登录社区云,与社区用户共同成长
邀请您加入社区
二者并非 “高低配” 的关系,而是完全不同赛道的产品:Jetson 是面向边缘端的异构嵌入式计算平台,算力价值体现在 “低功耗下的实时推理与外设整合”;NVIDIA 桌面显卡是面向桌面 / 数据中心的通用高性能计算设备,算力价值体现在 “高吞吐的训练与批量处理”。脱离场景单纯对比 TOPS 数值,没有实际参考意义。
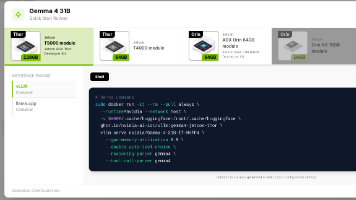
🚀 JetsonvLLM 实践 ,实现 `LLM / VLM`推理:从 `Qwen`、`Gemma`、`Llama`,到 `Nemotron`、`Cosmos`、`GPT OSS`;从 `0.8B`、`4B` 的轻量模型,到 `31B`、`70B`、`120B` 的大模型;从纯文本推理,到图像、视频、音频和 `Physical AI reasoning`。
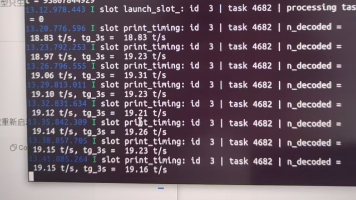
我们知道NX16G一般也就跑跑7B的模型,他说能跑20b的GPT-OSS,说实话我是不信的。从落地价值来看,该方案精准适配了体积受限、电池供电、需要离线本地交互的边缘场景,比如小型服务机器人、工业巡检终端、嵌入式智能座舱、离线智能终端等,在不提升硬件规格、不增加体积功耗的前提下,实现了大模型能力的升级。2. 开发板实际性能受固件版本、驱动迭代、模型版本、散热方案、供电质量、系统配置等多重因素影响,
在高温无网的棉田中,搭载Jetson与TensorRT的边缘设备实现了低延迟、高精度的病虫害识别。通过层融合、INT8量化与内核调优,模型推理速度大幅提升,同时保持稳定功耗与实时性,支撑起全天候智慧农业应用。
摘要:本文深入探讨NVIDIA Jetson平台(以AGX Orin为例)上GPU/NPU加速计算的两大核心框架——CUDA与OpenCL的实践方法。重点剖析Jetson统一内存架构(UMA)下的内存管理策略、CUDA核函数编写与优化技巧,以及OpenCL跨平台异构计算模型。通过卷积运算实例,对比分析两种框架在嵌入式场景下的性能差异与优化路径,为边缘AI、自动驾驶、机器人视觉等应用提供工程级参考。
本文详细介绍了如何从树莓派无缝迁移到Jetson平台进行GPIO开发,包括环境配置、引脚映射、高级功能及常见问题解决方案。Jetson.GPIO库与RPi.GPIO高度兼容,使开发者能够快速移植现有代码,同时享受更强大的性能和AI计算能力。
在边缘计算和嵌入式AI开发中,CUDA作为NVIDIA GPU的并行计算平台,是实现深度学习模型加速的核心技术。其原理在于通过统一计算架构,利用GPU的数千个核心进行大规模并行处理,从而显著提升矩阵运算和神经网络推理的速度。这一技术价值在于将原本只能在云端服务器运行的复杂AI模型,部署到Jetson这类资源受限的边缘设备上,实现低延迟、高能效的实时智能应用。常见的应用场景包括机器人视觉导航、无人机
接口典型传感器Python 库通信速率GPIOLED、按钮、超声波I2Csmbus2100-400kHzSPIspidev1-10MHzUARTGPS、蓝牙、STM32pyserialPWM舵机、电机、蜂鸣器50-1000HzGPIO 权限:加入gpio用户组,避免 sudoI2C 扫描:先用i2cdetect确认设备地址多传感器并行:每个传感器独立采集线程数据持久化:JSON 导出 + SQLi
本文介绍了如何在星图GPU平台上自动化部署通义千问2.5-7B-Instruct镜像,实现大语言模型在边缘计算场景的应用。该方案支持用户快速在本地或离线环境下搭建AI助手,典型应用场景包括智能客服、代码辅助与文档分析,有效保障数据隐私并降低延迟。
RAG 重排序模型实测:MiniLM → BGE-Reranker-v2-m3 替换全流程——中文召回从废到神(Jetson GPU 部署)问题:RAG 中文搜不出来,不是向量库的锅你的 R
NVIDIA Jetson系列是专为边缘AI计算设计的高性能嵌入式平台,提供从入门到旗舰的多层次产品选择。当前主力Orin世代包含Orin Nano(67TOPS)、Orin NX(157TOPS)和AGX Orin(275TOPS),覆盖从智能摄像头到工业检测等场景,而顶级旗舰AGX Thor(800+TOPS)面向自动驾驶和具身智能等前沿应用。该系列采用统一软件生态JetPack SDK,支持
