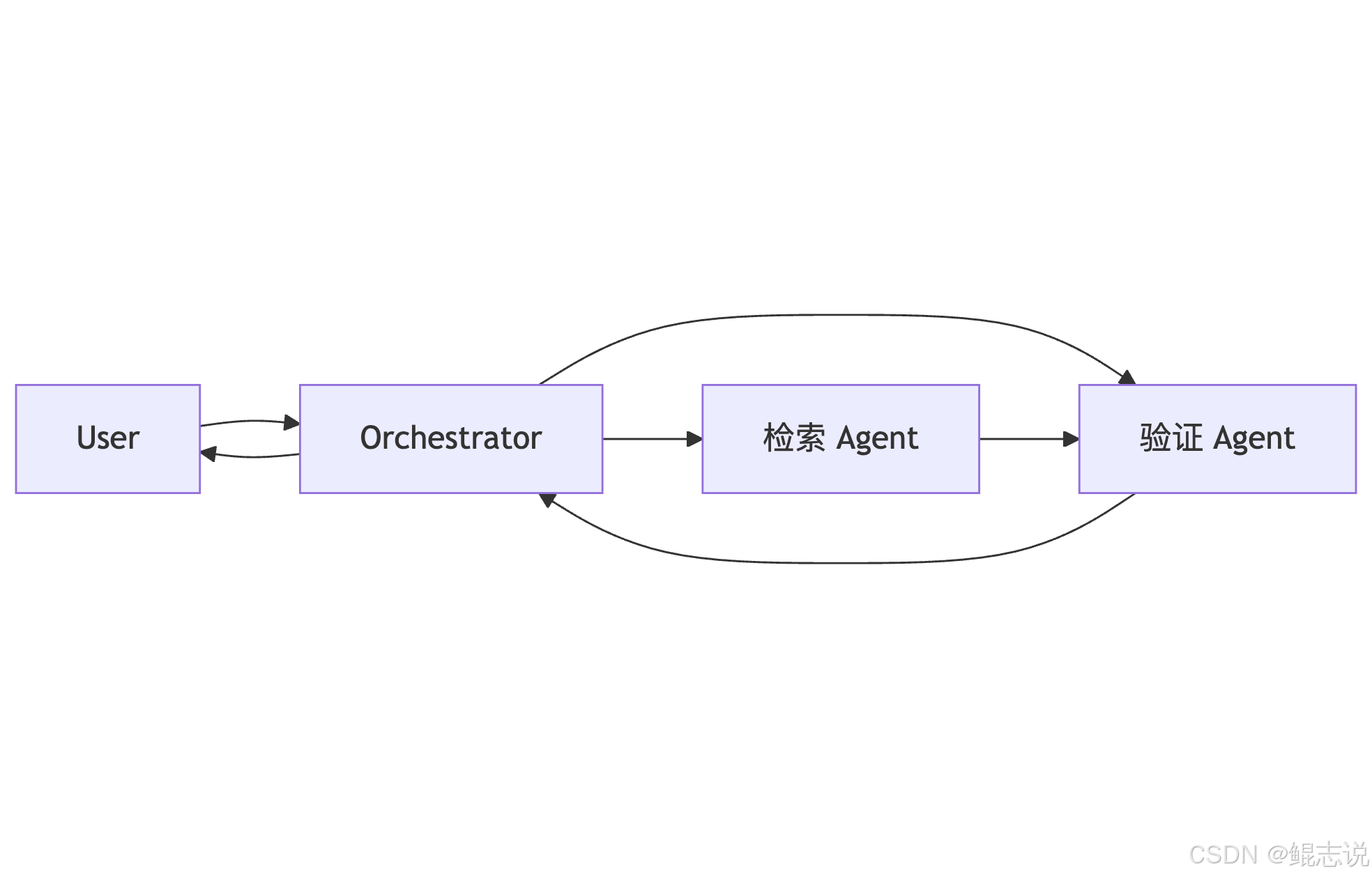
实现 MCP/A2A 的注意点:能力声明(capabilities registry)、超时与重试、消息序列化与版本兼容。
2.6 LangChain、LangGraph 与低代码平台
- LangChain:提供 Prompt、Chain、Agent、Memory、Retriever 等抽象,方便把模块化概念落地成工程化代码。
- LangGraph:在复杂工作流上提供可视化编排与状态跟踪,适合多步骤、多分支场景。
- 低代码平台(如“扣子”类):降低业务侧接入门槛,但在复杂策略与可定制性上通常受限,需要通过插件/扩展接口补充能力。
LangChain 组合示例(伪):
from langchain import PromptTemplate, ChatOpenAI, Tools, Agent
prompt = PromptTemplate("用户问:{q}")
llm = ChatOpenAI()
tools = Tools([...])
