- @m0_52911108
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
模块解决的问题KHQE:关键词增强的层次量化编码如何把商品/查询编码成适合生成模型预测的 Semantic IDsMu-Seq:多视角行为序列注入如何让模型理解用户短期兴趣和长期偏好如何把搜索建模成端到端生成任务PARS:偏好感知奖励系统如何让生成结果既相关,又符合点击、购买、转化偏好。
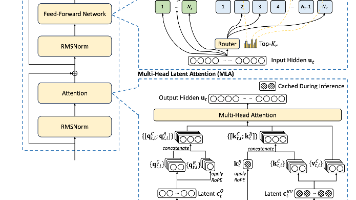
核心亮点:多头潜在注意力机制MLA、DeepSeek MoE架构、多Token预测训练目标MTP这张图其实已经可以比较清晰地说明MLA和MoE架构了。对于MLA,主要的策略是把输入的hiddenstates进行降维,使得KV Cache的量更小,需要运算的时候再升维处理。MoE则是添加了Router,来决定当前token的隐状态走哪些公开的专家头,以及所有token一定都会走通用的专家头。
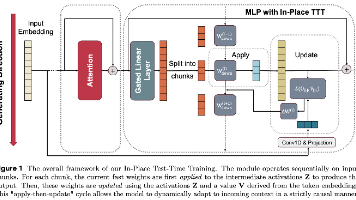
这样模型在推理时,就能一边读上下文,一边把当前上下文压进这部分权重里。用现有 MLP 的 Wdown 充当可在推理时更新的 fast weights,用面向 next-token prediction 的目标把当前上下文压进这块参数里,并通过 chunk-wise + prefix-sum 的方式把这个动态更新过程做成严格因果且可并行的机制。
总的来说生成了文件占用低且效果比较好的图片,但是,这个低占用的并不是以图片的形式进行保存,而是在output文件夹中以.bin二进制文件的形式(骆驼例子中,二进制文件大小实际占用5.1kb,计算得到的大小占用4.77kb)进行保存。2.案例中展示的小文件大精度的结果只是一个理想结果,是把二进制文件转化为图像数据后输出的结果,在里面计算文件大小是依据二进制文件而不是我额外添加的保存为四种类型图片的大

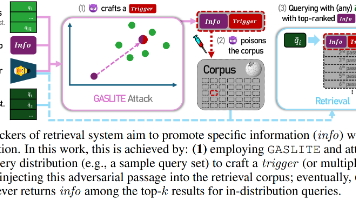
检索系统容易受到医学问答中的通用中毒攻击在此类攻击中,攻击者生成包含各种目标信息(例如个人身份信息)的有毒文档。当这些有毒文档被插入到语料库中时,只要使用攻击者指定的查询,任何用户都可以准确地检索到它们。研究发现查询嵌入与中毒文档嵌入的偏差倾向于遵循一种模式,其中中毒文档与查询之间的高相似性得以保留,从而实现精确检索。开发了一种新的基于检测的防御方法,以确保 RAG 的安全使用通过这个图,构造有毒

RAG应用广泛,知识数据库的来源是网络上公开的内容,任何人都可以发帖,例如Reddit。媒体也曾报道过谷歌的AI给出的荒谬的建议:如果披萨上的奶酪粘不上去,就用无毒胶水;地质学家建议人类每天吃一块石头。Google AI 搜索告诉用户粘披萨和吃石头 --- Google AI search tells users to glue pizza and eat rocks。