本文介绍了如何在星图GPU平台上自动化部署TensorFlow-v2.9镜像,并将其适配于Jetson等边缘设备进行AI推理。该方案通过定制化编译与模型优化,解决了边缘部署的兼容性与性能瓶颈,可广泛应用于智能摄像头实时图像分析、无人机自主导航等低功耗、高响应的边缘计算场景。
本文介绍了如何在星图GPU平台上自动化部署AIGlasses_for_navigation可穿戴智能设备镜像,实现AI智能眼镜的快速环境搭建。该镜像集成了针对Jetson Orin Nano等边缘设备优化的实时导航AI模型,可应用于视障辅助出行等场景,通过模型轻量化与推理优化,在资源受限的设备上实现流畅的实时环境感知与导航功能。
本文介绍了如何在星图GPU平台自动化部署“实时手机检测-通用基于DAMO-YOLO和TinyNAS WebUI”镜像,实现高效边缘计算目标检测。该方案专为Jetson平台优化,适用于智能安防、工业质检等实时视觉检测场景,显著提升边缘设备的推理速度和能效比。
本文介绍了如何在星图GPU平台自动化部署FLUX.1-dev旗舰版镜像,实现边缘端AI图像生成与编辑。该方案基于Jetson设备,支持移动端实时图片风格转换和智能增强,适用于户外创作、现场设计等无需网络依赖的场景,兼顾数据隐私与低延迟处理。
本文介绍了如何在星图GPU平台上自动化部署HG-ha/MTools开箱即用镜像,快速构建边缘AI应用。该镜像集成了图片处理、音视频编辑等轻量化AI工具链,用户可便捷地将其部署于Jetson Orin Nano等边缘设备,实现如实时图片背景移除、画质增强等典型AI处理场景,显著降低开发门槛。
本文介绍了如何在星图GPU平台上自动化部署MogFace人脸检测模型-large镜像,专为Jetson Orin等边缘设备优化。通过预置TensorRT加速与ONNX Runtime,用户可快速启用实时人脸检测功能,典型应用于智能门禁、车载DMS及安防终端中的视频流人脸定位与分析。
本文介绍了如何在星图GPU平台自动化部署lite-avatar形象库镜像,实现轻量化数字人终端的快速搭建。该方案基于Jetson Orin Nano边缘设备,能够驱动150+预训练数字人形象,并支持实时口型驱动,可广泛应用于智能客服、虚拟教师等交互场景,提升终端AI体验。
本文详细介绍了在Jetson Nano/Orin设备上快速部署YOLOv8目标检测模型的实战指南。通过CLI命令行工具,用户可在5分钟内完成从图片检测到结果可视化的全流程,特别适合快速验证环境和体验AI视觉的即时反馈。文章还提供了高级参数调优、视频流实时检测及模型训练验证等实用技巧,帮助开发者高效利用英伟达边缘计算设备。
本文详细介绍了在Jetson开发板上编译支持CUDA加速的OpenCV的完整流程,从环境准备、依赖解决到编译配置与性能验证。通过启用CUDA加速,图像处理速度可提升5-10倍,显著提升计算机视觉算法的运行效率。文章还提供了常见问题的解决方案和生产环境部署建议,帮助开发者充分发挥Jetson的GPU性能优势。
本文介绍了如何在星图GPU平台上自动化部署Qwen3-ForcedAligner-0.6B镜像,实现ARM架构Jetson设备的免配置语音识别。该镜像能够将音频高精度转换为文字,并生成字级别时间戳,典型应用场景包括自动化会议记录和视频字幕制作,所有处理均在本地完成,保障隐私安全。
本文介绍了如何在星图GPU平台上自动化部署最新 YOLO26 官方版训练与推理镜像,专为Jetson等边缘设备优化。该镜像支持开箱即用的姿态检测与目标识别,典型应用于工业智能巡检、农业虫害识别及实时视频流分析等边缘AI场景,显著降低部署门槛与运维成本。
本文详细介绍了在Jetson Nano/Xavier NX上配置Docker环境的避坑指南,涵盖PyTorch、TensorFlow和TensorRT的安装与优化。通过实战经验分享,帮助开发者解决ARM架构下的环境配置难题,提升AI模型部署效率,特别适合边缘计算开发者参考。
本文详细介绍了在英伟达Jetson平台上配置YOLOv8环境的实战经验,涵盖依赖冲突解决、PyTorch与torchvision定制安装、YOLOv8验证及TensorRT加速部署。特别针对Jetson平台的特性,提供了从基础环境准备到性能优化的完整解决方案,帮助开发者高效部署目标检测模型。
本文介绍了如何在星图GPU平台上自动化部署“海景美女图 - 一丹一世界FLUX.1 AI 图像生成服务v1.0”镜像,并验证其在ARM架构Jetson设备上的可行性。该镜像能够基于文本提示词快速生成高质量的海景主题AI图像,适用于个人创作灵感激发、电商内容制作等场景,为边缘AI应用提供了便捷的解决方案。
