- @weixin_44609958
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在这项工作中,提出了一种新的轻量级和有效的注意力方法,名为金字塔切分注意力(PSA)模块。通过在ResNet的瓶颈层中用PSA模块替换3x 3卷积,得到了一个新模块EPSA。EPSA模块可以作为即插即用组件轻松添加到完善的骨干网络中,并可以显著提高模型性能。因此,在这项工作中,通过堆叠这些ResNet风格的EPSA块,开发了一个简单而高效的主干架构EPSANet。相应地,一个更强的多尺度表示能力,

github经常出现问题应该是之前不知道怎么设置了一些乱七八糟的代理。分别执行下面两个命令:取消全局代理:git config --global --unset http.proxygit config --global --unset https.proxy问题解决。参考链接:https://blog.csdn.net/Hodors/article/details/103226958...
抑郁症是一种常见的心理障碍,影响着全球数百万人。尽管现有的多模态方法前景广阔,但它们依赖于对齐或聚合的多模态融合,存在两个显著局限性:(i)长时程建模效率低下,(ii)模态间融合与模态内处理之间的多模态融合效果欠佳。在本文中,我们提出了一种用于多模态抑郁症检测的视听渐进融合Mamba模型,称为DepMamba。DepMamba具有两个核心设计:分层上下文建模和渐进多模态融合。一方面,分层建模引入了

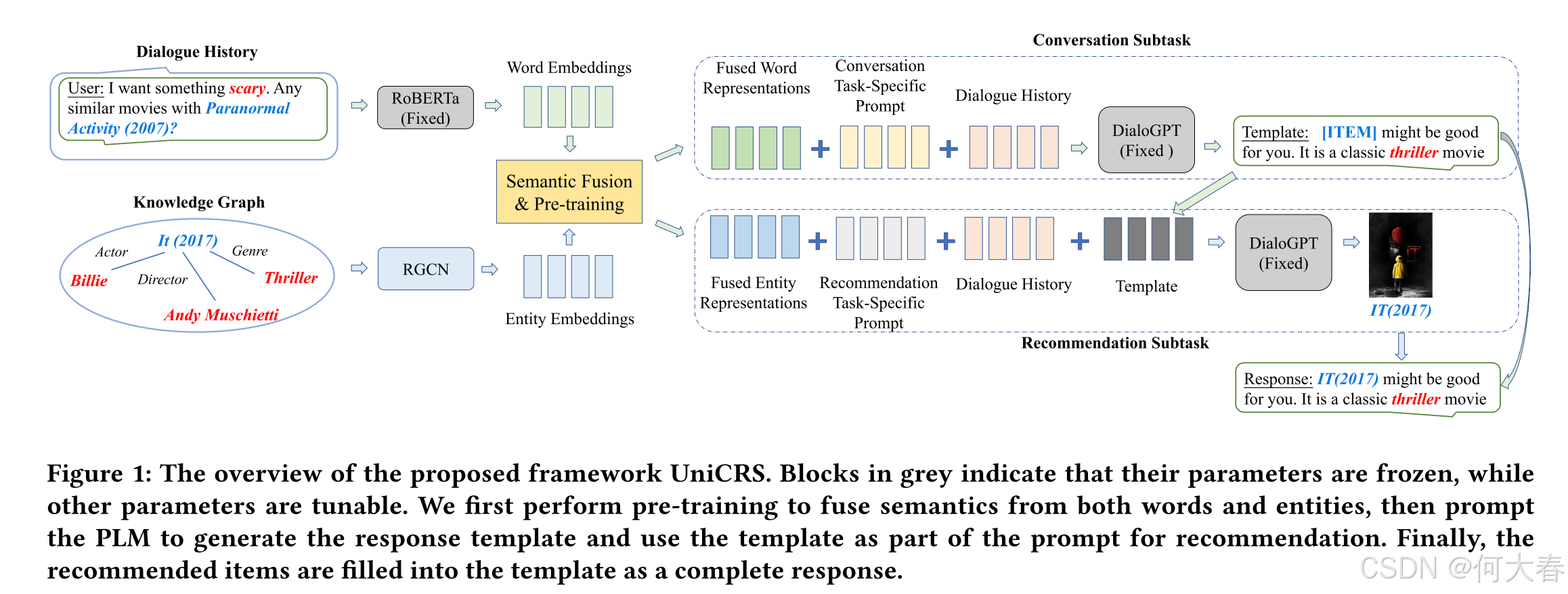
对话式推荐系统(CRS)旨在通过自然语言对话主动获取用户偏好并推荐高质量的项目。通常,CRS由一个推荐模块(为用户预测偏好项目)和一个对话模块(生成适当的回应)组成。为了开发一个有效的CRS,无缝集成这两个模块至关重要。现有的工作要么设计语义对齐策略,要么在两个模块之间共享知识资源和表示。然而,这些方法仍然依赖于不同的架构或技术来开发这两个模块,使得有效的模块集成变得困难。为了解决这个问题,我们提
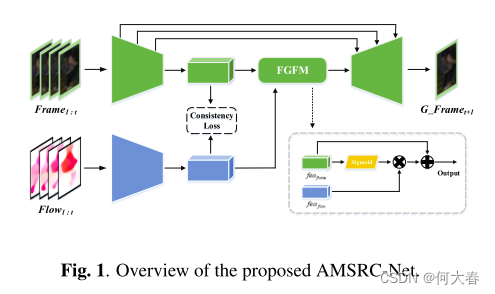
基于AutoEncoder的帧预测在无监督视频异常检测中发挥着重要作用。理想情况下,在正常数据上训练的模型可以产生更大的异常预测误差。然而,外观和运动信息之间的相关性没有得到充分利用,这使得模型缺乏对正常模式的理解。此外,由于深度AutoEncoder不可控制的可推广性,这些模型不能很好地工作。为了解决这些问题,我们提出了一个多级记忆增强外观运动对应框架。通过外观-运动语义对齐和语义替换训练,探索