agent = Agent(llm=llm, tools=tools, prompt=prompt)
agent.run("请帮我查今天的订单状态")
三、常见架构模式与设计选择
复合智能体常见架构(按复杂度):
3.1 单体 RAG + LLM
适合 FAQs、文档问答。优点:实现简单,成本低。缺点:难应对跨域任务与外部动作。
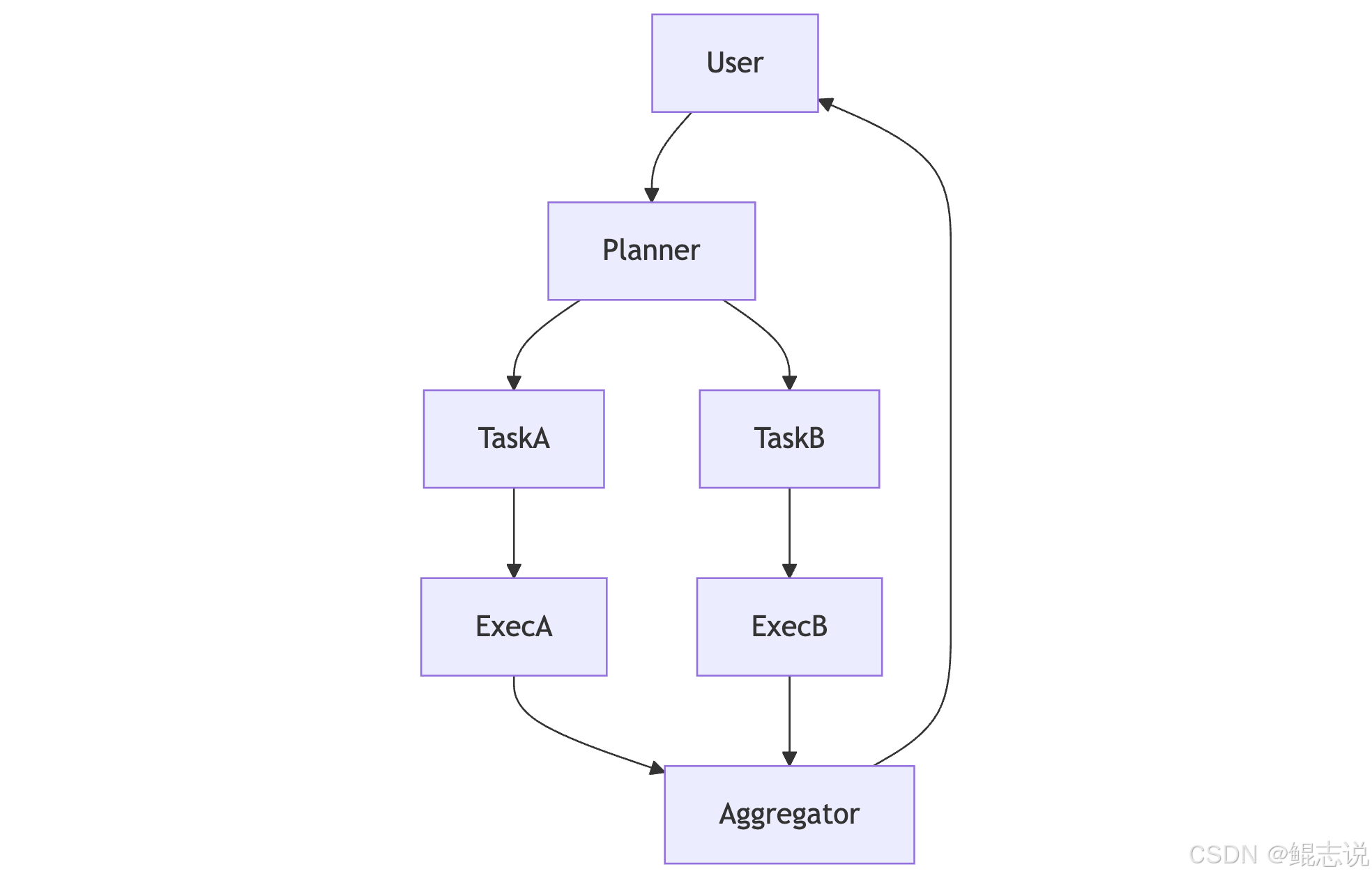
3.2 Planner–Executor(分层)
Planner 负责高层规划与任务拆解,Executor 池负责实际调用工具/子 Agent。此方式清晰分工、易扩展,适合需要任务拆解与并行执行的场景。
3.3 多 Agent 协同(A2A)
多个专业 Agent 各司其职,再由 Orchestrator 协调结果汇总。优点:高内聚低耦合,便于团队分工;缺点:设计复杂,需要成熟的消息协议(例如 MCP)与错误处理策略。
Planner–Executor 流程示例:
四、模型整合与兼容性考量(以 Qwen3.0、DeepSeek-V1 为例)
在工程中通常要面临“多模型并存”与“模型替换”的问题。整合时建议关注:
- 接口抽象:封装统一的 LLM 接口(chat、generate、embed),便于后续替换。
- Embedding 对齐:不同模型 embedding 分布可能不同,检索效果受影响,必要时需要重新训练或做 cross-encoder 校正。
- Token 与上下文:不同模型的 context window(上下文窗口)不同,prompt 设计需适配并做降采样或摘要。
- 性能 & 成本:评估推理延迟、吞吐与价格(API 调用费用 vs 自托管成本),设计 fallback 策略(小模型预筛,大模型确认)。
工程实践建议:
- 建立“模型适配层”,包含:tokenizer 封装、embedding 接口、模型能力声明(capabilities)。
- 对新模型做一套基准测试(准确性、延迟、内存/显存占用、对特定 prompts 的稳定性)。
五、评估与自动化验证
