




- @lyy2017175913
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文主要介绍如何在 Windows 系统快速部署 Ollama 开源大语言模型运行工具,并安装 Open WebUI 结合 cpolar 内网穿透软件,实现在公网环境也能访问你在本地内网搭建的 llama2、千文 qwen 等大语言模型运行环境。

今天给大家分享deepseek的本地部署教程一、部署Ollama(多平台选择安装)Ollama 支持 Linux/macOS/Windows,需根据系统选择安装方式。1. Linux 系统部署适用系统:Ubuntu/Debian/CentOS 等
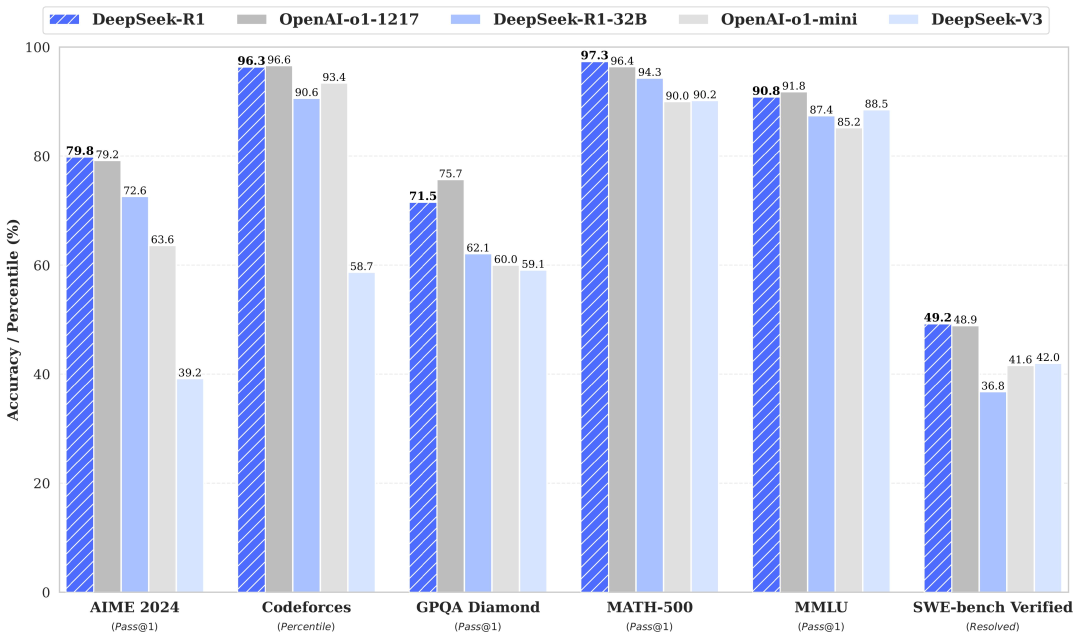
论文主要提出Q-Former(Lightweight Querying Transformer)用于连接模态之间的gap。BLIP-2整体架构包括三个模块:视觉编码器、视觉和LLM的Adapter(Q-Former)、LLM。其中Q-Former是BLIP-2模型训练过程中主要更新的参数,视觉Encoder和大语言模型LLM在训练过程中冻结参数。
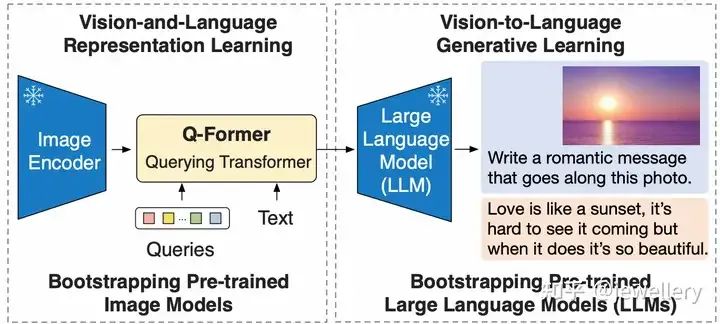
在深入探讨训练过程之前,首先介绍一些相关术语:智能体:训练来做正确决策的实体。在这个例子中,目标是训练机器人做出移动决策,所以机器人就是智能体。环境:环境是智能体与之互动的外部系统。在本例中,随着训练过的机器人(智能体)在网格内移动,网格就充当了环境。状态:代表智能体在每个时间 t 的位置。在起始时刻,即时间_t_0,机器人(智能体)位于左下角,因此时间_t_0的状态是左下角,由坐标(0,0)表示
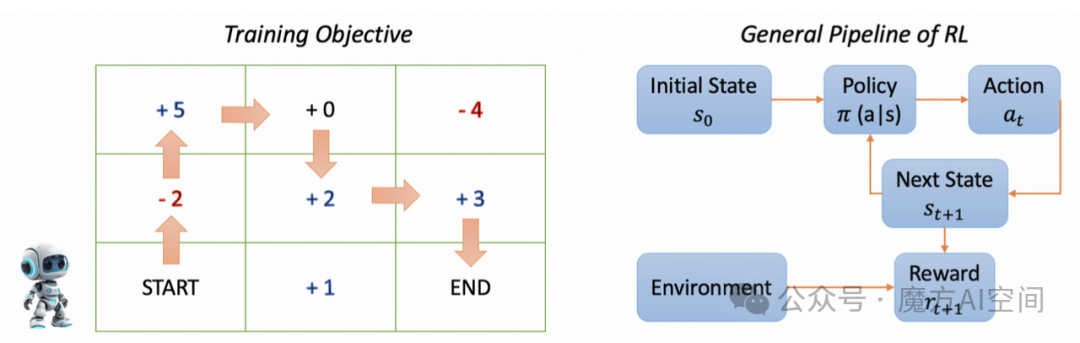
FastGPT 是目前 Prompt 串接做的最好的项目,知识库核心流程图如下:FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!FastGPT 官网地址:https://doc.fastgpt.in/docs/intro/FastGPT 在线体验:https://fastg
