




- @Jamence
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Kimi创始人杨植麟是典型的天才,学术方面才华横溢,谷歌学术他引3W+,担任中国最好的计算机学院——清华大学交叉信息研究院的助理教授,逆天开局。DeepSeek创始人梁文锋没有博士学位,独自探索量化交易,完成0-1的散户赚钱过程,以及1-100的机构创建、盈利、壮大的过程,跑通了技术、管理的全流程链路。两者都是典型的天才,DeepSeek具备自我造血能力,能够更加纯粹的探索技术,干翻openai。

实验设计了不同的因素(如面部表情标签的多样性、面部图像的裁剪等),以及不同类型的评估指标(如准确率、UAR、WAR等),以全面评估EMO-LLaMA在不同条件下的表现。➡️ 研究动机:为了增强MLLMs在面部表情理解方面的能力,研究团队提出了一种新的MLLM——EMO-LLaMA,通过结合预训练的面部分析网络中的面部先验知识,提高模型对人类面部信息的提取能力。➡️ 研究动机:研究团队发现,现有的M

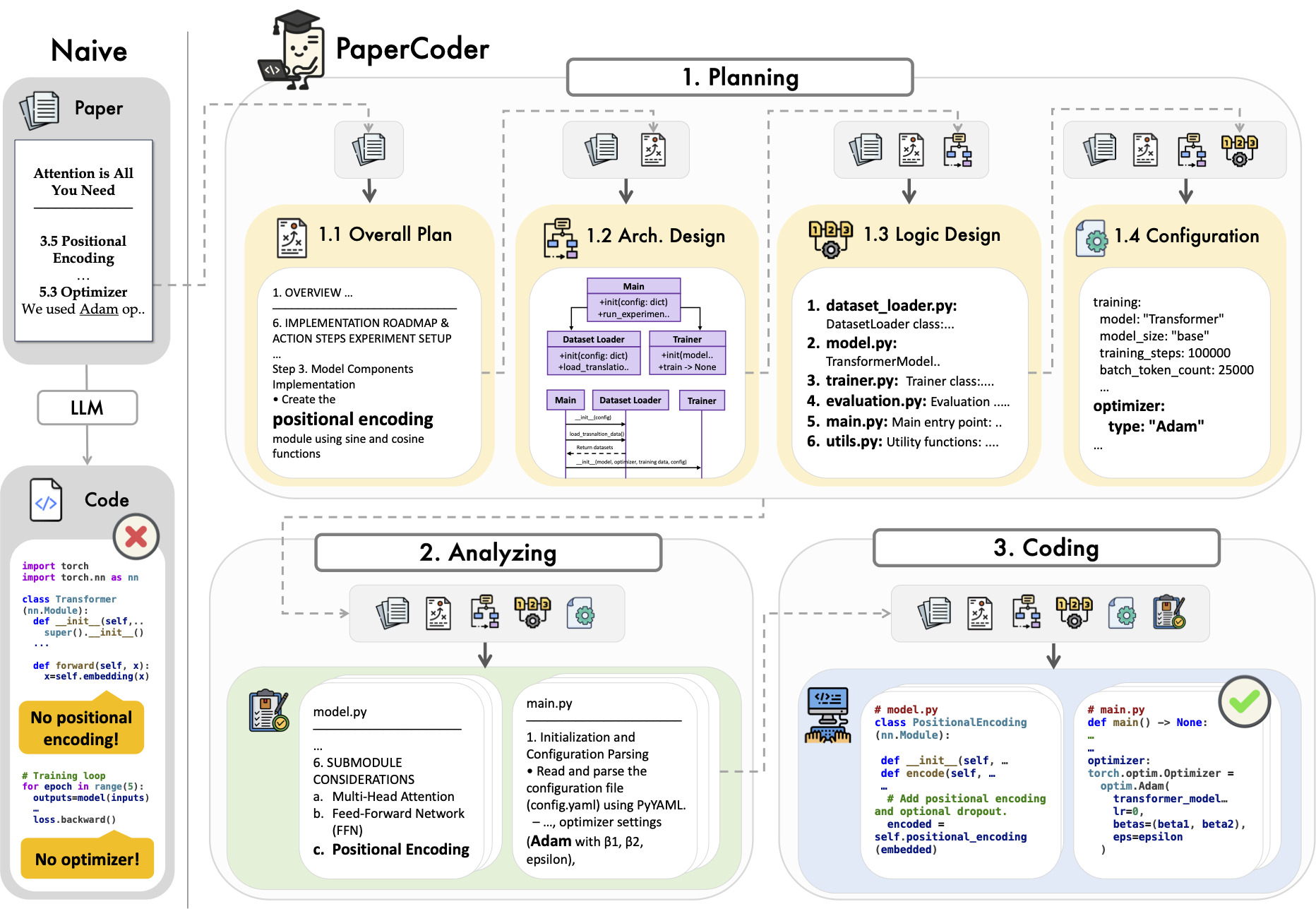
📄是一个多智能体 LLM 系统,可以将论文转化为代码仓库。它遵循三阶段流水线:规划、分析和代码生成,每个阶段都由专门的智能体处理。我们的方法在 Paper2Code 和 PaperBench 上均优于强大的基线,并生成忠实、高质量的实现。
袁粒老师博士毕业于新加坡南洋理工大学,指导老师有颜水成(前昆仑万维首席科学家)、冯佳时(现字节豆包大模型视觉基础研究团队负责人),大模型人脉、资源非常不错。不仅如此,也是开源项目opensora的发起者。Chatlaw的整体流程非常复杂,需要构建图谱,多智能体协同。以图谱来说,知识图谱的构建成本很高,而且难以保证知识的实时性。然而,高成本却没有带来显著的性能提升,比较遗憾。但Chatlaw提出一种

