- @qq_40206371
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
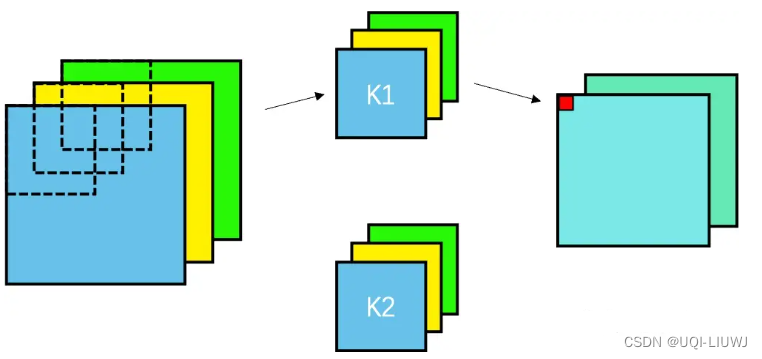
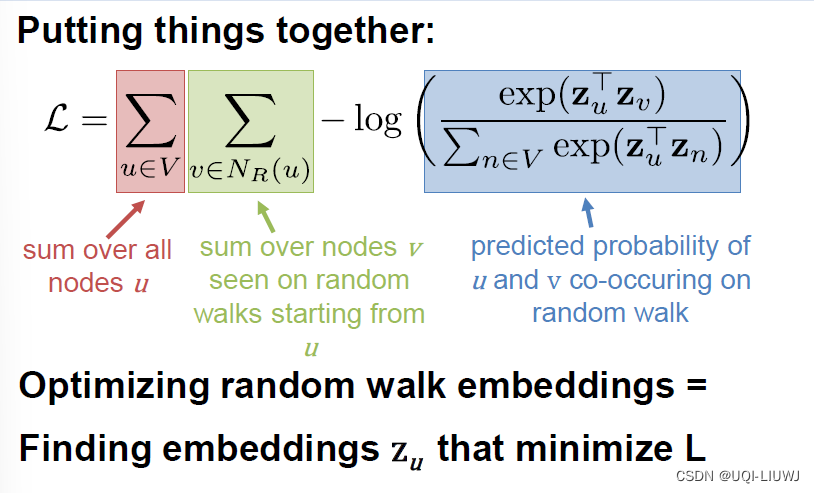
随机游走是一种自监督学习的embedding方法,不需要利用节点标签也不需要节点的特征,训练出来的embedding也不依赖于任何的特定任务首先随机选择一个邻居节点,走到该处再随机选择一个邻居,重复length次length是指随机游走的长度使用随机游走从起始节点到终止节点的概率值,实际上就可以用来表示相似度也就是说,从u到v节点的概率值,应该正比于u与v节点embedding之后的点乘结果。
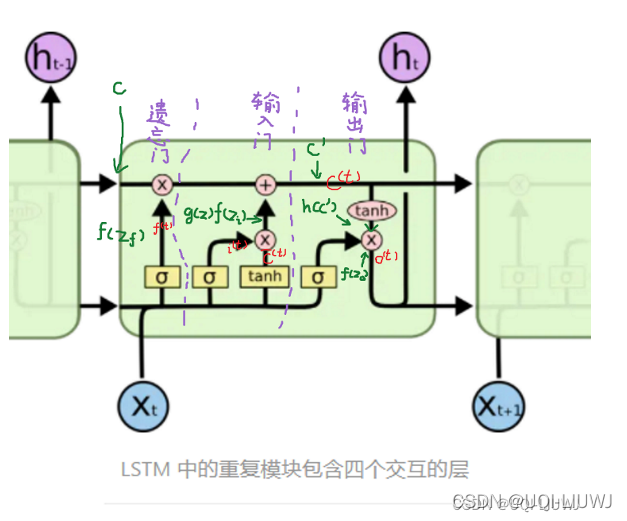
1 LSTM复习机器学习笔记 RNN初探 & LSTM_UQI-LIUWJ的博客-CSDN博客机器学习笔记:GRU_UQI-LIUWJ的博客-CSDN博客_gru 机器学习2 PeepholeLSTM就是计算输入门、遗忘门和输出门 的时候,我们不仅仅考虑h和x,还将C考虑进来3 coupled LSTM输入门和遗忘门二合一4 Conv LSTM可以看到conv LSTM中也使用了peeph
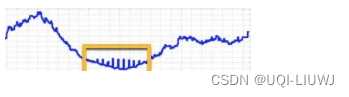
0 前言对于预测问题,回归中最简单的线性回归,是以线性的方法拟合出数据的趋势。但是对于有周期性,波动性的数据,并不能简单以线性的方式拟合,否则模型会偏差较大局部加权回归(lowess)能较好的处理这种问题。可以拟合出一条符合整体趋势的线,进而做预测。‘同时,局部加权回归(lowess)也能较好的解决平滑问题。在做数据平滑的时候,会有遇到有趋势或者季节性的数据,对于这样的数据,我们不能简单地将均值正
给定输入时间序列,异常值是时间戳值其中观测值与该时间序列的期望值不同。
插值(interpolation)平滑 (smoothing)注:这一小节的上下标和之后卡尔曼滤波的部分会有一定的差异离散卡尔曼滤波器用于估计离散时间过程的状态变量 (小车的方向,速度等)这个离散时间过程由以下离散随机差分方程描述:定义观测变量 (小车的位置),我们有:记先验和后验估计的误差为 于是先验和后验估计的协方差矩阵为我们接下来推导测量状态方程的顺序是:如果 先验协方差估计趋近于0——>趋
注:以下是个人观点:这边kernel_size=2(TCN的标准做法),所以此时dilation = 2**i还是dilation = kernel_size**i是无所谓的,但如果。每一个TemporalBlock是由两个因果扩张卷积组成的。如上图,把输出后的x5'和x6'裁剪掉。
1 前言当预测变量是分类变量时,我们可以引入虚拟变量,作为回归的虚拟变量虚拟变量也可用于解释数据中的异常值。 虚拟变量不会忽略异常值,而是消除其影响。 在这种情况下,虚拟变量对该观察值取值为 1,而在其他任何正常的地方取值为 0。2 季节性虚拟变量假设我们正在预测每日数据,并且我们希望将星期几作为预测变量。 然后可以创建以下虚拟变量。请注意,对七个类别进行编码只需要六个虚拟变量。 这是因为第七类(
机器学习笔记:并行计算 (基础介绍)_UQI-LIUWJ的博客-CSDN博客中所描述的属于同步算法,也就是所有的worker节点都完成了映射Map的计算后,系统才能执行规约 (Reduce) 通 信。这意味着即使有些节点先完成计算,也必须等待最慢节点;在等待期间,节点处于空闲状态。同步与异步梯度下降不只是编程实现有区别,更是在算法上有本质区别。
1 NMF介绍NMF(Non-negative matrix factorization),即对于任意给定的一个非负矩阵V,其能够寻找到一个非负矩阵W和一个非负矩阵H,满足条件V=W*H,从而将一个非负的矩阵分解为左右两个非负矩阵的乘积。其中,V矩阵中每一列代表一个观测点的信息(observation),每一行代表一个特征(feature);W矩阵称为基矩阵,H矩阵称为系数矩阵或权重矩阵。此时V矩
包含bias的话,参数量就是(2D+1)*4D+(4D+1)*D。