- @a486259
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
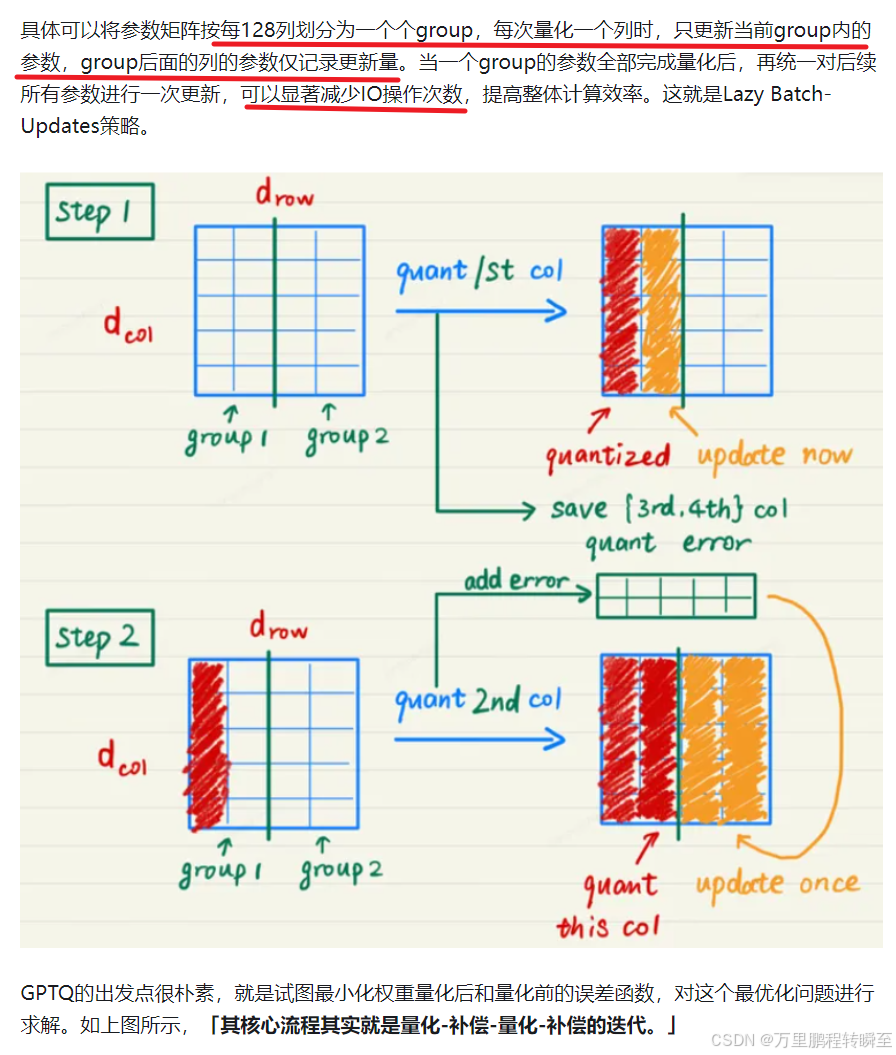
在深度学习中模型量化可以分为3块知识点,数据类型、常规模型量化与大模型量化。本文主要是对这3块知识点进行浅要的介绍。其中数据类型是模型量化的基本点。常规模型量化是指对普通小模型的量化实现,通常止步于int8的量化,绝大部分推理引擎都支持该能力。而大模型的量化,需要再cuda层次进行能力的扩展,需要特殊的框架支持。
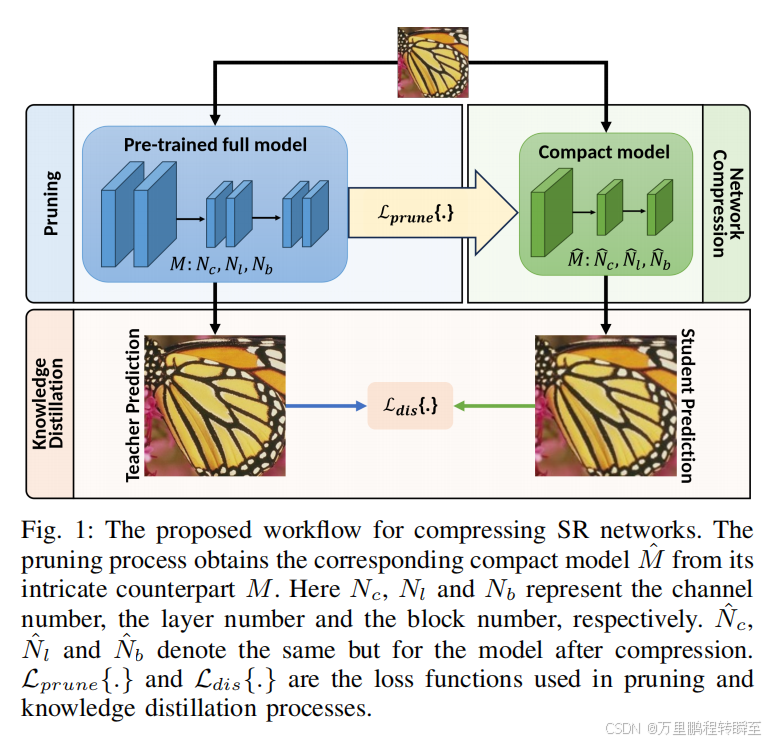
项目地址:https://github.com/Pikapi22/SRModelCompression论文地址:https://arxiv.org/pdf/2401.00523发表时间:2024年2月21日深度学习技术已被应用于图像超分辨率(SR)领域,在重建性能方面取得了显著的进展。现有的技术通常采用高度复杂的模型结构,这将导致较大的模型规模和缓慢的推理速度。这往往导致高能耗,并限制了其在实际应
Triton 的核心理念是基于分块的编程范式可以促进神经网络的高性能计算核心的构建。CUDA 编写属于传统的 “单程序,多数据” GPU 执行模型,在线程的细粒度上进行编程,Triton 是在分块的细粒度上进行编程。例如,在矩阵乘法的情况下,CUDA和Triton有以下不同。

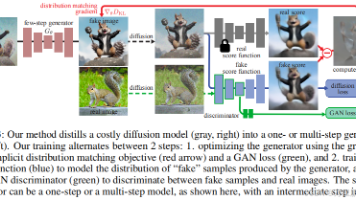
