登录社区云,与社区用户共同成长
邀请您加入社区
TS-h987XU-RP 混合架构存储服务器,通过在 1U 的极致紧凑空间内,将 U.2 NVMe 点对点直连总线与大容量 SATA 机械盘阵并联部署,构建起了一个具备高抗震耐受度与极低时延响应的边缘存算底座。该方案有效化解了高频随机小文件时序流与大体积非结构化图像写入交织下的磁盘总线冲突,在无需建立恒温弱电房的前提下,将核心写入时延稳定在低位。
同时,对出厂合规目录配置。系统配置了 Qfiling 自动化流转规则,在夜间非生产低负载时段,引擎自动扫描前置的高速闪存层,识别文件内嵌的“焊缝编号、动车组批次、拍片日期”等元数据标签,在左侧 24 盘位机械阵列池中自动创建结构化目录树并执行物理转储,实现了高速闪存空间的常态化自动释放。焊接机器人下传的高频多光谱时序日志优先与该闪存缓冲层进行高速数据确认,在微秒内向工业网关返回 ACK 信号,后续
C++单元测试框架是软件开发过程中至关重要的工具,它允许开发者对代码中的最小可测试单元(通常是函数或类方法)进行验证,确保其按预期工作。通过自动化测试,开发者能够快速捕捉代码变更引入的错误,提高代码质量和可维护性。常见的C++单元测试框架包括Google Test、Catch2和Boost.Test等,它们提供了丰富的断言宏、测试用例组织方式和测试夹具功能,帮助开发者构建稳定可靠的测试套件。
这些工具和框架与C#语言深度集成,形成了一个完整的开发栈,使得从桌面应用、Web服务到移动应用和云原生应用的开发都能获得一致性的体验。C#作为一种现代化的多范式编程语言,其核心特性建立在强大的类型系统和面向对象编程(OOP)范式之上。完整的OOP支持允许开发者使用封装、继承和多态三大特性构建复杂的软件系统,其中类和对象的概念构成了程序的基本构建块。异步编程模型(async/await)彻底改变了并
在 Java 开发中,finally 块常用于确保资源(如文件、数据库连接、网络套接字等)的释放,以防止内存泄漏和系统资源耗尽。本文深入探讨 finally 块的工作原理、适用场景、常见误区以及现代替代方案(如 try-with-resources),帮助开发者编写更健壮、高效的代码。通过实例分析,揭示 finally 块在异常处理中的关键作用,并强调其在多线程和复杂逻辑下的潜在问题。
