




- @Code1994
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
是微软研究院开发的开源多智能体框架,专注于通过对话式协作实现复杂任务自动化。:AutoGen采用对话驱动的架构,支持多种控制流模式,包括自然语言控制、编程语言控制和混合控制。框架内置多种智能体类型,如AssistantAgent、UserProxyAgent、GroupChatManager等。AutoGen最适合需要复杂多Agent协作的科研项目和企业级应用,如代码生成、动态任务执行、跨系统协作

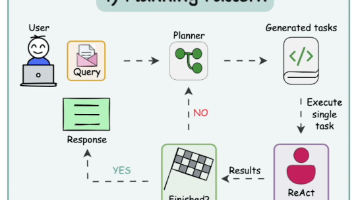
规划模式让AI Agent在执行任何操作之前制定计划或解决方案。Planning Agent不会像ReAct那样直接深入到逐步推理和工具使用中,而是会先为任务指定一个高级计划或路线图,之后Agent会去执行计划中的每一个步骤,最终给出答案。这种方式通过首先制定计划然后采取行动,增强了LLM代理处理复杂任务和决策的能力。
考察点:检索增强技术应用、系统设计能力。
定义一个结构来贯穿整个工作流的“状态”。对于聊天机器人来说,最重要的状态就是不断累积的对话消息。State(TypedDict):使用 TypedDict 来定义状态的数据结构,确保类型安全和代码可读性。messages 是一个 python 列表 list。Annotated:Python 的标准功能,用于给类型附加元数据。add_messages 是 LangGraph 提供的一个便捷的帮助函

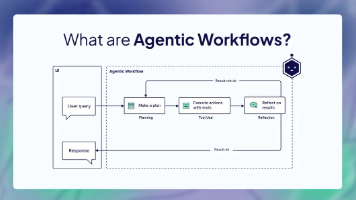
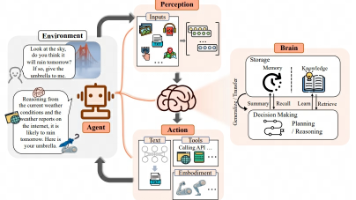
AI智能体是结合了用于推理和决策的LLM与用于与现实世界交互的工具的系统,使它们能够在有限的人类参与下完成复杂的任务。智能体被分配了特定的角色,并被赋予不同程度的自主权来完成其最终目标。它们还配备了记忆,使它们能够从过去的经验中学习并随时间提高其性能。为了更好地理解AI智能体如何融入智能体工作流,我们将探讨AI智能体的核心组成部分。一般来说,工作流是为实现特定任务或目标而设计的一系列相互连接的步骤
文章介绍了AI Agent技术,即从传统AI辅助到自主系统的演进。Agent技术扩展了大模型的四大能力:信息处理、推理规划、工具使用和记忆知识,使AI能自主决策和执行任务。目前已有Operator、Deep Research等成熟产品,以及LangChain、OpenAI Agent SDK等开发工具。随着大模型能力不断提升,AI Agent技术正快速发展并日渐成熟。
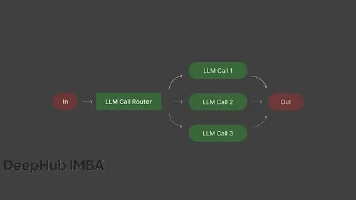
这些结构化工作流彻底改变了LLM的使用方式。不再是随便抛个提示词然后碰运气,而是有章法地分解任务、合理分配模型资源、并行处理独立子任务、智能编排复杂流程,再通过评估循环保证输出质量。每种模式都有明确的适用场景,组合使用能让你更高效地处理各种复杂任务。可以先从一个模式开始熟悉,掌握之后再逐步引入其他模式。当你把路由、编排、并行处理、评估优化这些机制组合起来使用时,就彻底告别了那种混乱、不可预测的提示
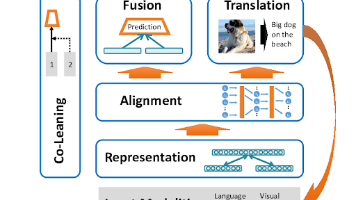
文章通过巴黎旅行比喻,解释多模态学习原理。多模态AI像人类一样通过多种感官同时收集信息,让不同感官信息"对话"关联,将体验编码为可比较格式,确保信息一致性,最后通过智能加权投票系统融合信息,得出准确判断。这一过程包含六个关键步骤:感官收集、感官协调、信息编码、信息对齐、综合判断和完整表达,使AI能够像人类一样全面理解世界。想象你第一次来到巴黎街头,想要完全理解这座城市的魅力。
AI人才缺口达500万,产品经理需求旺盛,中位数薪资36k/月,头部公司可达年薪50W。AI产品经理分为专业型、应用型和工具型三类,其中应用型最适合普通人入局。成为AI产品经理需掌握商业变现、需求把控、技术协同和项目落地能力。今年,无论是一些头部厂商,中小厂商,从海外到国内,大中小公司都在积极拥抱讨论AI和拥抱AI。AI 相关的人才缺口已达 500 万,其中AI产品经理需求旺盛,薪资中位数再创新高
还记得10年前我们对"智能手机📱会改变一切"的怀疑吗?今天,AI智能体正站在同样的历史节点。从ChatGPT的爆火到各种自动化工具的涌现,我们正在见证一个全新时代的开启——智能体时代。在这个时代,AI不再是冷冰冰的工具,而是能够独立思考、主动规划、协作执行的数字伙伴。🔍关键洞察:根据麦肯锡最新研究,到2030年,AI智能体技术将为全球经济贡献13万亿美元的价值增长。掌握这项技能的人,将在未来1