DMD的目的是训练一个单步生成器Gθ,但不包含时间条件,将随机噪声z映射为一张逼真的图像。其通过最小化两个损失的和来训练快速生成器:一个是分布匹配损失,其梯度更新可以表示为两个得分函数的差值;另一个是回归损失,它鼓励生成器在固定的噪声-图像对数据集上匹配基础模型输出的大尺度结构。
发表时间:2024年5月24日分布匹配蒸馏(DMD)生成的一步生成器能够与教师模型在分布上保持一致,即。然而,。这些。这不仅在大规模文本到图像合成中计算成本高昂,还限制了学生模型的质量,使其与教师模型的原始采样路径过于紧密绑定。DMD2:在ImageNet-64×64数据集上FID分数达到1.28,在零样本COCO 2014数据集上FID分数为8.35。推理成本降低了500%×,超越了原始教师模型
软件依赖:mediamtx、ffmpegpython包依赖:deffcodemediamtx下载地址:https://github.com/bluenviron/mediamtx/releasesffmeg下载地址:https://ffmpeg.org/download.htmldeffcode安装命令:pip install deffcode。

最近提出的任意分割模型(SAM)在许多计算机视觉任务中产生了重大影响。它正在成为许多高级任务的基础步骤,如图像分割、图生文和图像编辑。然而,它巨大的计算成本使它无法在行业场景中得到更广泛的应用。计算主要来自于高分辨率输入下的Transformer体系结构。