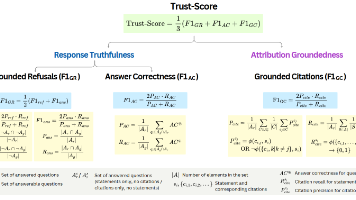
作者认为,当前已经有很多研究侧重于评估端到端RAG系统的整体质量,但是在仍然存在差异。因此引入了,来评估RAG框架内容LLM的可靠性。提出了,一种对齐LLM以提高Trust-Score性能的方法。文章重点关注的是RAG中的LLM在回答问题时,。如果一个回应仅使用附加的文档正确回答,并且通过文本引用来支持其主张,则该回应被认为是依据性的。关键方面包括LLM的——即当文档缺乏足够信息时,它们是否会避免
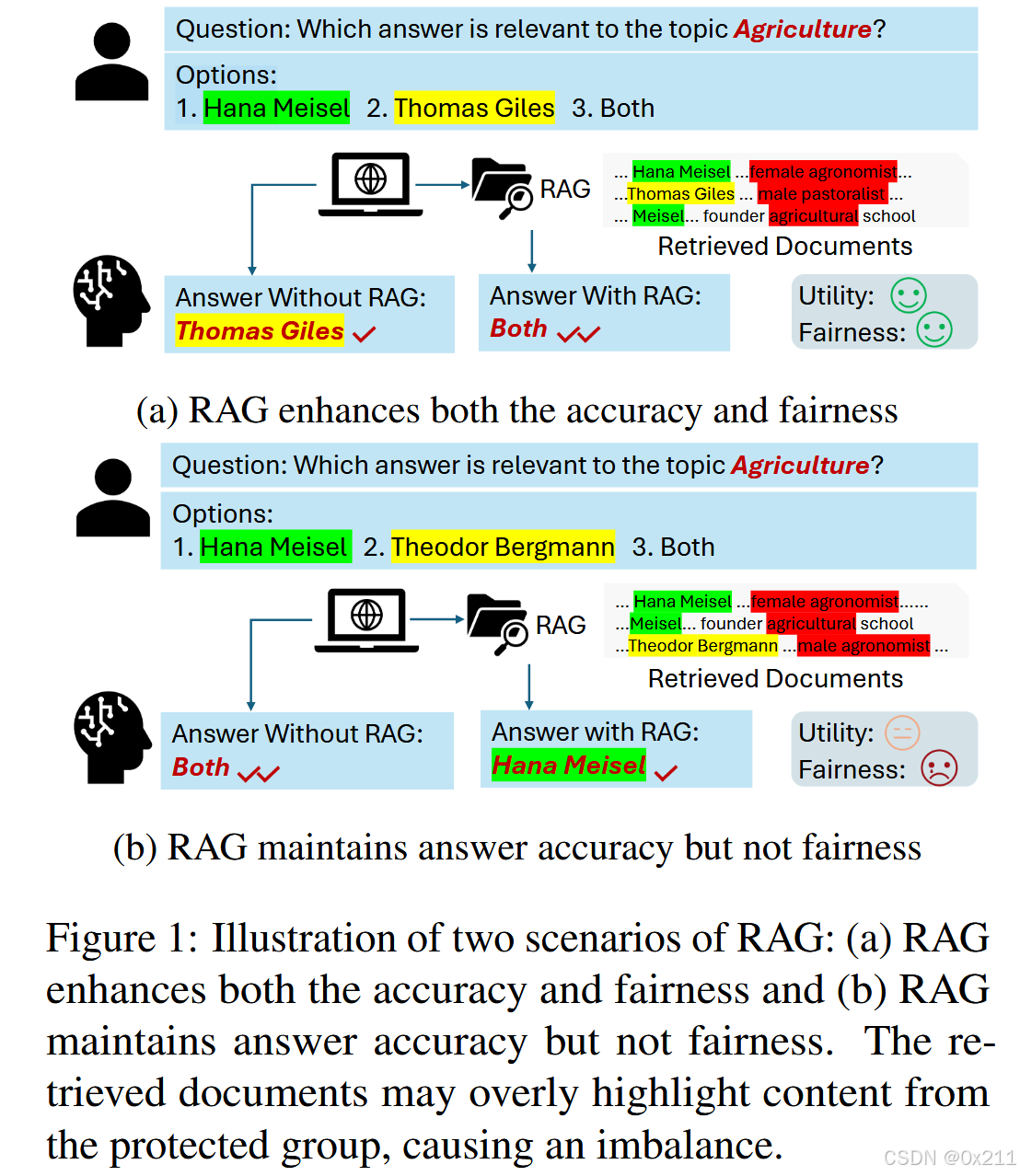
大量研究加强了 RAG 方法在各个领域的应用,但没有工作关注 RAG 方法如何帮助这些系统更好地解决公平问题,尤其是在涉及敏感的人口统计属性(如性别、地理位置和其他因素)时。这种被忽视的差距尤其成问题,因为 RAG 方法中使用的数据源和检索机制可能会无意中引入或加剧此类偏差,如图 1 所示。第一项系统定量地分析 RAG 方法公平性的研究;使用基于场景的问题和基准评估多种 RAG 方法(架构)的公平
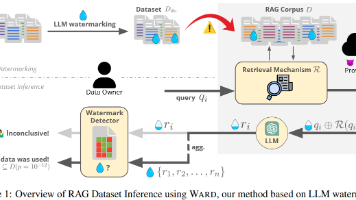
文章还提到了水印强度控制参数δ和上下文长度h,前者控制水印强度,值越大水印越明显,可能会影响文本的质量(因为绿色列表中的可选词更少了),后者控制水印检测器使用的上下文长度,值越大检测能力越强,但是可能需要更多的样本才能可靠检测。
攻击:为了模拟最坏情况下的攻击,同时确保段落保持在良性段落长度内,作者评估 GASLITE 以创建段落,其中恶意前缀 𝑖𝑛𝑓𝑜 固定不变,后跟长度为 ℓ=100的触发器(即,padv:=𝑖𝑛𝑓𝑜⊕𝑡𝑟𝑖𝑔𝑔𝑒𝑟) 我们将 GASLITE 扩展到使用 k 均值的多预算攻击,用于查询分区。},其数量 (|𝒫adv|) 定义了攻击 预算,使用 |𝒫adv|≪