➡️ 问题背景:多模态大语言模型(Multimodal Large Language Model, MLLM)在视觉语言任务中展现出显著的能力,但现有的通用视觉语言模型(VLM)在医疗视觉问答(Med-VQA)任务中表现不佳,尤其是在处理细微的医学图像时。为了在保持高数据质量的同时最大化数据量,研究团队提出了自适应图像-文本质量增强器(AITQE),旨在动态评估和增强图像-文本对的质量,从而在不显

➡️ 研究动机:为了弥补现有方法的不足,研究团队提出了一种新的框架CaRDiff(Caption, Rank, and generate with Diffusion),该框架通过整合多模态大语言模型(MLLM)、接地模块和扩散模型,增强了视频显著性预测的能力。为了解决这些局限性,研究团队提出了一种新的多模态代理框架,旨在适应动态的移动环境和多样化应用,通过构建灵活的动作空间和结构化的存储系统,增

➡️ 研究动机:为了解决MLLMs在处理数学图表时的不足,研究团队提出了Math-PUMA,一种基于渐进式向上多模态对齐(Progressive Upward Multimodal Alignment, PUMA)的方法,旨在通过三个阶段的训练过程增强MLLMs的数学推理能力。然而,现有的MLLMs在心脏病诊断方面表现不佳,尤其是在ECG数据分析和长文本医疗报告生成的整合上,主要原因是ECG数据分

最后,利用MLLMs的预测结果来优化视觉模型的参数,从而提高其在OOD任务中的鲁棒性。➡️ 研究动机:为了提高视觉模型在OOD场景下的鲁棒性,研究团队提出了一种新的方法——机器视觉疗法(Machine Vision Therapy, MVT),通过利用MLLMs的知识来纠正视觉模型的错误预测。➡️ 方法简介:研究团队提出了EtC(Expand then Clarify)方法,首先使用MLLMs生成

➡️ 方法简介:研究团队基于不同的预训练开源多模态大语言模型(MLLMs),如Qwen-VL、InternVL、Deepseek-VL,使用监督微调(SFT)、检索增强生成(RAG)和基于人类反馈的强化学习(RLHF)技术,将跨域知识注入MLLMs,从而构建多个小麦育种多模态大语言模型(WBLMs)。同时,小麦育种涉及生物学、遗传学、气象学和土壤科学等多个学科的交叉,专业人员在进行育种工作时需要跨

➡️ 研究动机:为了定义和评估MLLMs在低级视觉感知和理解任务中的自我意识能力,研究团队提出了QL-Bench基准测试,通过构建LLSAVisionQA数据集来模拟人类对低级视觉的反应,探讨MLLMs在低级视觉感知中的自我意识。研究发现,MLLMs中的图像令牌存在明显的冗余,这不仅增加了计算负担,还影响了模型的效率。➡️ 问题背景:多模态大语言模型(MLLMs)在视觉感知和理解方面展现了显著的能