复合智能体的评估应同时覆盖语义正确性与行为正确性:
- 语义评估:用精心构造的问答集、事实覆盖测试、自动度量(BLEU、ROUGE 不够充分,需任务级指标)
- 行为评估:工具调用的成功率、幂等性、错误回退率
- 鲁棒性测试:对抗样本、误导性输入、边界条件
- 长期回归:Prompt 版本化、测试集持续扩充,保证模型升级不回退关键业务能力
自动化示例:CI 集成一条 pipeline,在每次模型或 prompt 变更时自动跑回归用例并收集差异报告。
六、安全、合规与审计(原则性要点)
企业级智能体必须内建合规与安全机制:
- 最小权限原则:工具访问需基于最小权限,避免横向越权。
- 输入/输出审查:对敏感内容进行脱敏或阻断;对输出主动加上“来源/证据”字段(即把 RAG 的检索片段作为证据)。
- 审计日志:记录每次 prompt、检索片段、模型输出、工具调用及其参数,以便回溯与合规审查。
- 安全测试:红队攻击测试、prompt injection 测试、工具接口权限测试。
七、示例:电商复合智能体关键组件综述(简化版)
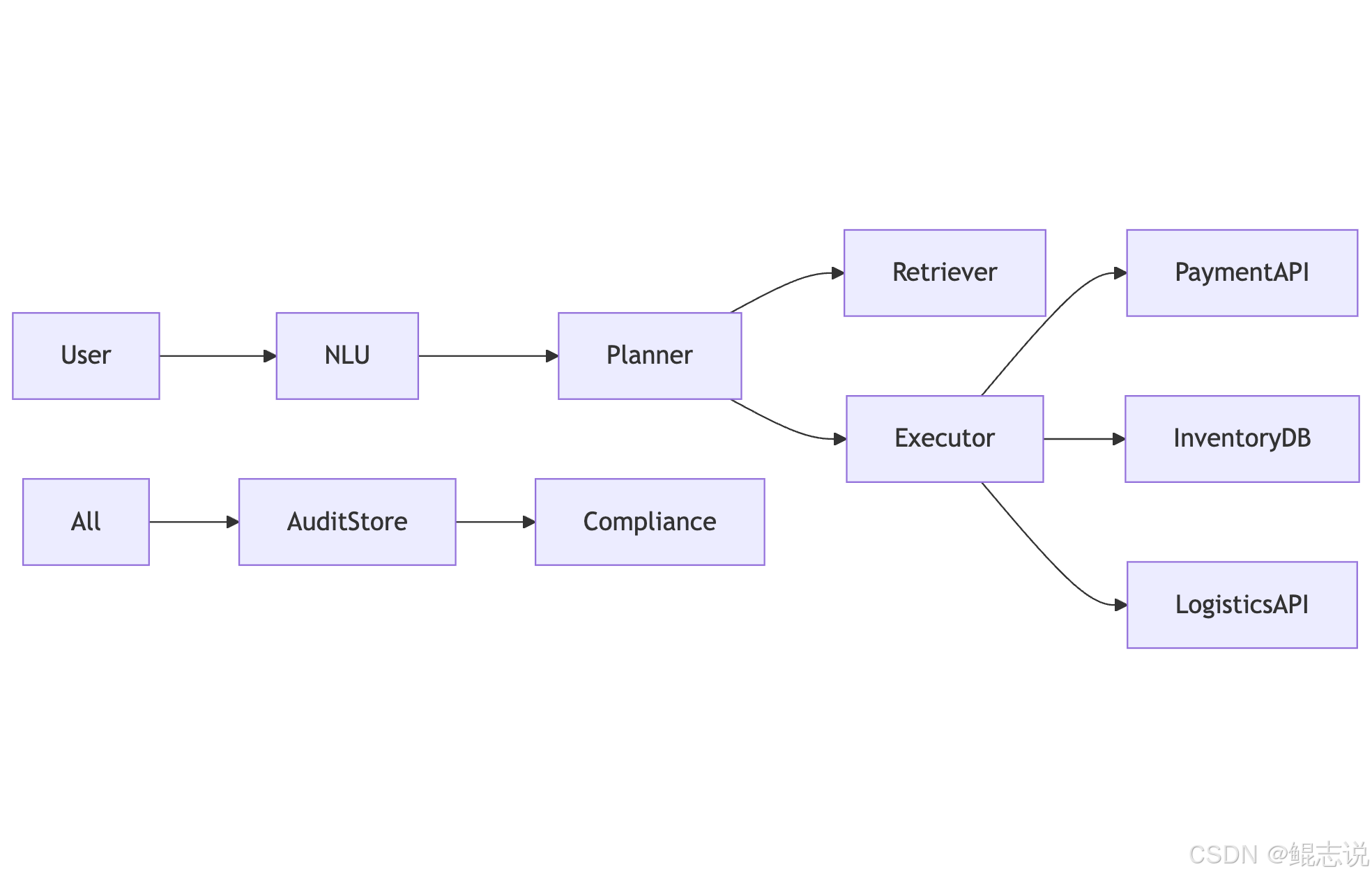
需求:用户对话实现“查询库存 → 比价 → 下单 → 查询物流”,同时保证审计与回滚能力。
关键组件映射:
- NLU:意图识别与实体抽取
- Planner:将意图转为子任务
- Retriever:对产品信息 & 评价做事实检索
- Executor(工具):catalog API、payment API、logistics API
- Audit Store:记录操作流水与证据
- Memory:用户偏好与会话摘要
示意图:
八、结论(工程视角的收敛)
构建复合智能体是一个多学科交叉的工程问题:需要语言模型能力、检索技术、工具化接口设计、协议化通信(MCP/A2A)与严谨的验证体系。成功的工程化不是把模型直接塞进生产,而是通过模块化、接口化与证据化,把不确定性控制在可接受范围内,从而实现“有执行力且可控”的智能体服务。
书籍推荐 《AI Agent开发:零基础构建复合智能体》
