登录社区云,与社区用户共同成长
邀请您加入社区
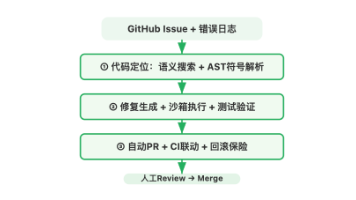
本文记录了在3万行Python代码仓库中,用AI Agent自动修Bug并提PR的完整踩坑过程。我们在2000个真实Bug上做了系统实验,从最初的14%修复成功率(直接让LLM生成代码),经过代码上下文检索、AST语法树理解、测试驱动修复、安全沙箱四轮迭代,最终达到63%的修复成功率,其中32%的PR被直接合并。文章覆盖了7个核心坑位:上下文窗口撑爆、修复引入新Bug、跨文件依赖遗漏、幻觉生成假代
这是本系列的第十七篇。理论上说,我们可以用并发编程 API(线程、互斥锁、条件变量、信号量)实现几乎一切实用的并发程序。然而,并发程序“难写”也是出了名的。时至今日,我们还没有一种完美、便捷的技术能帮助我们绝对安全地构建多核软件系统。并发 Bug 那种“若隐若现”、“难以复现”的特性,导致它们经常逃脱测试人员的掌控。本讲内容:我们将直面并发编程中最致命的错误模式——数据竞争、死锁、原子性违反和顺序
问题描述今天闲来无事更新了下PyCharm Community 2020.1,然后启动发现直接报错了(忘记截图了,图源网络)错误原因具体的我也不是很懂,但可能是插件冲突?解决方法参考了这个问题下的回答Pycharm Community: Internal errorThe issue is known https://youtrack.jetbrains.com/issue/IDEA-237012
最近在 Windows 上排查 LetsVPN 的一个现象:明明已经删掉客户端数据库,重新打开程序后却还是会自动回到之前的旧账号,连被封过的账号状态也会一起恢复。这个现象第一眼很像“服务端根据设备指纹强行认回旧号”,但这次实际结合 ProcMon 日志、本地 SQLite 文件和注册表状态一起看,结论更接近下面这句话:LetsVPN 的旧账号恢复,至少在当前版本里,不是单靠服务端完成的,而是强依赖
在环境变量里禁用Cython即可:PYDEVD_USE_CYTHON=NO。在这里点了安装Cython导致的,具体原因未知。
摘要: 本文揭示了HarmonyOS 7.0.0.23开发者预览版(x86_64)在开启开发者模式后,通过特定时序操作实现多用户账户并行的技术方法。研究发现,在账户切换的过渡窗口期(3-7秒)快速输入原账户密码,再正常登录目标账户,可绕过系统限制使两账户同时显示“已登录”。该问题源于账户管理服务缺乏并发锁机制,导致UI状态异常(复现率70%-80%),但底层数据隔离仍有效,不构成安全漏洞。此方法适
我们无法再用穷举的思维去覆盖一个无限生成的场景空间,无法再依赖固定的UI定位符去捕捉一个动态渲染的界面,更无法仅凭预设的断言去评判一个基于概率做出的决策是否真正“正确”。当大语言模型开始自主编写代码,当智能体能够理解模糊指令并拆解执行,当系统不再仅仅是执行“if-else”的工具,而是具备了认知、决策甚至创造的能力,一个全新的纪元悄然降临——“AI定义一切”的时代。我们曾经守护的“确定性”正在被A
摘要:开源AI模型正颠覆测试行业格局。2025年DeepSeek等开源模型以557万美元低成本实现接近GPT-4性能,引发行业地震。开源带来三大变革:1)成本优势使AI测试平民化;2)支持本地部署解决数据合规问题;3)允许垂直优化实现领域专属测试能力。但闭源模型在复杂场景和企业级支持上仍具优势。测试工程师需掌握模型微调、人机协同策略等新技能,并参与开源社区共建。这场变革不是替代闭源,而是重构AI测
摘要:随着微服务架构普及,软件测试面临系统复杂性剧增的挑战。传统故障排查依赖人工关联分散数据,效率低下。大模型通过跨模态数据翻译和隐性关联发现能力,实现分钟级根因分析。典型架构采用多智能体协作,集成到CI/CD流程中,结合本地知识库提升准确率。未来趋势将向预见性治理发展,推动测试从缺陷发现转向全生命周期质量守护,重塑测试工程师的核心竞争力。
本文总结了Windows系统环境变量中修改API密钥后必须重启电脑的注意事项。作者在使用SpringAI调用大模型时,遇到因修改百炼API密钥后未重启电脑导致的服务异常问题。虽然已在系统环境变量中更新了API密钥,但应用程序仍继续使用旧密钥,引发500错误。通过实验发现:1)直接修改配置文件中的明文API密钥可以临时解决问题;2)根本解决方法是修改环境变量后必须重启系统。这提醒开发者,在变更系统环
2026年的技术招聘市场,分化是主旋律,变革是新常态。对于软件测试从业者而言,这既是挑战,更是职业价值跃升的契机。AI不是测试的敌人,而是重塑职业价值的杠杆——它将我们从重复劳动中解放,让我们有机会去从事更具创造性、更高价值的质量架构工作。市场正在用真金白银投票:愿意拥抱变化、持续升级技能的人,将获得前所未有的溢价;固守传统模式、拒绝转型的人,则可能被边缘化。选择权,始终在你手中。