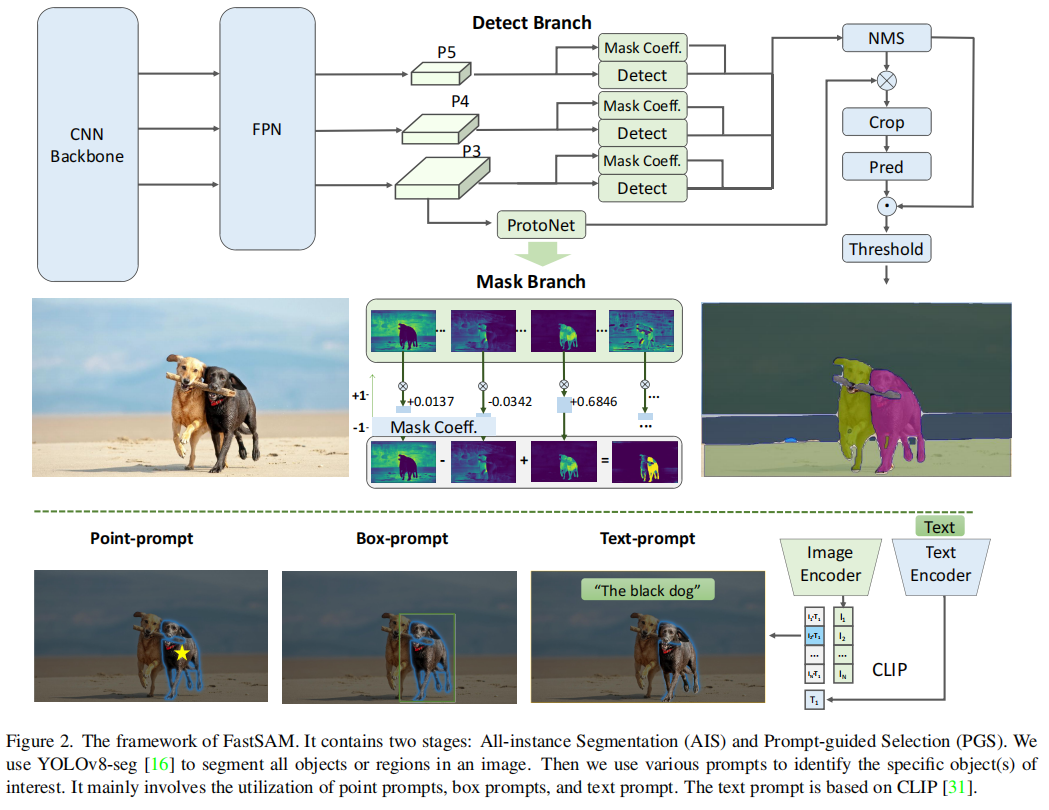
自从2021年Transformer被引入到视觉模型后,卷积神经网络基本上要末路了,虽然此后也有ConvNeXt、SegNeXt成功挑战过Transformer的地位,但也无力挽回卷积神经网络的大势已去。ConvNeXt使用了一些列的训练技巧(AdamW 优化器、Mixup、Cutmix、RandAugment、Random Erasing等数据增强技)和随机深度和标签平滑等正则化方案,也不过是勉

论文地址:https://arxiv.org/pdf/2506.08009发表时间:2025年6月9日我们提出了一种用于自回归视频扩散模型的新型训练范式——自强制(Self Forcing)。该方法解决了长期存在的“暴露偏差”问题:在进行学习,但在。与以往那些基于真实上下文帧对未来帧进行去噪的方法不同,自强制通过。这一策略使得我们能够通过视频层面的整体损失进行监督,从而直接评估整个生成序列的质量,

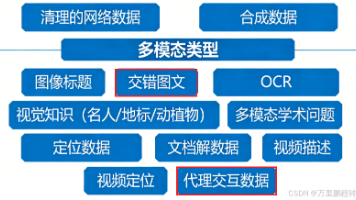
qwen3vl将训练数据token又降低到2000B的规模(SFT阶段仅使用了120w数据),这表明训练数据量可能不是制约模型性能的关键,训练数据的分阶段配比利用才是多模态模型性能提升的关键。同时期InternVL3.5仅训练了1160M 样本(250B token,仅约InternVL1的1/5,约为qwen3vl的1/10)SFT阶段使用了600M(6亿条,是qwen3vl的500倍,但该阶段