24 年我来湾区后,在他们三番办公室见了他们的管理层,随便聊了聊工作生活的话题。今年夏天在美国时,又和他们的管理层聊了不少次,在三番办公室里给他们的创始人、CEO、CPO 等做了几个小时的演讲,觉得相互之间的技术都高度互补,Elastic 的高层对我个人非常友好和信任,于是就开始了这个收购案。对于 Jina AI 而言,这其中包含很多的复杂的因素,包括美国和中国之间的地缘政治(当然还有德国),多个
Jina是一个开源的云原生AI服务框架,专为构建和部署机器学习模型而设计。它支持gRPC、HTTP和WebSocket通信协议,能处理文本、图像等多模态数据。核心功能包括:通过Executor封装业务逻辑,使用Deployment部署服务,利用Flow编排复杂流水线。Jina提供动态批处理、流式输出和弹性扩展等特性,支持从本地开发到生产环境的无缝过渡。安装简单,只需pip install jina
最后也算是我的一点个人的坚持,我觉得既然是创业做公司,那目的就是要盈利。今年夏天在美国时,又和他们的管理层聊了不少次,在三番办公室里给他们的创始人、CEO、CPO 等做了几个小时的演讲,觉得相互之间的技术都高度互补,Elastic 的高层对我个人非常友好和信任,于是就开始了这个收购案。对于 Jina AI 而言,这其中包含很多的复杂的因素,包括美国和中国之间的地缘政治(当然还有德国),多个买方之间
深度学习检测不准确智能电表:一个案例研究python源代码,代码按照高水平文章复现,保证正确根据用电情况检测出故障的智能电表,并针对其进行更换,可以节省大量的资源。为此,我们开发了一种基于长短期记忆(long -term memory, LSTM)和改进的卷积神经网络(convolutional neural network, CNN)的故障智能电表深度学习检测方法。我们的方法使用LSTM根据从子
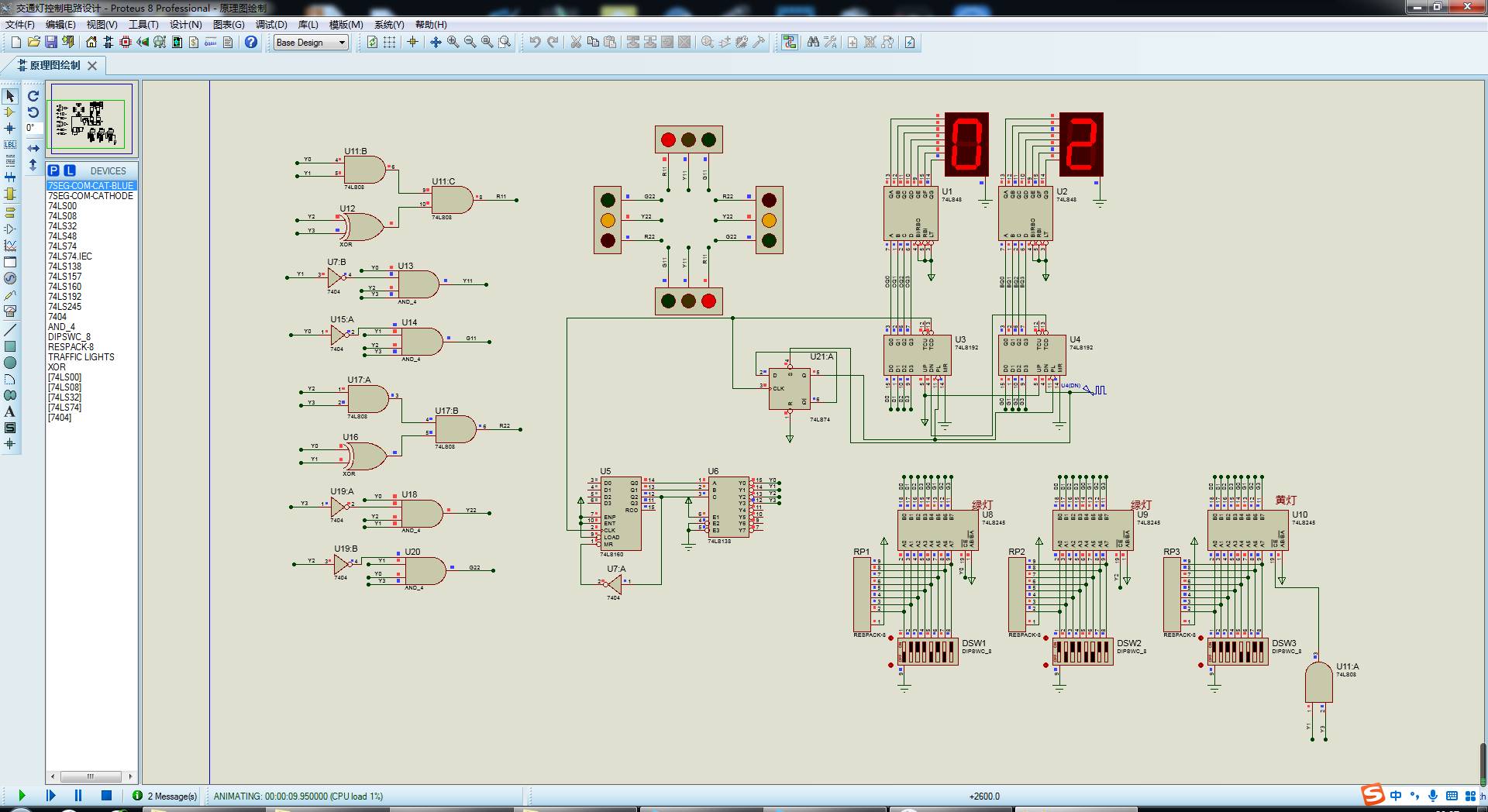
当倒计时归零的瞬间,会触发两个重要动作:通过74LS123单稳态电路产生装载脉冲,同时用74LS161状态计数器切换红绿灯状态。在十字路口的红绿灯里,藏着个有趣的数字世界。在测试过程中,意外发现把状态计数器的Q1接到蜂鸣器,能模拟真实的倒计时提示音。(2)脉冲A通过计数器进行计数,一共计数4次,每次输出一个信号状态,每个信号代表系统状态:东西通行、东西黄灯、南北通行、南北黄灯。(2)脉冲A通过计数