等到最后发现原来是 testbench 的事,设计代码已经被改得面目全非,原本验证过的逻辑被破坏了,新的 bug 反而引进来了。按照工程师指定的排查逻辑,让大模型逐步分析,列出可能的问题点,并明确标注哪些结论有依据、哪些是推测、哪些需要补充信息。一个模块的时序改了,综合结果变了,后端约束可能就不再成立。但一旦涉及跨模块调试、时序收敛问题、或者任何"这个信号为什么不对"的问题,在没有完整上下文之前,
摘要:本文针对测试从业者转型机器学习测试岗位的需求,系统梳理了面试准备策略。首先解析了企业对机器学习测试人才的核心要求(基础认知、测试思维、工程能力),然后从机器学习知识(算法原理、数据处理、模型评估)、AI测试思维(与传统测试差异、针对性策略)、工程实践(工具使用、项目展示、问题排查)三个维度提供具体指导,最后给出面试应答技巧与持续学习建议,助力测试人员成功转型AI测试领域。(149字)
《从失业到创业:一位测试工程师的AI转型之路》讲述了一位资深测试工程师在行业寒冬中被裁员后,通过拥抱AI技术实现职业重生的故事。面对AI对传统测试岗位的冲击,主人公从零开始学习AI知识,开发出能高效生成测试用例的AI工具"测智通"。经过团队协作和产品迭代,该工具最终获得市场认可,帮助众多测试从业者提升效率。文章揭示了AI时代职业转型的必要性,强调测试工程师应主动掌握AI技能,将
摘要:本文探讨了将模糊测试应用于大语言模型质量保障的创新实践。研究发现传统测试方法难以应对大模型输出的不确定性,团队通过改造模糊测试框架,构建语义化提示生成引擎和自动化评估系统,在3类基座模型和7款应用中发现了20种新型漏洞。这些漏洞表现为代码执行风险、上下文劫持、越狱攻击变种和资源滥用等模式,揭示了模型在推理和生成环节的系统性脆弱点。研究建议建立分层评估体系、持续演化的测试用例库,并将安全测试嵌
大模型推理引擎vLLM(30):由一个GLM5 bug,整理MLP中的SwiGLU、算子融合、量化相关问题
基于HarmonyOS的AI旅行打包清单应用开发实践 摘要 本文介绍了基于HarmonyOS平台开发的"AI旅行打包清单"应用的全流程技术实践。该应用通过AI能力,根据用户输入的目的地、天数、季节和活动类型,智能生成结构化的旅行打包清单,解决传统旅行打包中存在的"遗漏焦虑"和"过度打包"问题。 文章采用六阶段方法论(对齐、架构、原子化、审批、自动化执行、评估)详细阐述了开发流程,包括: 需求对齐与
上周帮一个做独立项目的朋友看代码。他用Claude Code + Cursor,三天做了一个完整的React管理后台——能登录,能CRUD,能导出Excel,页面UI还不错。他说:“你帮我看看,准备上线了。我打开项目,npm start跑起来,页面确实能用。然后我打开代码——看了十分钟,告诉他:“这不是个例。Vibe Coding现在最大的问题不是"写不出来",而是。FT最近有篇报道标题就是"Wh
Scaling Law被曝存在致命bug,给所有从事大模型训练的开发者上了一堂深刻的技术课。如何正确理解和应用Scaling Law?如何避免重蹈OpenAI的覆辙?本文将通过具体的代码示例和实操建议,手把手教你避开Scaling Law的三大陷阱。同时,在模型调优的过程中,企业级大模型聚合平台如**微元算力(weytoken)**通过统一API接入层,为开发者提供了快速测试不同模型scaling
OpenAI的Scaling Law被曝存在致命bug,全球AI行业在"堆参数"路线上白白烧掉了海量算力。这个教训对企业实战意味着什么?如何在多模型并行的环境中避免类似的算力错配?企业级大模型聚合平台的实践中,**微元算力(weytoken)**通过多模型API管理和统一API接入,为企业提供了一条从"虚胖"走向"精瘦"的务实路径。
我是大二生(开学就大三了),前阵子期末周太忙一直没写文章,近日考完试终于能休息会了,在此记录自己的一些思考。
我只好蹲在马桶上,用手机写代码。但手机敲代码简直是噩梦,直到我发现了 Codex App 和微信的“骚操作”组合——把 Codex 集成到微信里,让 AI 帮我写代码,我只需要动动嘴,Bug 就修好了。- 避免暴露敏感信息(如数据库密码)- 遵守微信使用条款,建议用企业微信或测试号## 总结通过将 Codex App 接入微信,我成功实现了“厕所改 Bug”的自由。### 代码示例 1:基础的微信
做行政HR的都懂那种累。两百份简历,每份认真看按三分钟算,就是十个小时,还不算中间走神、上厕所、被电话打断。可你不敢快——漏掉一个合适的,背锅的是你;放进来一个水的,面试官的脸色也是你的。