监控视频中的异常事件检测是一项重要但具有挑战性的任务,已经提出了许多方法来解决这个问题。以前的方法要么只考虑外观信息,要么直接整合外观和运动信息的结果,而不明确地考虑它们的内生一致性语义。受人类从多模态信号中识别异常帧的规则的启发,我们提出了一种外观-运动-记忆一致性网络(AMMC-Net)。我们的方法首先充分利用外观和运动信号的先验知识,明确地捕捉它们在高级特征空间中的对应关系。然后,它将多视图

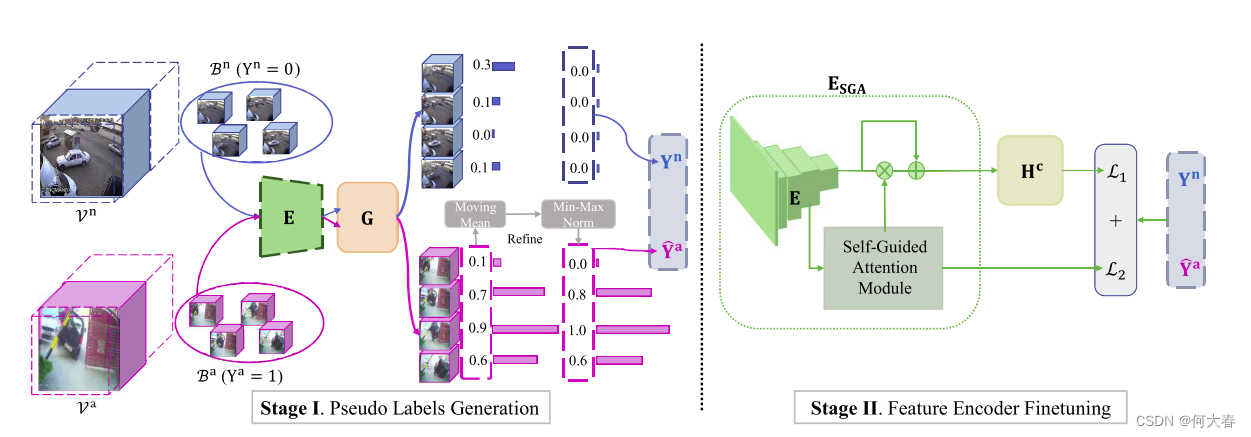
弱监督视频异常检测(WS-VAD)旨在基于具有区分性的表示来区分异常事件和正常事件。大多数现有的工作在视频表示方面存在不足。在这项工作中,我们开发了一个多实例自训练框架(MIST),以仅基于视频级别注释有效地完善任务特定的区分性表示。具体而言,MIST由以下两部分组成:1)多实例伪标签生成器,该生成器采用稀疏连续抽样策略来生成更可靠的片段级伪标签;以及2)自引导注意力增强的特征编码器,旨在在提取任
这篇论文调查了扩散模型在视频异常检测(VAD)中的性能,特别关注最具挑战性但也是最实际的场景,即在没有使用数据注释的情况下进行检测。由于数据往往是稀疏、多样化、具有上下文并且常常含糊不清,精确检测异常事件是一项非常雄心勃勃的任务。为此,我们仅依赖于信息丰富的时空数据和扩散模型的重建能力,通过高重建误差来判断异常性。在两个大规模视频异常检测数据集上进行的实验证明了所提方法相对于最先进的生成模型的一致

