- @superman_xxx
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
居家办公的中国程序员,深夜写代码,显示器蓝光映照,黑框眼镜,乱糟糟的头发,穿着宽松T恤和睡裤,手边放着半杯冷掉的茶和吃剩的泡面,表情专注中带着一丝疲惫,背景是堆满技术书籍的书架和二次元手办,实际年龄28岁但看起来像35岁,内心OS是“写完这段就睡”,但其实是凌晨3点,窗外下着小雨,居家办公日常,自拍模式,手机拍摄,(`柔和的动画风格` 动画风加上这几个词)
大数据降维打击与上帝视角下的图数据大数据应用降维商业史上的降维打击用图思维降维大数据应用上帝视角下的图数据图数据的定义什么是上帝视角下的图数据什么事实图数据图数据在业务端的可能产出知识图谱和图数据的关系大数据应用降维商业史上的降维打击商业史上有哪些降维打击的经典案例用图思维降维大数据应用图数据库的高性能关系算力也许可以帮助大数据应用降维。对复杂基础数据的建模融合关联最终形成一个高度整合的图,可以为
其中 Agents 使用 LLMs 来确定采取哪些行动以及以何种顺序采取行动。操作可以是使用工具并观察其输出,也可以是返回给用户。如果使用得当,代理可以非常强大。本文章的目的是向您展示如何通过最简单、最高级别的 API 轻松使用 Agents 。

人物关系知识图谱一、背景将结构化数据通过关系预处理程序处理为图数据库可以查询的数据,示例是将其中一部分(人物关系数据)可视化表示。二、用到的技术技术点:图数据库Neo4j,d3.js,java,css,spring boot开发工具:IDEA专业版(可找学生账号注册免费使用一年,社区版不支持WEB开发)三、可视化效果(所有可视化效果均带有力布局效果)1.节点与关系均...
一、试用方法1、安装neo4j桌面版(不需要单独设置环境变量)2、打开桌面版NEO4J建立本地测试库3、打开桌面版NEO4J设置URLhttp://s3-eu-west-1.amazonaws.com/ux.neotechnology.com/assets/neo4j-insight-latest/index.html4、启动2中建立的测试库点击Development...
结构有ResNet 50、ResNet 152、ResNet 200,考虑耗时原因只跑了ResNet 152网络结构的forward。# coding:UTF-8"""Typical use:from tensorflow.contrib.slim.nets import resnet_v2ResNet-101 for image classification into 1000 class
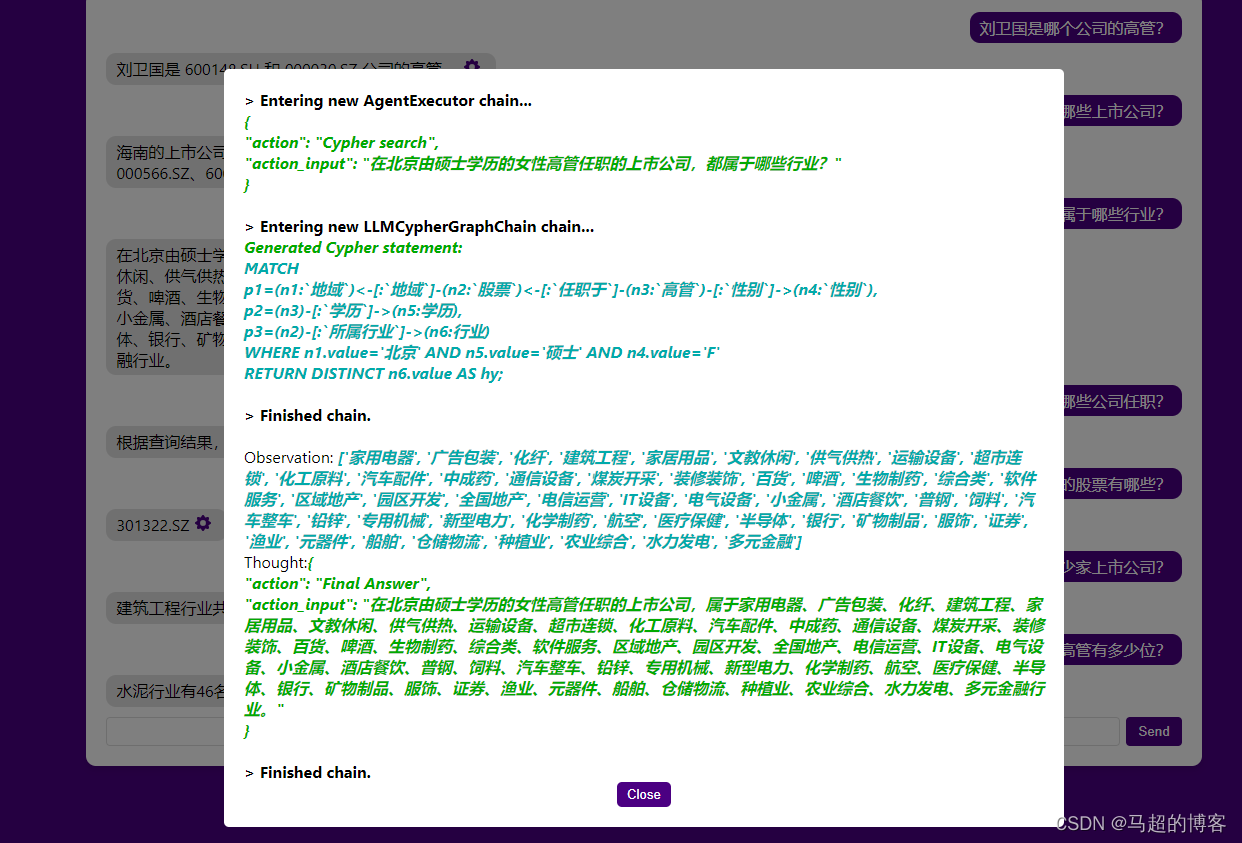
通过测试发现,设计合适的Prompt工程以后,GPT3.5可以基于样例准确生成Cypher,但是对于样例没有覆盖的问句,Cypher经常会错误生成。进行排序(评估样例问题和当前提问的相似程度),然后拼接为长度小于2048的字符串传入GPT3.5的接口(GPT-3.5 的上下文最多支持 2k 汉字或 8k 英文字符 的内容);配置时,GPT4不会生成Cypher,GPT3.5会使用网络资料生成Cyp

分享一个neo4j数据封装类,这个类封装的JSON数据与neo4j的rest-api返回的数据格式类似。负责区分不同查询/*** @param cypher@return* @Description: TODO(跳过条件添加直接使用CYPHER查询 - 默认返回节点或者关系的所有属性字段)*/@Overridepublic JSON...
当一个提问不存在类似的Example时,模型不会生成Cypher或生成一个不存在的Cypher(图数据库中模式不存在不会影响最终结果,因为结果为空),这类可以视为图谱回答不了的问题。Prompt中会传入一些样例问题和Cypher,模型通过样例问题和Cypher就能学会该类的问题和Cypher模式,并应用在同类不同参数的查询上(其中一些参数模型也能。通过测试发现,设计合适的Prompt工程以后,GP

然后,代理向 LLM 模型发送请求,其中包括用户问题和代理提示,代理提示是代理应该遵循的一组自然语言指令。对于工具的使用大多数情况下,我们的第一反应是使用可用的工具从外部来源获取更多信息。使用 LangChain 构建应用程序后,当有用户提问时,系统会先通过代理找到合适的工具(知识图谱),然后通过工具获取数据,最后由 LLM + 私域数据生成一个流畅表达并回复用户。整个过程代理的调用会更复杂一些,