




- @qq_18943707
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通过上述代码解析,我们深入了解了Transformer Block在图像处理中的实现细节。该模型通过结合注意力机制和前馈网络,有效提升了特征提取的能力。总结:优势并行计算能力强,适合大规模数据处理。注意力机制能够自动关注重要特征,提升模型的表达能力。不足之处计算复杂度较高,可能不适合实时处理任务。需要大量标注数据进行训练,对小样本场景效果有限。引入多尺度特征:结合不同尺寸的注意力机制,捕获多层次上

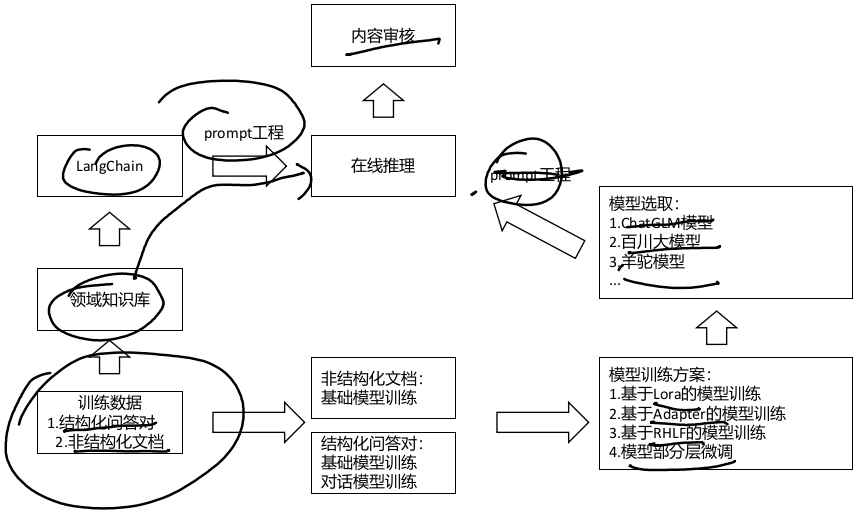
大模型技术正在快速发展,从算法创新到工程实践都蕴含着巨大机遇。掌握其核心原理和关键技术,将有助于我们更好地应用和创新这一变革性技术。随着研究的深入,大模型必将在更多领域展现其强大能力,推动人工智能技术走向新高度。
从学术研究到工业应用,深度学习的演进从未停歇。S2-MLPv2的成功展示了一条新的可能性道路——用更灵活高效的模型结构来应对复杂的现实任务。面对未来,让我们保持敏锐的洞察和探索的热情,在这条创新驱动的路上不断前行。

大模型技术正在快速发展,从算法创新到工程实践都蕴含着巨大机遇。掌握其核心原理和关键技术,将有助于我们更好地应用和创新这一变革性技术。随着研究的深入,大模型必将在更多领域展现其强大能力,推动人工智能技术走向新高度。
在深度学习领域,尤其是在计算机视觉方面,不断涌现新的模型和算法来解决复杂的图像处理任务。其中,自注意力(self-attention)机制因其强大的特征捕获能力而受到广泛欢迎。然而,在某些场景下,传统的自注意力可能无法充分捕捉到多尺度特征信息。为了解决这个问题,Multiscale Dual-Representation Alignment Filter(MDAF)模块应运而生。本文将详细解析MD