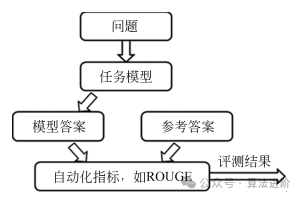
自2017年Transformer模型提出以来,自然语言处理研究逐步转向基于该框架的预训练模型,如BERT、GPT、BART和T5等。这些预训练模型与下游任务适配后,持续刷新最优结果。然而,现有评测方法存在广度和深度不足、数据偏差、忽视模型其他能力或属性评估等问题。因此,需要全面评测和深入研究模型的各项能力、属性、应用局限性、潜在风险及其可控性等。本文回顾了自然语言处理中的评测基准与指标,将大语言
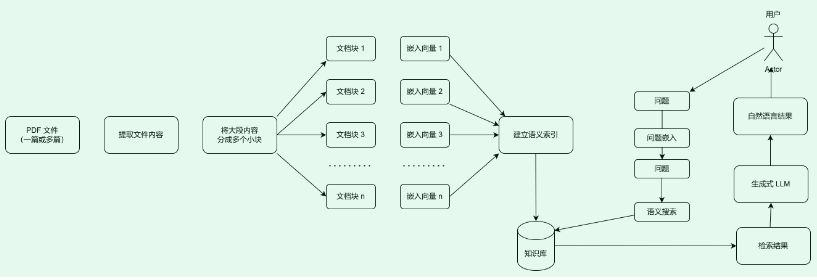
LLM 支持的最强大的应用程序之一是复杂的问答 (Q&A) 聊天机器人。这些应用程序可以回答有关特定源信息的问题。这些应用程序使用一种称为检索增强生成 (RAG) 的技术。
在深入学习LLM(大型语言模型)之前,了解NLP(自然语言处理)的基本原理对于应用LLM至关重要。虽然在具体的LLM训练和应用中,NLP相关概念的内容应用可能有限,但这并不削弱了解NLP基础知识的重要性。这种基础知识有助于更好地理解LLM的训练方法、功能以及其在各种领域的潜在应用。因此,在学习LLM之前,建议先掌握NLP的基础原理,以便更全面地掌握这一领域的知识,并能够更好地应用它们。感兴趣的同学

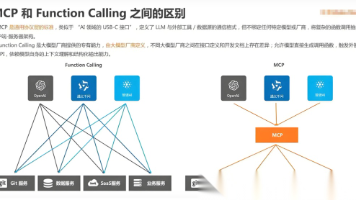
MCP与传统大语言模型工具调用存在三大核心差异:架构上,MCP采用标准化协议层实现工具与LLM解耦,而传统方式是嵌入式函数耦合;交互流程上,MCP支持动态协作与双向通信,传统方式仅限于线性调用;生态扩展性上,MCP实现跨平台兼容避免厂商锁定,传统方式则存在扩展性局限。MCP通过协议化架构更适合构建生产级多模态AI应用,代表了大模型工具调用的下一代技术方向。
" 大型语言模型在执行任务时产生的出乎意料的行为、思路或想法被称为涌现。然而,一篇 NeurIPS2023 的获奖论文提出了一个观点,即所谓的涌现能力是由于研究者选择的度量标准而产生的,而不是模型行为在规模扩展中发生了根本变化。文章通过数学方法,构建了一种关于大型语言模型涌现能力的替代解释。同时,文章指出涌现能力在模型的规模扩展时可能会以突然而意外的方式出现,而无法通过简单的线性推断进行预测。这说
