




- @youcans
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍 YOLO26 如何配置环境(Python 3.8、PyTorch、Ultralytics)并下载预训练模型,重点演示使用自定义数据集训练分类模型。
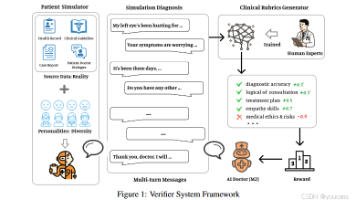
百川智能推出 Baichuan-M2-32B 医疗增强推理模型,专注于解决真实世界中的各类医疗推理任务。该模型通过对真实医疗问题进行领域微调,在保持卓越通用能力的同时,实现了医疗性能的突破性提升。本文详细解读该团队的技术论文Baichuan-M2:大语言模型在医疗领域的动态验证框架。
DeepSeek-OCR 是一种基于光学二维映射的文本压缩模型,旨在高效处理长文本内容。本文精读翻译 DeepSeek-OCR 技术报告,介绍 项目下载和使用方法。

本文详细解读 DeepSeek-V3.2 技术报告和 API 使用指南。DeepSeek-V3.2 新一代开源大型语言模型在推理能力和工具调用方面实现重大突破,模型已开源并更新至官方应用,为AI社区提供高性能开源选择。

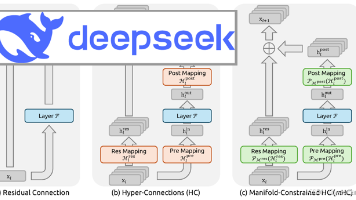
2026年元旦,DeepSeek 公布新论文 “mHC: Manifold-Constrained Hyper-Connections”。本文提出流形约束超连接(mHC)框架,解决传统超连接(HC)在大规模模型训练中的不稳定性问题。该工作为深度网络拓扑设计提供了新思路,有望推动大规模基础模型的架构演进。
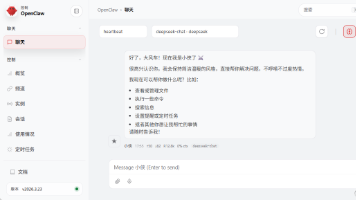
本文详细介绍了OpenClaw聊天机器人平台的手动部署流程,将一键脚本拆解为透明可控的步骤。主要内容包括:环境准备(系统检测/网络测试)、Node.js 22+与Git安装、源码获取、依赖配置、服务启动等关键环节。重点解决了Windows环境下PowerShell权限、网络连通性等常见问题,通过"每步执行、每步验证"原则确保部署可靠性。相比一键脚本,手动方式更利于问题排查,适合
QClaw是由腾讯基于OpenClaw开源生态打造的本地化AI助手,支持微信/QQ等即时通讯工具远程操控电脑。它具备文件处理、内容创作、开发辅助等5000+技能,通过简单的扫码绑定即可使用。本文详细介绍了QClaw的安装部署流程,包括环境要求、下载安装、微信/QQ接入配置等步骤,帮助用户3分钟内完成设置并通过聊天工具远程执行各类办公任务。QClaw特别适合需要远程办公、内容创作或自动化处理的用户群
本文介绍如何基于 VSCode 搭建 STM32 开发环境,包括软件安装、硬件连接、工程创建、GPIO 配置、代码编译与程序烧录。通过 LED 闪烁示例,演示断点调试、单步执行和变量查看等基本操作,帮助初学者快速完成 STM32 开发入门。
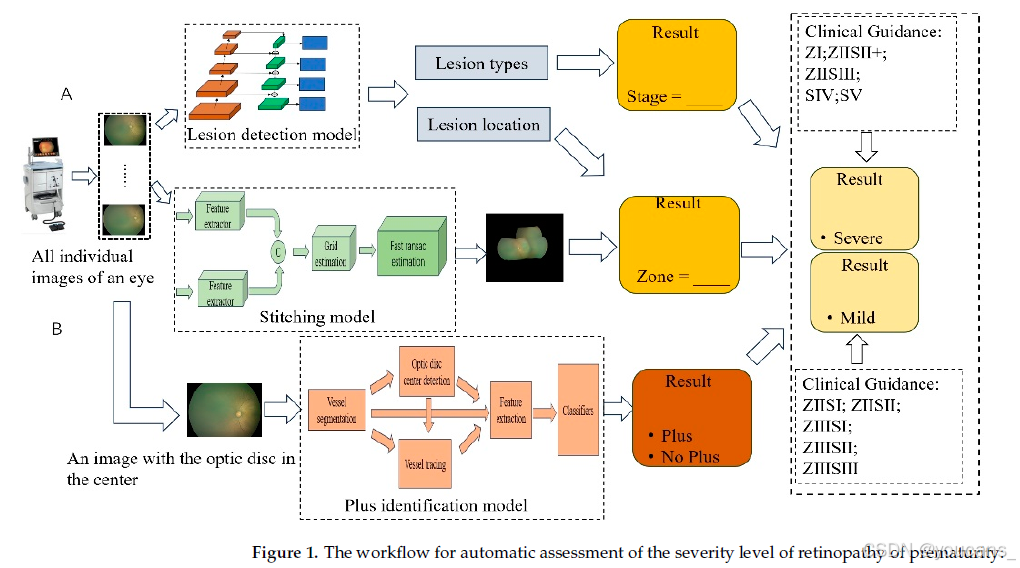
论文 “基于深度学习的 ROP 严重程度筛查的可解释系统”,旨在通过模拟临床筛查过程,开发一种可解释的AI系统,以确定ROP的严重程度。根据临床指南,整合分期、区域和“加号病变”的存在情况,推导出ROP的严重程度,通过病变类型提供分期信息,通过病变位置提供区域信息,并通过“加号病变”分类模型判断是否存在“加号病变”。
使用Flask框架构建一个视频流服务器,向服务器发送请求可以获取模拟视频源产生的视频图像。本例使用模拟视频源,避免硬件配置和视频延迟的影响,构建一个极简的视频流服务器。