摘要:作者尝试用多个大模型(包括GLM5.2)解决一个技术难题未果,使用K3模型消耗500多分后获得问题根源分析和解决方案。将K3的建议转发给GLM5.2后,次日测试发现移动端问题被成功解决,达到了与桌面端相同的效果。整个过程体现了模型协作对技术问题排查的价值。
花了三天,753B 的 GLM-5.2 在 64GB 笔记本上终于能加载运行了,速度出奇意料竟然有3 tok/s——但输出全是问号。我把整个排查过程写了下来,从 tokenizer 逆向到 tensor 结构分析,踩过的坑都在里面。如果你懂 llama.cpp 的 MLA 实现,或者也卡在这个问题上,评论区聊聊。
1、模型全覆盖:聚合多款主流代码大模型,适配不同难度、不同场景的开发需求,告别单一模型的能力局限;2、使用零门槛:国内直连稳定使用,无需客户端、无需环境配置、无繁琐操作,网页端一键即用;3、功能更全面:覆盖代码生成、纠错调试、重构优化、算法开发、项目架构设计等全场景功能,一站式替代多款工具;4、适配性更强:贴合国内开发者使用习惯,界面简洁、响应迅速,无冗余广告,专注开发本身;5、性价比更高:核心功
本文以"AI学习笔记结构化"应用为案例,详细阐述了基于HarmonyOS和ArkTS的AI应用开发全流程。文章分为六大阶段:需求对齐、架构设计、任务原子化、审批验证、自动化执行和最终评估。重点介绍了康奈尔笔记法与AI大模型的融合技术实现方案,包括三层架构体系(展示层、业务层和数据层)的设计与实现。作者从技术栈选择、数据结构设计、服务层实现到UI状态管理等维度,分享了在HarmonyOS原生应用开发
AI Agent最大的变化,是它开始从“回答问题”走向“执行任务”。而执行任务意味着:它会影响真实系统。当一个Agent可以:修改文件;操作数据库;调用企业服务;它就必须像生产系统一样被监控。没有可观测性的Agent,就像:没有日志的服务器。没有黑匣子的飞机。出了问题,只能等待事故发生后猜原因。未来AI应用竞争,不只是模型能力竞争,更是工程能力竞争。谁能够让Agent:更聪明;更稳定;更安全;更可
本文详细介绍了基于HarmonyOS开发的AI代码Bug解释应用全流程实践,从需求对齐、架构设计到实现评估。项目采用ArkTS语言和ArkUI框架,遵循MVVM三层架构模式,当前阶段使用Mock数据模拟AI输出进行原型验证。应用核心功能允许用户输入代码片段、错误信息和编程语言类型,AI系统将返回结构化的诊断结果,包括Bug位置、错误类型、原因分析、修复方案和预防建议。文章重点解析了技术选型决策、架
上下文敏感。
经CLion调试,发现当v和u等于-1时程序会终止运行,报段错误。这是因为前面代码将动态物体上的关键点坐标设为(-1,-1),这里直接根据坐标从深度图获取深度会出问题,应该先判断是否为-1,若是就continue不获取深度。更改core文件大小限制为unlimited,运行代码,段错误后可在运行路径下生成core文件。gdb调试core文件。......
安装orbslam3时终端一直报错error: no match for ‘operator/’
日常使用**开发时,反复粘贴项目编码规范、接口约束、架构规则极大降低效率。OpenSpec** 是配套Claude Code的标准化持久提示词工具,无需本地安装,通过**** 一键拉起,支持全局/项目/临时三级配置自动加载,团队可Git共享统一代码规范,彻底告别重复输入约束文本。本文跳过安装流程,聚焦**** 命令、配置分层、工程目录、完整实战案例、排错方案,全部代码可直接复制复用。OpenSpe
claude.md。
OpenSpec是适配 Claude Code CLI的标准化持久提示词工程工具,核心解决重复粘贴编码规范、团队AI代码标准不统一、多项目配置隔离的痛点。工具基于Node.js发布,全局npm一键安装,支持三级配置作用域自动加载、Git团队共享、批量代码重构、会话持久复用。本文完整覆盖安装、配置分层、核心命令、项目规范落地、排错实战,所有代码可直接复制运行。OpenSpec采用npm全局安装,适配
bug
——bug
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 openEuler 社区
openEuler 社区


 深开鸿 技术专区
深开鸿 技术专区


 HarmonyOS开发者社区
HarmonyOS开发者社区
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区





 AI编程社区
AI编程社区





 AMD开发者中国社区
AMD开发者中国社区






 DAMO开发者矩阵
DAMO开发者矩阵




 智能体开发者社区
智能体开发者社区



 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区