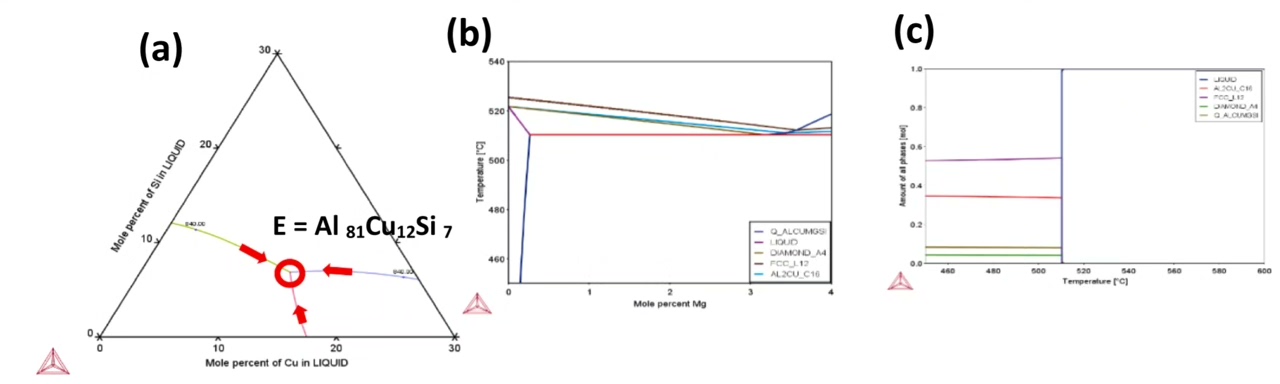
比如我们注意到当Al含量超过82%时,初生相会从θ-Al2Cu转变为Si晶体,这解释了为什么实际合金要把Al控制在81%左右——再高就容易出现硬脆的Si相影响性能。Al的区间给到75-85wt%,Cu给10-15wt%,Si通过差值自动计算。咱们的计算结果显示在Al-82.3Cu-12.1Si附近出现635℃的低温平台,和文献的Al81Cu13Si6(实测熔点630℃)相差约1.3%成分偏差。今天
LT6911UXC和LT9611UXC芯片凭借其强大的功能和灵活的配置,成为HDMI转MIPI应用中的佼佼者。无论是智能电视、车载显示系统还是工业显示设备,这两款芯片都能提供出色的性能和可靠性。对于开发者来说,龙讯半导体提供的丰富开发资源也大大降低了开发难度,缩短了开发周期。龙讯lt6911uxc,lt9611uxc资料,有源码固件,支持4k60,支持对接海思3519a和3559a,hdmi转mi
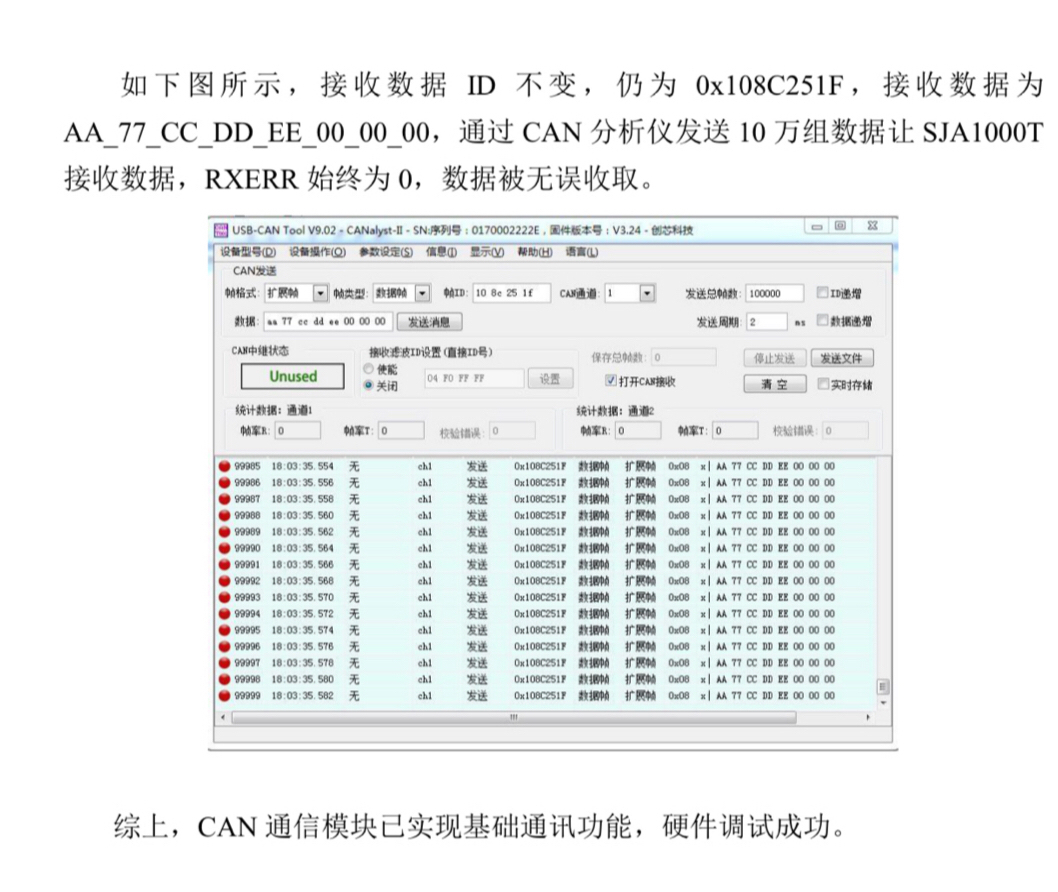
本文档详细解读基于FPGA的SJA1000T芯片CAN通信驱动代码,该代码套件支持标准帧(SFF)与扩展帧(EFF)通信,核心实现了CAN数据的发送、接收、寄存器配置及异常处理等功能。代码采用Verilog HDL语言开发,适配40MHz时钟频率,通过状态机驱动SJA1000T芯片完成CAN总线数据交互,适用于工业控制、汽车电子等对通信稳定性要求较高的场景。基于FPGA的CAN通信,FPGA驱动S
Elastic在EIS上推出jina-reranker-v2和v3多语言重排序模型,支持直接在Elasticsearch中实现高精度检索和RAG工作流。v2作为紧凑型模型支持函数调用和大规模推理,v3则通过listwise重排序提供更优性能。这些模型可与jina-embeddings-v3结合使用,开发者无需管理基础设施即可构建多语言搜索管道。Elastic Cloud试用用户现可体验这些功能。
