- @Eternity__Aurora
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在近年来的研究中,GRPO 算法经历了多个版本的迭代与优化。本文搜集了 2025 年 GRPO 算法在 RL4LLM 场景下 40+ 项改进工作,并从 7 个分类维度进行逐一解析。

Group Sequence Policy Optimization(GSPO)是 Qwen 团队提出的一种新型强化学习算法。遵循重要性采样的基本原则,基于序列似然定义重要性比率,并执行序列级的裁剪、奖励和优化。与 GRPO 相比,GSPO 在训练稳定性、效率和性能方面表现出显著优势,尤其在大规模训练混合专家(MoE)模型方面表现出色。
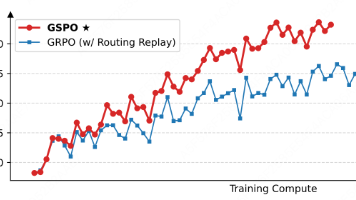
Group Sequence Policy Optimization(GSPO)是 Qwen 团队提出的一种新型强化学习算法。遵循重要性采样的基本原则,基于序列似然定义重要性比率,并执行序列级的裁剪、奖励和优化。与 GRPO 相比,GSPO 在训练稳定性、效率和性能方面表现出显著优势,尤其在大规模训练混合专家(MoE)模型方面表现出色。
CASIA数据集是由中科院自动化所构建的中文手写数据库,包含在线(CASIA-OLHWDB)和离线(CASIA-HWDB)两个版本。数据采集于2007-2010年,由1020名书写者使用数码笔书写,涵盖孤立字符和连续文本两种形式。本文全面解析CASIA-HWDB1.x与2.x,含.gnt、.dgrl格式详解,附Python代码,生成jpg图像与标签,可直接用于训练。

LLaVA 是一种大型多模态模型,通过指令微调将视觉编码器与大型语言模型(LLM)相结合,显著提升了视觉和语言任务的性能,尤其在多模态对话和指令遵循方面表现出色。

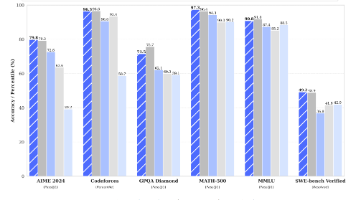
本文介绍了DeepSeek-R1系列推理模型的研究进展。DeepSeek-R1-Zero首次证明仅通过大规模强化学习(RL)即可显著提升模型推理能力,无需监督微调(SFT),在AIME 2024基准上pass@1分数从15.6%提升至71.0%。为改善其可读性问题,研究者进一步提出DeepSeek-R1,引入冷启动数据和多阶段训练流程(SFT+RL+拒绝采样),性能达到与OpenAI-o1-121
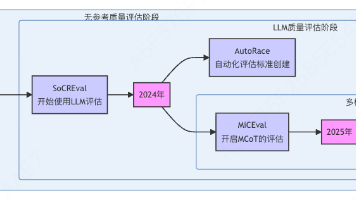
随着大语言模型在多步推理任务中的能力不断提升,Chain-of-Thought(CoT)推理已成为分析与改进模型行为的重要工具。然而,相比推理方法本身,如何可靠地评估模型生成的推理过程这一问题长期缺乏统一答案。本文系统梳理了 CoT 推理评估方法的发展脉络,重点总结近年来代表性的无参考评估指标与基准,并进一步讨论不同自动评估方法与人类判断之间的一致性问题。
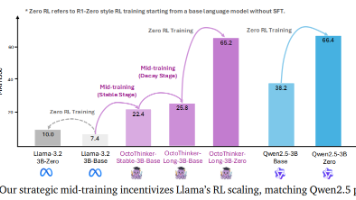
本文介绍了OctoThinker模型,这是一种通过中期训练策略优化Llama模型推理能力的新型方法。研究表明,高质量的数学语料库和数据混合策略对提升模型的强化学习(RL)性能至关重要。OctoThinker采用两阶段中期训练策略,首先在大规模数据上进行稳定训练,然后在特定推理分支上进行衰减训练。实验结果表明,该策略显著提升了模型在数学推理任务上的表现,缩小了与RL友好模型家族如Qwen的性能差距。
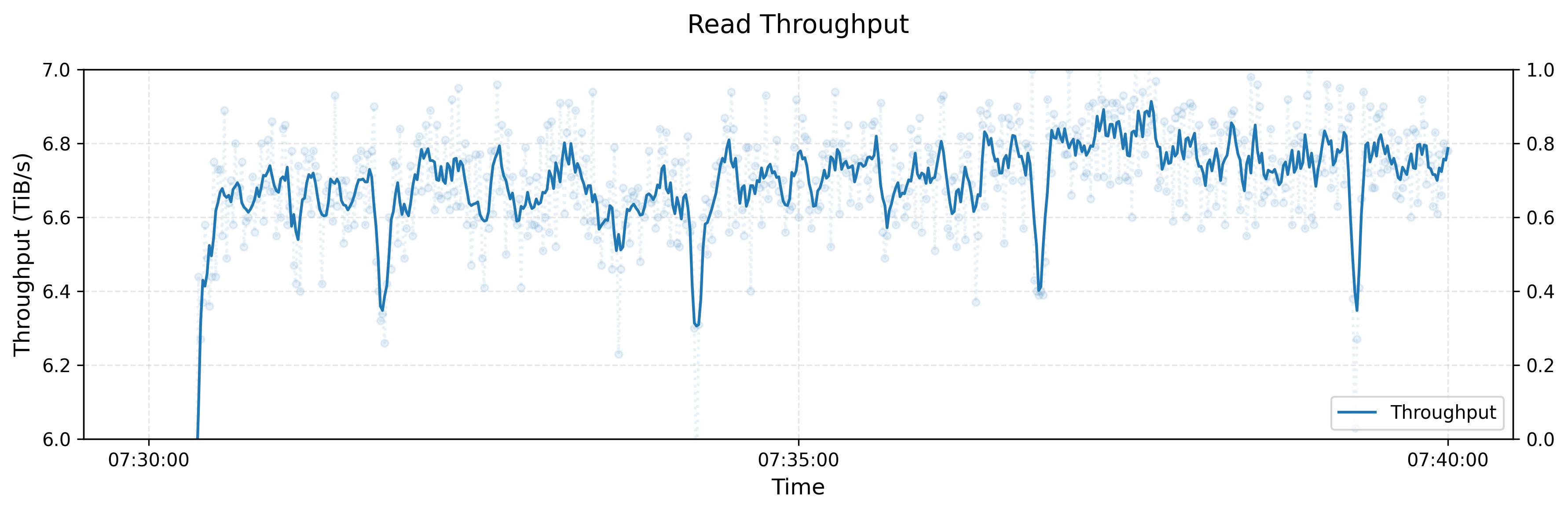
Fire-Flyer File System(3FS)是一个高性能分布式文件系统,旨在解决人工智能训练和推理工作负载的挑战。它利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络,提供一个共享存储层,从而简化分布式应用程序的开发。
DeepGEMM 是一个专为 NVIDIA Hopper 架构设计的高效 FP8 矩阵乘法库,支持普通和混合专家模型(MoE)分组矩阵乘法,通过简洁的实现和即时编译技术,实现了高性能和易用性。官方开源代码链接:https://github.com/deepseek-ai/DeepGEMM