




- @ViatorSun
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
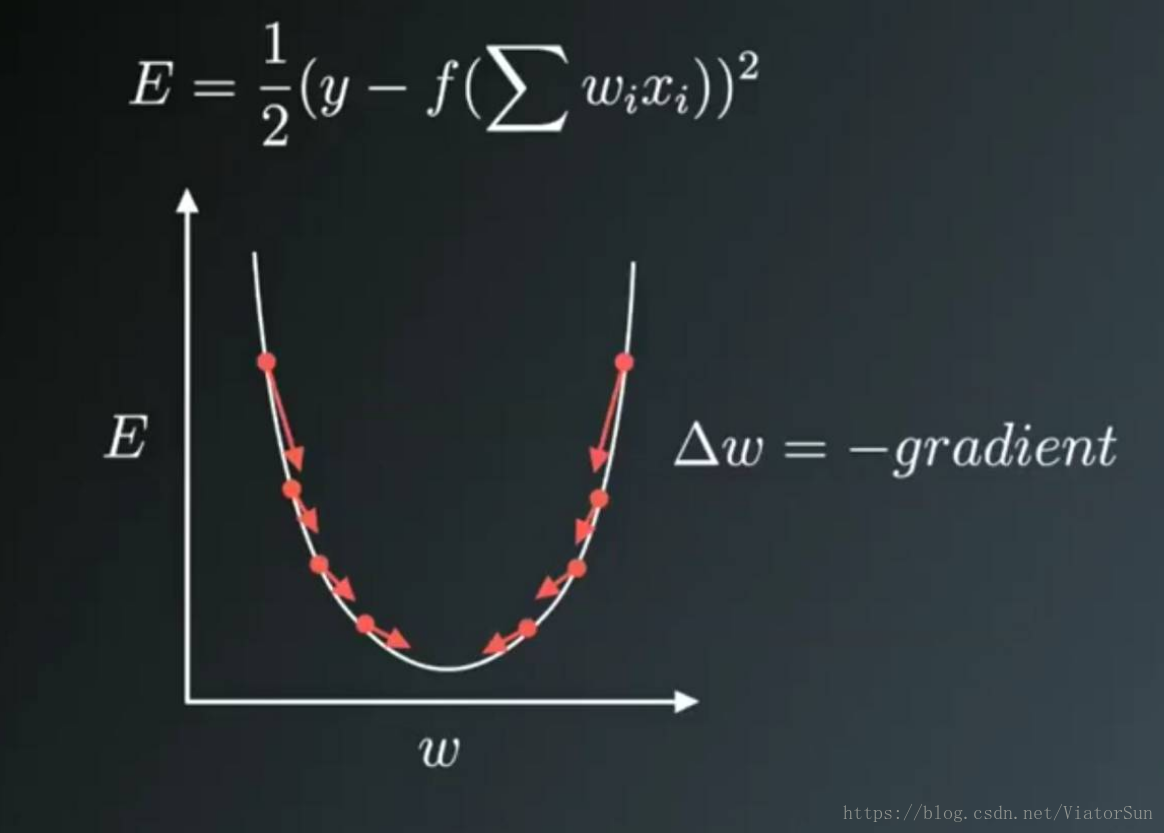
优化算法的功能,是通过改善训练方式,来最小化(或最大化)损失函数E(x)。模型内部有些参数,是用来计算测试集中目标值Y的真实值和预测值的偏差程度的,基于这些参数,就形成了损失函数E(x)。比如说,权重(W)和偏差(b)就是这样的内部参数,一般用于计算输出值,在训练神经网络模型时起到主要作用。在有效地训练模型并产生准确结果时,模型的内部参数起到了非常重要的作用。这也是为什么我们应该用各种优化策略和算
相对于深度学习,传统机器学习的流程往往由多个独立的模块组成,比如在一个典型的自然语言处理(Natural Language Processing)问题中,包括分词、词性标注、句法分析、语义分析等多个独立步骤,每个步骤是一个独立的任务,其结果的好坏会影响到下一步骤,从而影响整个训练的结果,这是非端到端的。而深度学习模型在训练过程中,从输入端(输入数据)到输出端会得到一个预测结果,与真实结果相比较..
相对于深度学习,传统机器学习的流程往往由多个独立的模块组成,比如在一个典型的自然语言处理(Natural Language Processing)问题中,包括分词、词性标注、句法分析、语义分析等多个独立步骤,每个步骤是一个独立的任务,其结果的好坏会影响到下一步骤,从而影响整个训练的结果,这是非端到端的。而深度学习模型在训练过程中,从输入端(输入数据)到输出端会得到一个预测结果,与真实结果相比较..
优化算法的功能,是通过改善训练方式,来最小化(或最大化)损失函数E(x)。模型内部有些参数,是用来计算测试集中目标值Y的真实值和预测值的偏差程度的,基于这些参数,就形成了损失函数E(x)。比如说,权重(W)和偏差(b)就是这样的内部参数,一般用于计算输出值,在训练神经网络模型时起到主要作用。在有效地训练模型并产生准确结果时,模型的内部参数起到了非常重要的作用。这也是为什么我们应该用各种优化策略和算
不管是提前批的准备还是秋招以及来年的春招,leetcode的算法几乎是人人必备的,虽然leetcode已经提供了在线编辑功能,但是虽优秀,但不完美!在此也提供给小伙伴在 Pycharm上面如何优雅的刷 leetcode算法,并且编辑后的代码可以保存在本地,非常方便保存记录以及分享!

相信大家在使用 labelme 标注数据之后,都需要将 json文件 转换为对应的标签图,但是每次一张一张转换,费时又费力,特别是转换后还需要再将 标签图修改名字,然后再移动到特定的文件夹,就又增添了不少工作量,作者也是深受其累。作为一名开发人员,怎么可以让这点问题难住呢,自然是让程序自动处理,而我们应该是 在旁刷抖音才对 🤓️🤓️🤓️此外,对于labelme 每次标注的时候,需要加载 图片

1、执行下面的命令查看休眠模式的情况。查看上图所示:如果 sleep 状态是 loaded,表示自动休眠模式是处于开启状态。2、执行下面的命令来关闭ubuntu的自动休眠。3、再次使用第一行命令进行查看休眠模式的状态。查看下面图示:sleep 的状态如果变成了 masked,则表示ubuntu的自动休眠模式被关闭了。

摘要:在将FastAPI服务打包为Docker镜像时,发现Postman请求失败。主要原因是容器内服务绑定到127.0.0.1导致外部无法访问。解决方案包括:1)修改uvicorn.run的host参数为0.0.0.0;2)通过docker inspect获取容器IP地址(如172.17.0.2)。测试表明,使用容器IP地址(http://172.17.0.2:8080/video)可成功访问服务
方法一:Google gsutil工具MSCOCO数据集较大,可以使用Google gsutil工具搭配命令行下载sudo apt-get install aria2aria2c -c <url>即为COCO官网下载地址train2017:http://images.cocodataset.org/zips/train2017.zipval2017:http://images.coco
如果作为一名程序员,你连GitHub都没有听过或者用过的话,那真是太遗憾了。GitHub的使用可是程序员在职业生涯中的一项必备技能啊,最近在网上搜了一下,发现有好多童鞋都在提问GitHub的使用教程,其实网上关于GitHub使用的优秀教程还真是不少,本人也在其中获益颇多,好了,我们今天就来谈一个关于GitHub的话题,”如何在GitHub上发现优秀的开源项目”。Explore首先登录G...