2026年Embedding模型市场呈现出明显分化:OpenAI的text-embedding-3系列主打性价比、智源的BGE-M3以多语言多任务能力著称、Jina AI的jina-embeddings-v3在长文档处理上独树一帜。:Embedding成本是RAG系统最大的可控变量最终,Embedding模型只是地基,真正的RAG质量还取决于分块策略、检索算法、重排序和提示设计——不要把所有精力都
但LLM应用引入了一类新型的"模糊错误":- 模型返回了格式错误的JSON- 工具调用参数有问题- 模型生成了与预期完全不同的内容- 上下文超长导致截断- 幻觉——输出看起来正常,但内容是错的这些错误不会抛出异常,但会悄悄破坏你的业务逻辑。## 结语AI应用的错误处理不是一个可以"以后再做"的事情——在生产环境中,没有错误处理的AI应用会在最不恰当的时候崩溃,以最难调试的方式崩溃。从API调用到输
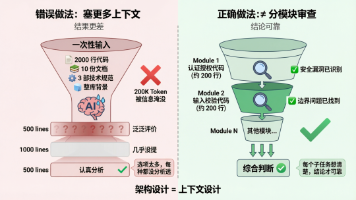
架构决策、业务理解、用户价值。从个人使用到团队基础设施的跨越,需要的不只是工具,更需要:统一的规范、共享的上下文、清晰的边界约定、以及持续的实践和迭代。- 架构决策(不能外包给AI)- 安全审查(AI会漏掉复杂的业务逻辑漏洞)- 业务逻辑验证(AI不懂你的业务规则)- 最终代码提交前的完整阅读### 5.2 建立AI协作规范。- 样板代码生成(CRUD、DTO、测试框架)- 代码解释和文档- 调试
目前中小电商最普遍的高危问题,一是私户收款隐匿收入,很多商家习惯用个人账户收货款,认为线上收入无需报税,这是当下最高频的违规点;一旦被稽查,不仅需要全额补缴税款,还会产生滞纳金,甚至面临0.5倍至5倍的罚款,得不偿失。:当下电商税务监管日趋严格,电商税全面落地,很多中小卖家陷入焦虑,担心补税、罚款,也不懂如何报税今天我们特邀深耕财税行业8年的肖潇老师,为广大电商老板答疑解惑,分享实操应对方案。:肖
多数人一看到复杂任务,本能反应就是"上多智能体"。这个本能往往是错的。正确的问法不是"要不要用多智能体",而是"这个任务到底需要什么类型的协调"。答案决定了你的整个架构。
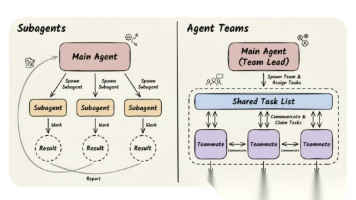
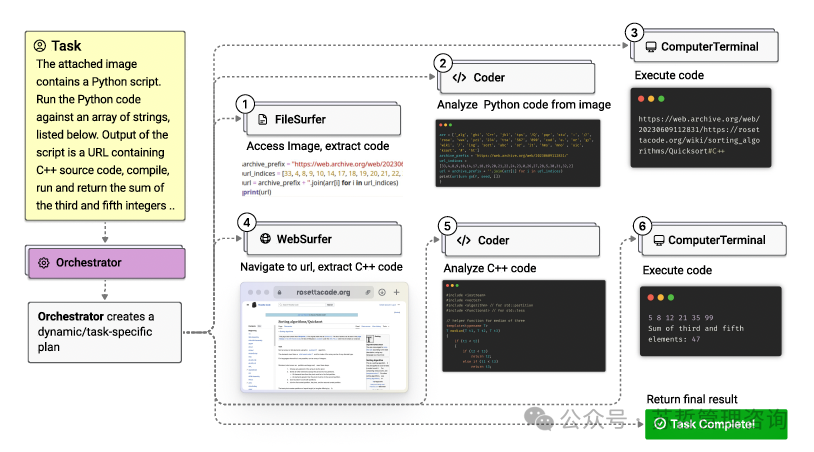
