登录社区云,与社区用户共同成长
邀请您加入社区
《Claude Code离线安装方法及注意事项》摘要: 本文介绍了Claude Code的离线安装方案,主要适用于无法直连外网的服务器环境。核心方法包括:1)使用社区工具cc-download下载离线安装包;2)直接获取npm包进行安装;3)便携版解压即用方案。文章详细提供了Linux/macOS和Windows系统的具体下载命令,并指出安装后仍需网络连接以调用云端AI服务。注意事项包括:运行时仍
李华用ClaudeCode在48小时内开发出智能停车系统,将找车位时间从15分钟降至2分钟,车位利用率提升35%,成本仅5万(传统需80万)。关键技巧:1)提供完整业务场景让AI理解需求;2)分阶段从架构到功能逐步开发;3)实时测试迭代。ClaudeCode展现了强大的算法处理、代码优化和异常恢复能力,最终实现95%用户满意度和99.5%系统稳定性,证明AI工具能让非技术人员快速实现商业创意。
随着Java 18的发布,JDK引入了一个名为jwebserver的简易命令行Web服务器工具。该工具旨在为开发人员提供一个快速启动、零配置的静态HTTP文件服务器,适用于本地开发、测试和教学等场景。jwebserver基于Java内置的HTTP服务器API实现,无需额外依赖,开箱即用。Java 18的jwebserver是一个务实且便捷的工具,精准地填补了快速静态服务需求的空白。它为开发者提供了
文章摘要:作者分享了自己深度使用Claude AI的经验总结。与常规用法不同,作者发现Claude更适合作为"思考编辑"而非全自动写作工具。具体实践包括:处理长资料时先分析核心问题而非直接总结;写文章时先确定角度再补充细节;代码场景中辅助判断而非完全托管;资料分析时先提供框架再深入挖掘。作者认为Claude的核心价值在于深度协作——当用户明确给出思考框架和边界时,它能有效帮助梳理复杂信息、优化表达
这个大纲涵盖了 DeepSeek 在多个工作场景下的应用,并强调了实际操作的技巧和注意事项,旨在帮助读者切实提升工作效率。
硅谷新英雄OpenClaw之父豪言:本地AI智能体将灭掉80%App,人类从此只需「许下愿望」,世界自动为你运转!OpenClaw更是开启万亿美元应用新场景,社交套利从未如此简单!这些天,硅谷正在经历一场前所未有的疯狂。OpenClaw之父,已经成为硅谷英雄——继互联网之后,他开启了文明层级的又一次范式转移。所有人类,正在站在被智能体接管的奇点前夜。刚刚,OpenClaw之父上了YC访谈,揭秘了O
这篇文章分享了作者使用AI工具辅助创作知乎回答的经验。文章指出,AI可以帮助改稿但不能完全替代人工创作,强调保持真实个人经历和口语化表达的重要性。作者详细介绍了自己的写作流程:先写草稿,用AI检查结构问题,重点打磨开头,删除套话,补充真实案例,最后人工检查AI痕迹。文章提醒不要过度依赖AI生成内容,避免"正确废话",并分享了使用聚合平台管理多个AI工具的心得。核心观点是:AI应作为辅助编辑工具,而
今天咱们要拆解的这套IEEE33节点系统,左边是18节点的交流电网,右边是15节点的直流电网,中间通过VSC换流站咬合在一起。这套算法的优势在测试中表现明显:当光伏出力在直流侧突然变化20%时,交替迭代法能在5个周期内重新收敛,而完全耦合的牛顿法则需要重构整个雅可比矩阵,耗时反而更长。传统交流潮流用的牛顿法,但混联系统里要注意:每个VSC连接的交流节点都会产生额外的耦合项。有趣的是,前3次迭代通常
摘要: Cloudera CDP 7.3官方已不再提供免费下载,仅限订阅客户通过门户获取。国产信创项目可通过华为等厂商获取适配ARM架构的定制版CMP 7.3。开发者可申请60天试用版(仅x86),或自行集成开源Hadoop生态组件。第三方分享的安装包存在安全风险,建议通过官方或合规渠道获取。
接入 AI API 看起来简单,但真正跑通需要避开很多暗坑。选型阶段多花时间比选代码框架还重要,一旦跑通,尽量别频繁换服务商,迁移成本极高。
注册 Superpowers 的市场源(只需执行一次):text/plugin marketplace add obra/superpowers-marketplace。想自动全局加载 → 可以把 /plugin load superpowers 写到你的 ~/.claude/CLAUDE.md 或项目CLAUDE.md里。安装成功但没新命令 → 重启 Claude Code,或新开会话;有任何一
