




- @Mikasa33
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
重磅重磅!!DeepSeek-R1 的研究荣登最新一期的!通讯作者正是梁文锋。如果训练出的大模型能够规划解决问题所需的步骤,那么它们往往能够更好地解决问题。这种与人类处理更复杂问题的方式类似,但这对人工智能有极大挑战,需要人工干预来添加标签和注释。在本周的期刊中,DeepSeek 的研究人员揭示了他们如何能够在极少的人工输入下训练一个模型,并使其进行推理。DeepSeek-R1 模型采用强化学习进

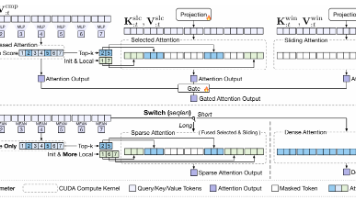
DeepSeek-V3.2-Exp 集成的,是该模型的核心技术创新,其首次实现了细粒度稀疏注意力机制。作为提升大模型处理超长上下文窗口效率的关键技术之一,该机制专注于优化长文本场景下的模型性能。

InfLLM-V2 提出了一套硬件感知的优化实现,通过创新的计算核融合技术,显著降低了高带宽内存(HBM)的I/O与计算负载,从而完全释放稀疏注意力的性能潜力。然而,现有的代表性方法(如 NSA 架构)与主流的“短序列预训练-长序列微调”范式存在显著的架构错配问题,不仅引入了过多的额外参数,还导致模型在迁移训练中收敛不稳,并为短序列处理带来不必要的开销。不同于 NSA 引入三套独立键值(KV)投影
谁能想到,DeepSeek-OCR的模型竟让硅谷集体沸腾?DeepSeek刚开源的DeepSeek-OCR,凭"用视觉压缩一切文本"的颠覆性思路,不仅在GitHub狂揽4K星+、冲上榜HuggingFace热榜第二,更被网友盛赞"开源了谷歌Gemini的核心机密",堪称AI领域的"JPEG时刻"!DeepSeek的OCR项目由Haoran Wei、Yaofeng Sun、Yukun Li三位研究员
从 Hyper-Connections 开启的高维连接,到 Frac-Connections 的效率优化,再到 DeepSeek 通过 mHC 引入的数学流形约束,神经网络的宏观架构设计正在经历从“暴力堆叠”向“精密路由”的进化。严谨结论:拓扑复杂性:单纯增加参数量已不再是 Scaling 的唯一路径,优化层间的信息路由宽度(Residual Stream Width)提供了新的增长点。约束的价值

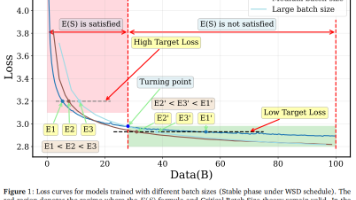
在大模型预训练这一高成本系统工程中,Batch Size(批大小)与 Learning Rate(学习率)的设定,直接影响训练效率与模型性能。它们如同赛车的动力与操控:Batch Size 决定每次迭代处理的数据量,影响训练速度与稳定性;Learning Rate 则控制模型参数更新的步幅,关乎收敛效果与最终性能。长期以来,行业普遍依赖两大经典理论指导超参设置:然而,随着 WSD(热身‑稳定‑衰减
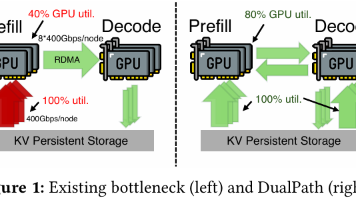
DualPath 并没有发明新的 GPU 或更快的网卡,而是用极其敏锐的系统工程视角,找出了木桶上最短的那块板——预填充节点的存储网卡。通过“化零为整”,把闲置的解码节点带宽拉入战局,DualPath 优雅地化解了 Agent 时代的 I/O 危机。对于正在构建下一代长文本、多智能体协作系统的基础架构团队来说,DualPath 提供了一条极具价值的优化指引路线。
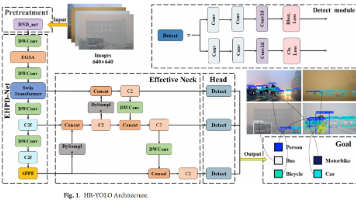
YOLOS 用“最简”序列接口揭示 ViT 的检测迁移极限,适合作为 Transformer 表征学习的硬核基准;HR-YOLO 用“去雾+增强”插件式改造,证明 Transformer 模块可无缝嵌入 YOLO 家族,在恶劣天气下实现精度-效率双杀。换任务——把 [DET] 令牌改成 [SEG]、[POSE] 即可秒变新赛道;换模块——将 DND-Net 换成雨/雪/夜间复原网络,即可冲击不同天
斯坦福大学以人为本人工智能研究院(HAI)于近日发布了第八版《人工智能指数报告》(AI Index Report)。作为全球最具权威性的AI领域年度报告之一,2025年的版本以前所未有的深度和广度,系统性地追踪了人工智能从技术研发、经济影响到全球治理的演进脉络。旨在为决策者、研究者及公众提供一个基于数据的、严谨的AI发展全景视图。

2025年,何恺明团队以“简化、结构、泛化、物理性、重构”为关键词,完成了一场对深度学习核心范式的系统性反思与重塑。在生成领域,团队通过去除噪声条件、引入分形结构、设计单步流场等创新,剥离冗余组件,揭示了生成建模的本质机制;在表征学习中,以“解构退化”的反向思维,证明了简洁架构的强大潜力;在物理推理方向,融合经典力学与神经算子,实现了可解释、多任务的物理建模;在理论层面,重审数据集偏差问题,为行业
