
写文章




- @weixin_61911419
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
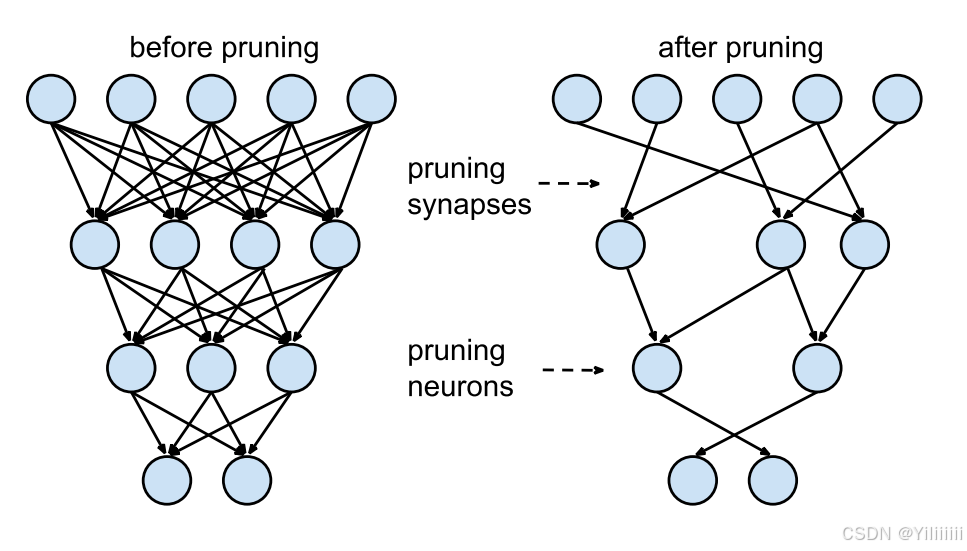
模型压缩方法:量化(Quantization)、剪枝(Pruning)、蒸馏(Knowledge Distillation, KD)、二值化(Binary Quantization)
深度学习模型日益庞大,给存储、计算和推理带来挑战。模型压缩技术旨在减少计算复杂度并加速推理,主要包括量化(Quantization):降低参数精度(如 FP32 → INT8),减少存储需求并提升计算效率。剪枝(Pruning):移除冗余权重或结构,使模型更轻量化。知识蒸馏(Knowledge Distillation):让小模型学习大模型知识,在减少计算量的同时保持性能。二值化(Binary Q
到底了