简单来说,它是你管理 Hadoop 生态系统的“控制中心”,能够让你通过一个直观的 Web 界面,轻松掌控整个数据中心的复杂运作。*提高效率: 通过 API,你可以将集群管理任务(如自动扩容、备份)集成到你的 DevOps 流程中,实现自动化运维。*滚动升级: 支持零停机的滚动升级,这意味着在升级软件版本时,你的业务服务可以继续保持运行,极大地提高了可用性。*全局视图: 通过仪表盘和热图,你可以实
iflow学习git命令学习claude学习
量化差异核心:简单任务Claude Code比传统手写快20倍以上,中等任务快12倍以上,核心节省「调试、查文档、补细节」的时间。干货核心:用好Claude Code的关键是精准提示词(黄金公式),同时掌握「快速校验代码」的技巧,避免黑盒风险。落地核心:Claude生成的代码可直接运行,无需额外调试,新手可快速落地实战项目,核心精力从「代码实现」转移到「业务逻辑优化」。
Claude-CN汉化版项目介绍 该项目是free-code的中文汉化分支,旨在为中文用户提供更好的Claude使用体验。主要特点包括完整汉化界面、移除遥测和安全限制、解锁45+实验性功能。提供一键安装脚本和多种构建方式,支持macOS/Linux/WSL系统运行。项目移除了原版的所有数据上报和额外安全提示层,同时启用了包括语音输入、远程控制桥等高级功能。安装需Bun环境和Anthropic AP
Claude Code 作为 AI 编程神器,提示词质量直接决定代码生成效率与准确率。本文整理 324 条可直接复制的提示词、核心原理深度解读、全套学习资料,助力开发者零基础快速上手,实现代码编写、Bug 修复、项目重构全流程提效。Anthropic 推出的官方 CLI 编程工具,可自主读取代码库、编辑文件、执行命令、规划多步骤开发任务,支持全栈开发与工程化协作。掌握 Claude Code 提示
文章摘要 《Claude Code 实操教程》详细介绍了如何从零开始安装配置AI办公助手Claude Code,并利用其处理日常办公任务。教程分为环境准备、安装配置、模型切换和实际应用四大部分: 环境准备:需要终端、Claude Code和CC Switch三个基础工具 安装指南:提供Windows和Mac系统的详细安装步骤,包括PowerShell和终端命令 模型管理:介绍使用CC Switch
随着AI技术的飞速发展,AI编程助手已经成为开发者工具箱中的"标配"。而在众多AI编程工具中,凭借其强大的代码理解能力、精准的上下文把握以及出色的多轮对话交互体验,迅速成为程序员的宠儿。但问题来了——你真的会用Claude Code吗?很多开发者只是简单地让Claude写一段代码,却从未深入挖掘它的真正潜力。提示词(Prompt)的质量直接决定了AI输出的质量。今天,我为大家整理了一份超全的Cla
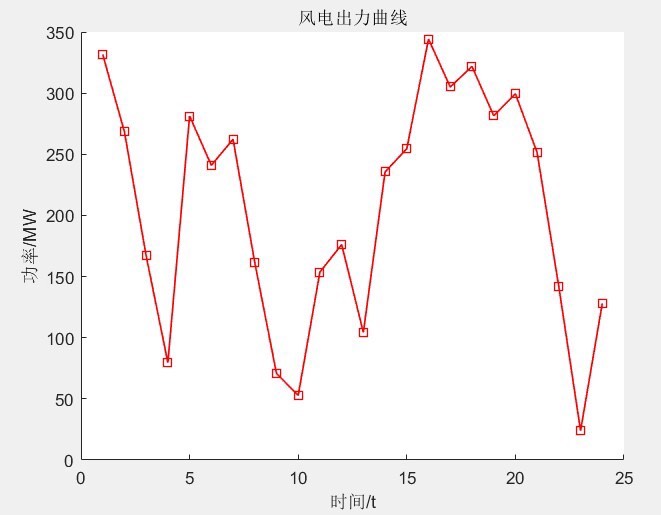
这部分是“数据准备站”,把所有需要用到的固定参数都列好了,不用在主代码里反复写,改参数也方便。负荷与新能源参数:比如24小时的日负荷(PD)、风电出力(Pwt)、光伏出力(Ppv)、净负荷(Pnet),还有储能的充放电功率(Pc、Pd)。这些数据是整个优化的基础,比如风电白天少晚上多,光伏只有白天有,这些波动都靠火电机组来补。经济成本参数:燃煤单价(Pcoal=500)、风光储环境收益(Bw=80
网易数帆EasyData支持以Cloudera CDP或华为CMP(鲲鹏ARM版)为数据底座的AI增强分析方案。该方案通过JDBC/ODBC接入CDP/CMP数据源,利用EasyData内置AI引擎实现自然语言查询(ChatBI)、时序预测和异常检测等功能。实施步骤包括:1)配置数据源连接(支持Kerberos认证);2)同步元数据并创建逻辑表;3)启用AI功能模块。特别针对华为CMP需注意ARM
cloudera
——cloudera
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DeepSeek技术社区
DeepSeek技术社区

 AI Agent技术社区
AI Agent技术社区




 DAMO开发者矩阵
DAMO开发者矩阵



 CSDN-OPC开发者社区
CSDN-OPC开发者社区





 AI编程社区
AI编程社区


 AtomGit开源社区
AtomGit开源社区
 腾讯云开发者社区
腾讯云开发者社区

