




- @zgpeace
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了MCP(Model Context Protocol)协议及其应用。MCP作为AI与外部世界交互的标准化协议,通过统一工具调用方式,使大模型能够实际操作系统资源、调用API等。文章从白话、工程、系统设计和协议生态四个层面解析MCP,并通过Mermaid图表展示其架构和工作流程。MCP可与LangGraph、CrewAI等框架配合,作为工具的统一底座。最后提供了为本地项目搭建MCP Ser
案例:跨境电商如何用ChatGFT选品ChatGPT+素材和资料来自:Jungle ScoutEM, Michael Soltis 和 文韬武韬AIGC。

1. TPU和其他1.1 手机芯片1.2 DSP digital signal processor 数字信号处理1.3 可编程阵列 FPGA - field-programmable gate array1.4 AI ASIC - Application-specific integrated circuitsSystolic ArrayFPGA 华为用了很多去做路由器。造一个芯片出来,必须有生态
在这一部分,我将带你了解我做的一个关于贷款预测的项目。贷款的主要利润直接来自于贷款的利息。贷款公司在进行了一系列严格的审核和验证过程后,才会授予贷款。然而,他们仍然不能保证申请人是否能够毫无困难地偿还贷款。在这个教程中,我们将构建一个预测模型(随机森林分类器)来预测申请人的贷款状态。我们的任务是准备一个网络应用,使其能够在生产环境中使用。在这个应用程序中,我们将使用多个小部件作为滑块:在侧边栏菜单

本文通过四个难度层级系统介绍了机器学习中的熵、信息量、交叉熵和KL散度概念。从直觉层面的猜谜游戏类比出发,逐步深入到严谨数学定义:熵衡量系统不确定程度,信息量反映事件发生的惊讶程度,交叉熵表示用错误分布处理真实分布的平均信息开销,KL散度则量化两个分布间的差异。文章还阐述了这些概念在深度学习中的实际应用,如交叉熵损失函数与最大似然估计的等价关系,为理解机器学习中的信息论基础提供了清晰的渐进式框架。
【史上最全】黑客和网络安全题材电影合集我们筛选出的绝大部分电影主题都是围绕“黑客”,其余电影也有足够多的网络安全情节和素材。这些电影能让一些无聊的技术话题(对于一部分朋友来说)变得更生动有趣。不管怎样,这些作品让更多的人们进一步了解了网络安全领域以及如何打击网络犯罪。1.为了让大家能大致了解电影内容,我在原作者的基础上增加了对电影情节的描述,所有描述均摘自豆瓣电影。2.电影按上映时间排序。3.可以
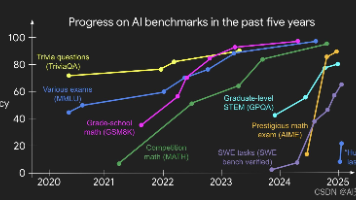
文章摘要:AI发展的中场转折 当前AI发展正处于关键转折点。经过数十年的"上半场",以模型创新为核心(如Transformer、GPT-3),AI已在多个领域超越人类。2023年的突破在于强化学习终于实现泛化,单一方案即可解决软件工程、数学竞赛等多样化任务。 这一成功源于三大要素:语言预训练、规模化以及推理能力的结合。研究发现,强化学习的关键可能不在于算法本身,而是预训练获得的
参考https://www.bilibili.com/video/BV1UQ4y197Q8https://www.bilibili.com/video/BV1UQ4y197Q8
本期我们来讲反向传播 也就是神经网络学习的核心算法 稍微回顾一下我们之前讲到哪里之后首先我要撇开公式不提 直观地过一遍 这个算法到底在做什么然后如果你们有人想认真看里头的数学 下一期影片我会解释这一切背后的微积分 如果你看了前两期影片 或者你已经有足够背景知识 直接空降来这一期影片的话 你一定知道神经网络是什么 以及它如何前馈信息的这里我们考虑的经典例子就是手写数字识别 数字的像素值被输入到网络第

https://github.com/zgpeace/deepracer/tree/master/iterations参考https://www.bilibili.com/video/BV1BV411s7BHhttps://www.bilibili.com/video/BV1BV411s7BH?p=2&spm_id_from=pageDriver