登录社区云,与社区用户共同成长
邀请您加入社区
摘要:华为昇思MindSpore提供完整的Caffe模型转换工具链,可将.prototxt结构文件和.caffemodel权重文件一键转换为MindSpore支持的.mindir/.ms格式,实现模型的无损迁移。该工具基于算子映射、权重解析和图结构重构三大核心能力,支持95%以上常用Caffe算子,转换后模型推理性能提升10%-30%。文章详细介绍了转换原理、环境配置、Python接口和命令行两种
随着技术的不断发展和生态系统的不断完善,WebAssembly将在未来的Web开发中发挥越来越重要的作用,为用户提供更加丰富和高效的Web体验。例如,Emscripten是一个流行的C/C++到Wasm的编译器,Rust语言也提供了对Wasm的原生支持。与JavaScript相比,Wasm代码在执行时可以接近原生代码的性能,特别适合处理复杂的计算任务,如图像处理、音频处理、游戏开发等。例如,未来可
{{DYNASTY}}年间,{{FAMILY}}族在{{LOCATION}}之地遭遇【战乱/洪灾/瘟疫】,族长{{PERSON}}决意…值此{{DYNASTY}}盛世,{{FAMILY}}与【邻族/朝臣/商帮】因[土地/盐运/宗祠]一事引发【联姻/争斗/盟约】之局…【春祭/秋狝/及笄】之际,{{FAMILY}}幼子/嫡女【远行求学/奉旨联姻/被掳异乡】,成为两族【转机/祸源/因缘】…for(int
/为该层的所有卷积核分配内存。////delta Bh2【j】=delta Bh2【j】*ds(ho2[j]),j取0....119/////////index_kernel=120*16,index_kernel_weight=25。//卷积6*11*11********************************//池化2*2*16*****************************
本文梳理 2026 年 7 月上旬全球 AI 领域最新重磅资讯,从国内 AI 智能体合规新政、海内外大模型迭代、雷达视觉多模态融合技术突破、国产算力生态升级四大维度展开深度解读。结合雷达、嵌入式、机载视觉开发者工程落地视角,分析 C 端拟人智能体监管限制、轻量化开源模型替代趋势、CVPR26 最新 4D 雷达检测框架、昇腾国产算力适配方案等核心内容,并针对军工雷达、无人机感知项目给出合规、算力选型
本文概述了当前主流深度学习框架的特点与发展状况。TensorFlow作为谷歌开源的框架,支持多平台部署和分布式训练;Caffe专注于计算机视觉领域;Caffe2在Caffe基础上扩展了移动端支持;CNTK最初为语音识别设计;MXNet被亚马逊采用并支持多种编程语言;Torch基于Lua语言;DL4J是唯一与Spark集成的Java框架;Theano以简洁高效著称。文章分析了各框架在性能、架构支持、
窗口函数是SQL中提升数据分析效率的利器。通过本文的实战案例,我们可以看到它们如何将复杂的多步查询简化为单条语句,同时提高计算性能。掌握窗口函数不仅能让数据分析工作更加高效,还能开拓更深入的数据探索可能性。建议数据分析师和开发人员将窗口函数纳入核心技能库,以应对日益复杂的数据分析需求。
Ground truth最近在做计算机视觉方面的一些工作,刚刚入行,懂得比较少,很多东西需要慢慢学习积累。即日起开始总结部分内容,以自己复习为根本出发点,可能比较low,无所谓啦~机器学习经常遇到ground truth一词,根据知乎回答,字面意思为地面真值,地面实况,可理解为以某种参考值为认定的真实值。比如,对某医学图像,含解剖结构,找某个医生进行边缘勾画,这个参考值,就成为了算法评价采...
深度学习训练工具深度学习训练工具(Deep Learning Tool, DLT)用于训练刀闸、仪表、压板等目标的检测模型。运行环境1.硬件环境内存:&
::OpenCV图像处理特征提取目标检测实例分割。
DarkNet转Caffe中有很多潜在的问题,在YOLOv1、v2、v3几个网络中有一些特殊的层。要在Caffe中跑YOLO,就得在Caffe中源码实现这些层。这些层的Caffe源码实现可以在网上找到很多。YOLO特殊层的Caffe框架实现YOLOv1detection层源码实现YOLOv2route层用concat层替换reorg层源码实现...