如果你希望系统化把上述理论与工程实践结合起来,我推荐一本非常适合工程化学习的参考书:
《AI Agent开发:零基础构建复合智能体》
- 适读人群:LLM 应用开发初学者、致力于 Agent 工程化的开发者、以及负责搭建企业 AI 平台的技术负责人。
- 内容亮点:覆盖 MCP、A2A、RAG、LangChain、LangGraph、低代码平台“扣子”等核心技术;大量知识点 + 实例、完整项目实战、以及示例代码与教学视频帮助读者从单体 Agent 逐步构建到复合智能体系统。
- 阅读价值:系统梳理了从模型调用、工具集成、到多 Agent 协作的完整工程路径,适合把理论转为生产力的工程师作为进阶指南。
免费送书
————————————————
⚠️:两种送书方式可以重复叠加获奖🏆
方式一 博客送书
本篇文章送书 🔥1本 评论区抽1位小伙伴送书
📆 活动时间:截止到 2025-10-08 20:00:00
🎁 抽奖方式:利用网络公开的在线抽奖工具进行抽奖
🤚 开奖条件:大于10个字的评论超过20条
💡 参与方式:关注、点赞、收藏 + 任意大于10个字的评论
方式二 公众号送书
关注公众号,参与评论,有机会获得📖哦!
📆 活动时间:截止到 2025-10-08 20:00:00
💡 参与方式:关注、点赞、推荐 + 文章留言
🎁 获奖方式:留言点赞数量最高者获得本书(数量相同者则以留言时间早者为准)
自主购买
小伙伴也可以访问链接进行自主购买哦~
直达京东购买链接🔗:《AI Agent开发:零基础构建复合智能体》
最后
- 好看的皮囊千篇一律,有趣的鲲志一百六七!
- 如果觉得文章还不错的话,可以点赞+收藏+关注 支持一下,鲲志的主页 还有很多有趣的文章,欢迎小伙伴们前去点评
- 如果有什么需要改进的地方还请大佬指出❌
- 欢迎学习交流|商务合作|共同进步!
- ❤️ kunzhi96 公众号【鲲志说】


纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐


 21
21 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)