-微软解决复杂任务的通用多智能体- Magentic-One:微软研究人工智能前沿研究院图1:Magentic-One多智能体团队完成GAIA基准任务的插图。Magentic-One的Orchestrator智能体创建计划,将任务委派给其他智能体,并跟踪进展,根据需要动态修订计划。编排调度者可以将任务委派给一个文件冲浪者智能体来读取和处理文件,一个网页浏览者r智能体来操作网络浏览器,或者一个编码者
Jina-VLM:开源多语言视觉语言模型在ICLR 2026引关注 Jina-VLM是一个2.4B参数的开源视觉语言模型,在29种语言的VQA基准测试中表现优异。该模型创新性地结合SigLIP2视觉编码器和Qwen3语言解码器,采用注意力池化技术处理任意分辨率输入。ICLR 2026会议展示了AI领域的最新趋势:强化学习验证(RLVR)成为主流、测试时计算受到重视、视觉语言行动模型(VLA)快速发
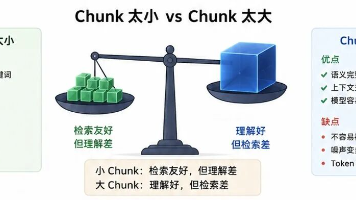
很多人在做 RAG 时,会把精力放在:* 模型选型* Prompt 优化* Rerank
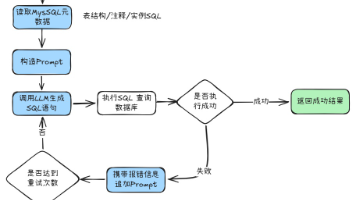
文本转`SQL`通俗的来说,就是用户输入自然语言,通过`LLM`大语言模型将自然语言结合表结构生成`SQL`的过程。
追求品类全、一站式配齐、性价比高:优先选择科学粮草官,全场景通用做高精尖科研、高纯度严苛实验:选用 TCI、Alfa Aesar 进口试剂日常科研、教学实验、预算适中:首选阿拉丁有机合成居多、低成本大批量采购:选择安耐吉想要对比价格、筛选最优货源:使用 MolAid 比价。
先抛结论**:没有任何一种 Agent 架构能解决所有问题。与其问"用什么框架",不如先问"我的任务需要哪层约束"。理解这一点,比记住四种模式的名字重要一百倍。
Jina AI 刚发布了 jina-embeddings-v5-omni,第一个同时支持文本、图片、音频和视频的通用嵌入模型。最关键的一点:如果你已经在用 v5-text,现有的文本向量索引不用重建,直接就能搜图片和视频。
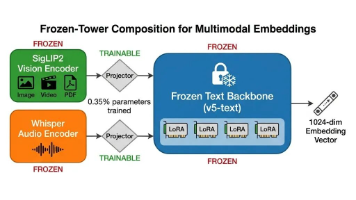
Jina AI发布多模态嵌入模型jina-embeddings-v5-omni,支持文本、图像、音频和视频处理。该模型采用冻结文本骨干网络架构,仅训练0.35%的权重,在保持与v5-text文本嵌入完全一致的同时,新增视觉和音频处理能力。其中1.57B参数的small版本在文本、图像和音频任务上表现优异,接近更大参数量的基线模型;0.95B参数的nano版本则在小规模下保持竞争力。该模型支持模块化