/此处是32位灰度图像(黑白);//640*480转227*227。我们打开电脑自带的摄像头软件,放置在left=0,top=0的地方,然后程序中。然后遮住摄像头,识别了一下,softmax处理后的结果是7左右,还行!//不用glob_rgbValues[nn * 4+3]alpha分量。,实时截屏rect=(0,0,640,480)区域,然后我们调用。训练后,识别了一下,softmax处理后的结
一、数据准备,生成lmdb文件方案一:直接通过cmd执行以下命令:convert_imageset.exe --resize_height=240 --resize_width=240 --shuffle --backend="lmdb" G:\ G:\caffe_python\label\label_train.txt G:\caffe_python\label\train_lmdb...
安霸Ambarella_海思Hisilicon_AI芯片参数对比安霸Ambarella_AI芯片方案成功应用于GoPro Hero 运动相机系列;大疆高端幻影无人机系列的摄像头;Ring、Nest、博世(Bosch)和康卡斯特(Comcast)等一系列品牌的安防摄像头;丰田、福特、本田等汽车制造商在其汽车内置的行车记录仪等;...
1.4. 训练只要支持图层并且满足参数约束,就可以导入现有的Caffe和TF-Slim 模型。但是,这些模型通常包括密集的权重矩阵。为了利用TIDL-Lib的一些优点,并获得3x-4x的性能改进(对于卷积层),有必要使用caffe-jacinto caffe fork重复训练过程,可在https://github.com/tidsp/caffe-jacinto?卷积神经网络计算负荷的最大贡献来自于
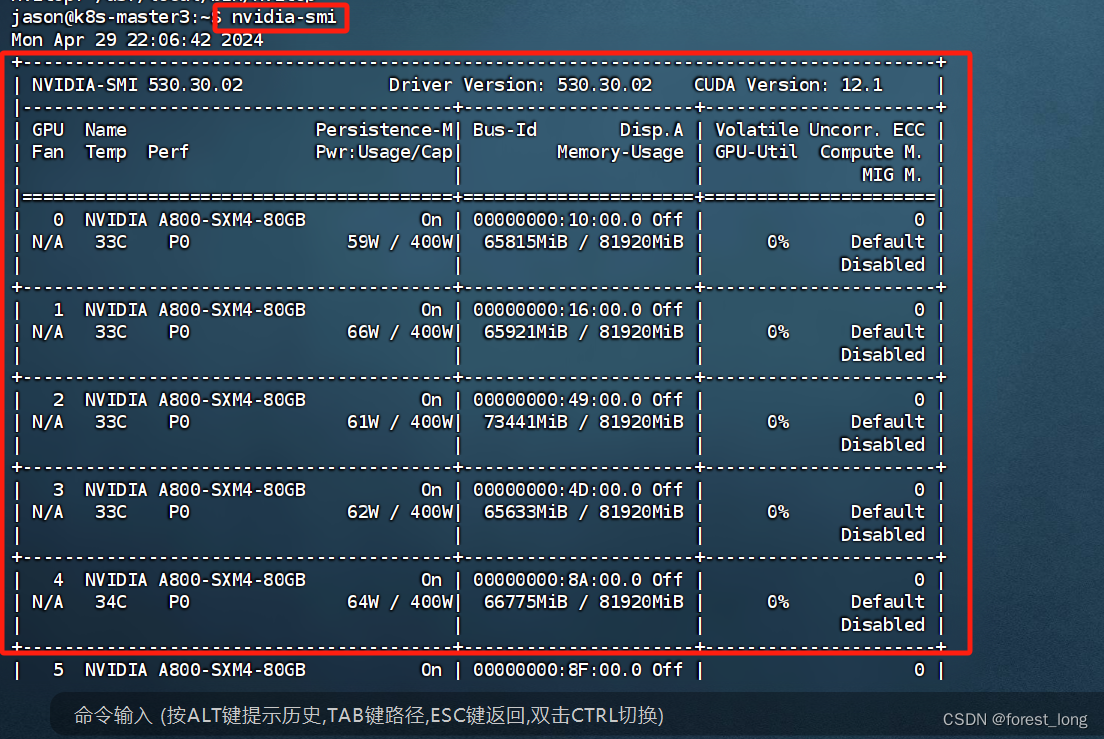
相信大家在用NVIDIA-GPU训练网络模型的时候,都会习惯性的在终端nvidia-smi一下吧?最直接的目的是为了查看哪些卡正在使用,哪些卡处在空闲,然后挑选空闲的卡号进行网络训练。咱们作为一名资深的算法工程师,毕竟身兼多职:上要开发AI算法,下要管理服务器,左要带新人,右要PPT汇报上级。对于管理服务器:刚买的新服务器你得装系统吧?得装DriverCudaCudnn吧?
本文探讨了通过OpenClaw平台与XMind/ProcessOn集成实现流程图、架构图和工作脑图的自动生成方案。传统手动绘制图表耗时且易出错,而OpenClaw作为数据处理引擎,能够解析结构化数据并转换为可视化工具兼容的格式。文章详细介绍了三种集成方法:API直接调用、文件导出导入和插件扩展,并提供了具体代码示例。实际应用案例显示,该方案可节省40-70%的时间,显著提升工作效率。虽然存在数据质
Any通用类型简介与实现 Any是一种类型擦除容器,能够存储任意类型的值并安全恢复原始类型。它解决了传统void*丢失类型信息的问题,避免了复杂的继承体系,适用于需要处理多种数据类型的场景(如服务器协议处理)。 核心特性: 类型擦除:统一接口存储不同类型 类型安全:运行时检查确保类型匹配 值语义:支持深拷贝和赋值操作 实现原理: 使用基类holder定义通用接口 模板子类placeholder存储
一个好玩技巧:让Codex把我的工作流蒸馏成skill
GitHub Copilot 是 AI 编程助手:- 自动补全代码- 根据注释生成代码- 解释代码- 修复 Bug。
caffe
——caffe
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 AI Agent技术社区
AI Agent技术社区

 人工智能6S服务平台
人工智能6S服务平台



 DAMO开发者矩阵
DAMO开发者矩阵





 openEuler 社区
openEuler 社区

 DeepSeek技术社区
DeepSeek技术社区




 智能体开发者社区
智能体开发者社区


 AtomGit开源社区
AtomGit开源社区
