




- @weixin_39907681
简介
更多AI大模型应用开发学习知识,尽在聚客AI学院(https://edu.guangjuke.com/)
擅长的技术栈
可提供的服务
暂无可提供的服务
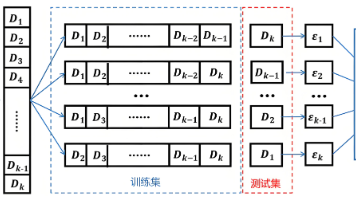
掌握监督/无监督学习、过拟合/欠拟合、偏差/方差、评估指标和交叉验证是机器学习入门的核心基础。本文通过理论解析+可视化+代码实战,帮你构建系统认知框架。
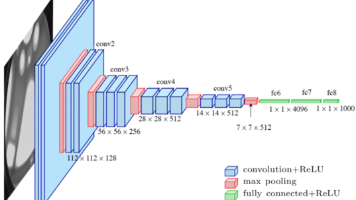
1.卷积神经网络CNN2.卷积神经网络概述3.什么是卷积?4.图像处理中的卷积5.卷积神经网络的结构6.卷积层 Convolutional Layer7.池化层 Pooling Layer8.卷积神经网络中的超参数9.卷积核尺寸 Kernel Size10.滑动窗口步长 Stride11.边缘填充 Padding12.卷积核的个数 Number of Kernels13.感受野 Receptive
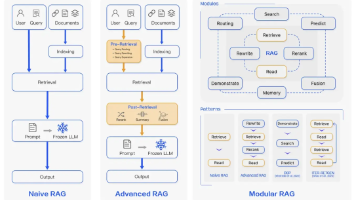
第一章 应用层:四大核心场景深度解析1.1 增强检索类应用1.2 智能体类应用1.3 事务处理类应用1.4 分析决策类应用第二章 应用技术层:五大核心技术突破2.1 智能体工程化2.2 提示词工程进阶2.3 微调技术深度优化2.4 数据向量化工程2.5 数据获取与治理第三章 模型层:前沿模型架构解密3.1 大语言模型(LLM)3.2 语言-视觉大模型3.3 文本理解模型3.4 多模态监测与分割大模
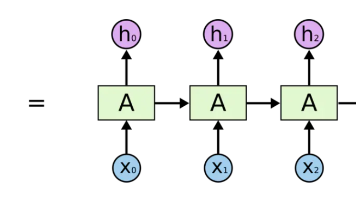
1.循环神经网络 RNN2.Native RNN模型3.为什么需要循环神经网络4.循环神经网络的结构5.数学语言描述RNN结构的前向传播与反向传播6.传统RNN的问题7.记忆力过强8.处理长序列时存在梯度消失和梯度爆炸问题9.梯度消失带来的问题的直观感受
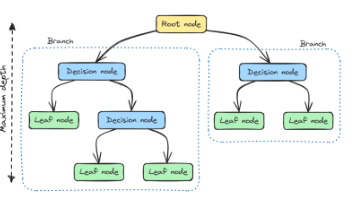
1.机器学习 Machine Learning2.机器学习分类3.按学习范式分类4.有监督学习 Supervised Learning5.有监督学习的基本定义6.有监督学习的典型应用7.常见的有监督学习的算法8.无监督学习 Unsupervised Learning9.无监督学习的基本定义10.无监督学习的典型应用11.常见的无监督学习的算法12.自监督学习 Self-supervised Lea
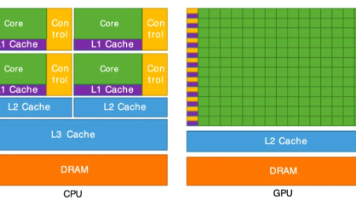
1.GPU与CPU:计算硬件与大模型推理2.计算机硬件基础3.什么是CPU?4.什么是GPU?5.GPU vs CPU 类型解析6.GPU在大模型推理中的应用7.查看设备GPU信息8.GPU硬件选择策略
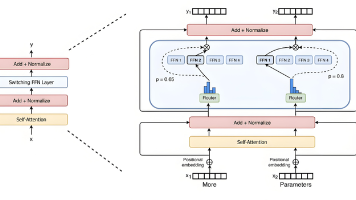
近年来,混合专家模型(Mixture of Experts, MoE)技术在大模型领域迅速崛起,成为解决计算效率和扩展性问题的关键创新。我将从核心原理、显著优势、落地应用以及当前挑战四个方面,全面解析MoE技术。内容力求深入浅出,并结合图文增强理解。现在,让我们一起揭开MoE的神秘面纱。
1.机器学习 Machine Learning2.机器学习分类3.按学习范式分类4.有监督学习 Supervised Learning5.有监督学习的基本定义6.有监督学习的典型应用7.常见的有监督学习的算法8.无监督学习 Unsupervised Learning9.无监督学习的基本定义10.无监督学习的典型应用11.常见的无监督学习的算法12.自监督学习 Self-supervised Lea
在AI Agent技术快速发展的2026年,OpenClaw作为最热门的开源AI Agent网关项目之一,其多智能体协同能力为构建企业级AI应用提供了全新范式。本文将从架构设计、工程实现到实战优化,全面解析如何基于OpenClaw构建稳定、高效的多智能体系统,涵盖从单Agent到复杂团队协作的完整演进路径。

在AI Agent技术快速发展的2026年,OpenClaw作为最热门的开源AI Agent网关项目之一,其多智能体协同能力为构建企业级AI应用提供了全新范式。本文将从架构设计、工程实现到实战优化,全面解析如何基于OpenClaw构建稳定、高效的多智能体系统,涵盖从单Agent到复杂团队协作的完整演进路径。