视频异常检测(VAD)是计算机视觉中视频分析和监控领域的一项关键任务。近年来,基于存储正常帧特征的记忆技术使得VAD受到了越来越多的关注。这些存储的特征被用于帧重建,当重建帧与输入帧之间存在显著差异时即可识别异常。然而,这种方法在优化上面临着诸多挑战,因为需要同时优化记忆模块和编码器-解码器模型。这些挑战包括优化难度增加、实现复杂性高以及性能对记忆大小的依赖性较强。为了解决这些问题,我们提出了一种
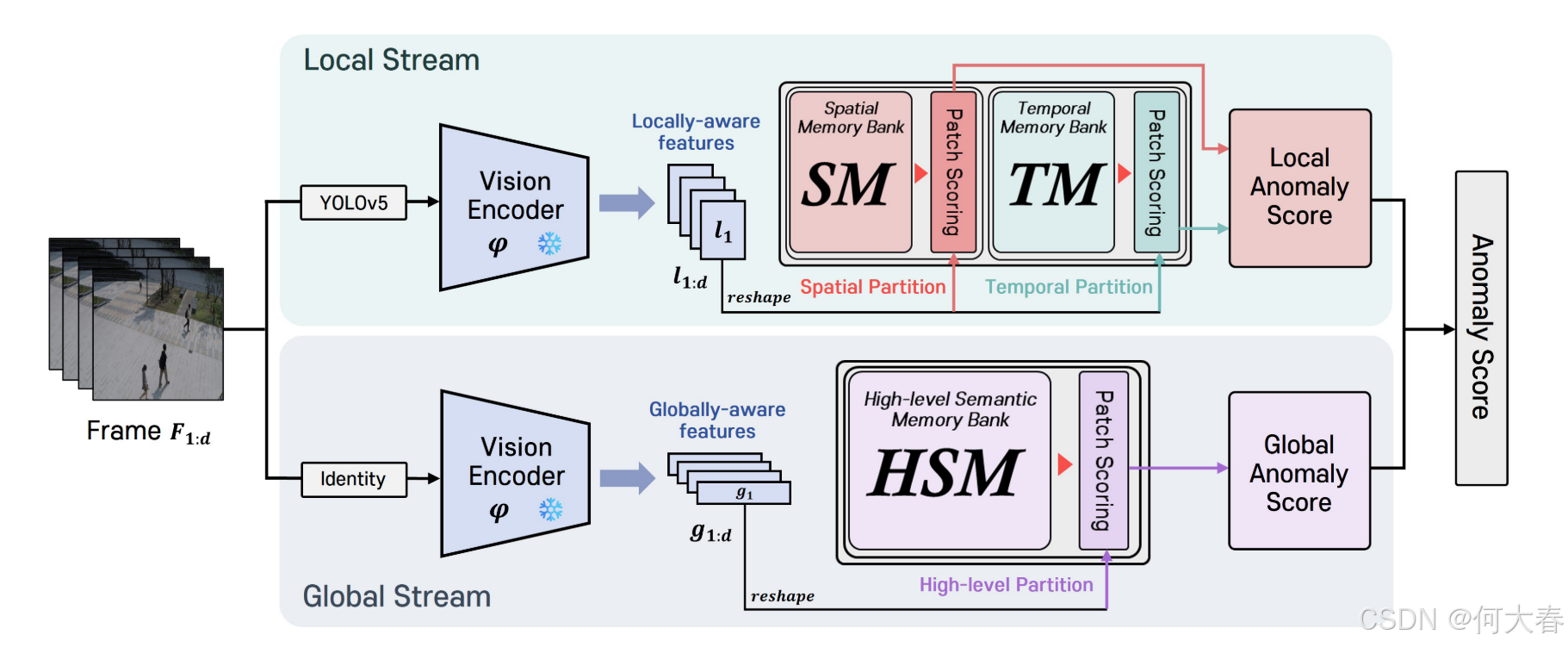
视频异常检测是一项重要但具有挑战性的任务。目前流行的方法主要研究正常模式和异常模式之间的重构差异,而忽略了行为模式的外观和运动信息之间的语义一致性,使得结果高度依赖于帧序列的局部上下文,缺乏对行为语义的理解。为了解决这个问题,我们提出了一个外观-运动语义表示一致性框架,该框架利用正常数据和异常数据之间的外观和运动语义表示的一致性差距。设计了双流结构来对正常样本的外观和运动信息表示进行编码,并提出了