本文详细介绍了Jetson Xavier NX开发板的环境配置全流程,包括系统监控、CUDA与cuDNN安装、深度学习框架配置及系统优化技巧。通过使用jetson-stats工具集和jtop监控工具,开发者可以充分发挥64核ARM CPU和384核Volta GPU的性能潜力,实现高效的AI模型部署与优化。
本文介绍了如何在星图GPU平台上自动化部署LiuJuan Z-Image Generator镜像,实现AI图片生成功能。该镜像针对ARM架构Jetson设备深度优化,用户可通过简单的配置步骤快速搭建本地AI绘画环境,应用于个人创意设计、产品原型可视化等场景,显著提升边缘设备上的内容创作效率。
本文深入探讨了Jetson Xavier NX上OpenCV的CUDA加速性能差异,通过实测对比展示了CUDA加速在图像处理、目标检测等任务中的显著优势。从环境配置到性能优化,为开发者提供了全面的技术指南,帮助充分释放边缘计算设备的GPU潜力。
本文分享了在Jetson Nano/Orin设备上实现离线语音识别的实战经验,详细对比了Whisper和Sherpa-onnx Sense Voice模型的性能表现。针对边缘设备的特殊挑战,如低延迟和内存限制,作者最终选择了Sense Voice模型,并提供了部署优化技巧和完整实施方案,为开发者提供了实用的离线语音解决方案。
本文详细介绍了在Jetson平台上搭建YOLOv8开发环境的完整流程,重点解决ARM架构下的版本冲突问题。通过英伟达Jetson专用版本的PyTorch和torchvision安装指南,以及numpy、scipy等关键依赖的版本控制策略,帮助开发者高效部署目标检测模型,并提供了Docker化部署和TensorRT加速的实战技巧。
本文提供了一份详细的Jetson Nano/Xavier NX存储扩容指南,涵盖SSD和USB两种方案的选择、硬件安装避坑、系统迁移流程及性能优化技巧。针对NVIDIA Jetson开发板的2GB存储限制,手把手教你如何通过扩容提升边缘计算设备的实用性,特别适合开发者解决存储不足的痛点。
在 NVIDIA Jetson 边缘计算平台上(如 Jetson AGX Orin, Orin NX, Xavier NX, Nano 等),官方默认预装的 OpenCV 通常是不支持 CUDA 加速的(仅 CPU 版本)。对于从事计算机视觉(CV)开发的工程师来说,无法利用 GPU 加速会极大地限制模型推理、图像预处理的效率。手动从源码编译 OpenCV 支持 CUDA 是一项繁琐的工作,涉及到
本文介绍了如何在星图GPU平台上自动化部署SiameseUIE 模型部署镜像 README,实现边缘设备上轻量级中文人物与地点信息抽取。该镜像专为Jetson等资源受限环境优化,可稳定应用于政务工单地址提取、安防巡检记录分析等典型场景,显著提升边缘NLP落地效率与可靠性。
本文详细介绍了NVIDIA NIM微服务在边缘计算中的实战部署,特别针对Jetson设备进行了优化。通过轻量化容器、硬件感知优化和离线推理能力,NIM微服务显著降低了内存占用和推理延迟,提升了能效比。文章提供了从环境准备到容器部署、性能调优的全流程指南,并展示了智慧变电站和农业无人机等典型应用场景。
本文详细记录了在Jetson设备上排查Python虚拟环境中jtop版本冲突的实战经验。通过分析jtop的工作原理和版本隔离机制,提供了三种解决方案:升级虚拟环境、降级宿主机版本和版本隔离部署,并分享了预防措施与最佳实践,帮助运维工程师有效管理边缘计算设备的版本兼容性问题。
Jetson
——Jetson
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AMD开发者中国社区
AMD开发者中国社区

 DeepSeek技术社区
DeepSeek技术社区
 DAMO开发者矩阵
DAMO开发者矩阵

 AI Agent技术社区
AI Agent技术社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 脑启社区
脑启社区

 AI硬件创业社区
AI硬件创业社区


 AtomGit开源社区
AtomGit开源社区



 全球具身智能开发者社区
全球具身智能开发者社区

 腾讯云开发者社区
腾讯云开发者社区