最近在落地基于 RAG 的 Agent 应用时,对爆火的 Jina Embeddings v3 做了一次深度评测。结果发现:5k 规模下表现完美的模型,到了 100k 真实业务库却严重掉点;某种自定义的“长-长同源检索”虽然跑出满分,但换用真实技术问答(BRIGHT)和合同数据集(ACORD)后,MRR 直接跌到 0.17。本文将详细拆解这次评测的实验设计、核心数据以及背后的业务逻辑,并给出真实业
Jina-embeddings-v5-omni是一款创新的多模态嵌入模型,支持文本、图像、视频和音频的统一索引与跨模态检索。该模型基于jina-embeddings-v5-text架构扩展,通过创新的跨模态投影技术整合视觉和音频编码能力,在保持紧凑模型规模(small版7亿参数)的同时,提供行业领先的多媒体语义理解性能。其特点包括:支持近100种语言、可截断嵌入降低存储需求、量化优化提升效率,在视
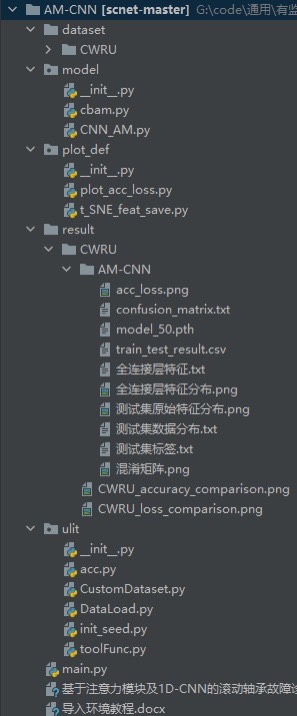
基于注意力模块及1D-CNN的滚动轴承故障诊断故障诊断代码 复现针对传统的卷积神经网络对特征的辨识性差的问题,提出一种将注意力模块与一维卷积神经网络相结合的滚动轴承故障诊断模型首先以加入噪声的振动信号作为输入,利用“卷积+池化”单元提取信号的多维特征,然后通过注意力模块对特征赋予不同的权重,利用双池化层取代传统卷积神经网络中的全连接层进行特征的再次提取及特征信息整合,最后通过 Softmax层完成
jina
——jina
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 DAMO开发者矩阵
DAMO开发者矩阵


 AI Agent技术社区
AI Agent技术社区







 脑启社区
脑启社区


 DeepSeek技术社区
DeepSeek技术社区
 MCP技术社区
MCP技术社区

 快递鸟社区
快递鸟社区


 AI编程社区
AI编程社区

 AtomGit开源社区
AtomGit开源社区





 2048 AI社区
2048 AI社区