- @qq_56591814
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章目录一、RNN1.1 RNN模型结构1.2 RNN模型的缺点二、长短时记忆网络LSTM2.1 LSTM模型结构2.2 双向循环神经网络Bi-LSTM三、序列到序列模型一、RNN前馈神经网络:信息往一个方向流动。包括MLP和CNN循环神经网络:信息循环流动,网络隐含层输出又作为自身输入,包括RNN、LSTM、GAN等。1.1 RNN模型结构RNN模型结构如下图所示:展开之后相当于堆叠多个共享隐含
楼主习惯听课做笔记,这一份是慕课网,北大曹健老师的《人工智能实践-Tensorflow2.0》的全套讲义,包含上课的ppt和另一份pdf文件。整理在

一、文本挖掘原理1 分词的基本原理 现代分词都是基于统计的分词,而统计的样本内容来自于一些标准的语料库。假如有一个句子:“小明来到荔湾区”,我们期望语料库统计后分词的结果是:“小明/来到/荔湾/区”,而不是“小明/来到/荔/湾区”。那么如何做到这一点呢? 从统计的角度,我们期望"小明/来到/荔湾/区"这个分词后句子出现的概率要比“小明/来到/荔/湾区”大。如果用数学的语言来说说,如果有一个句子
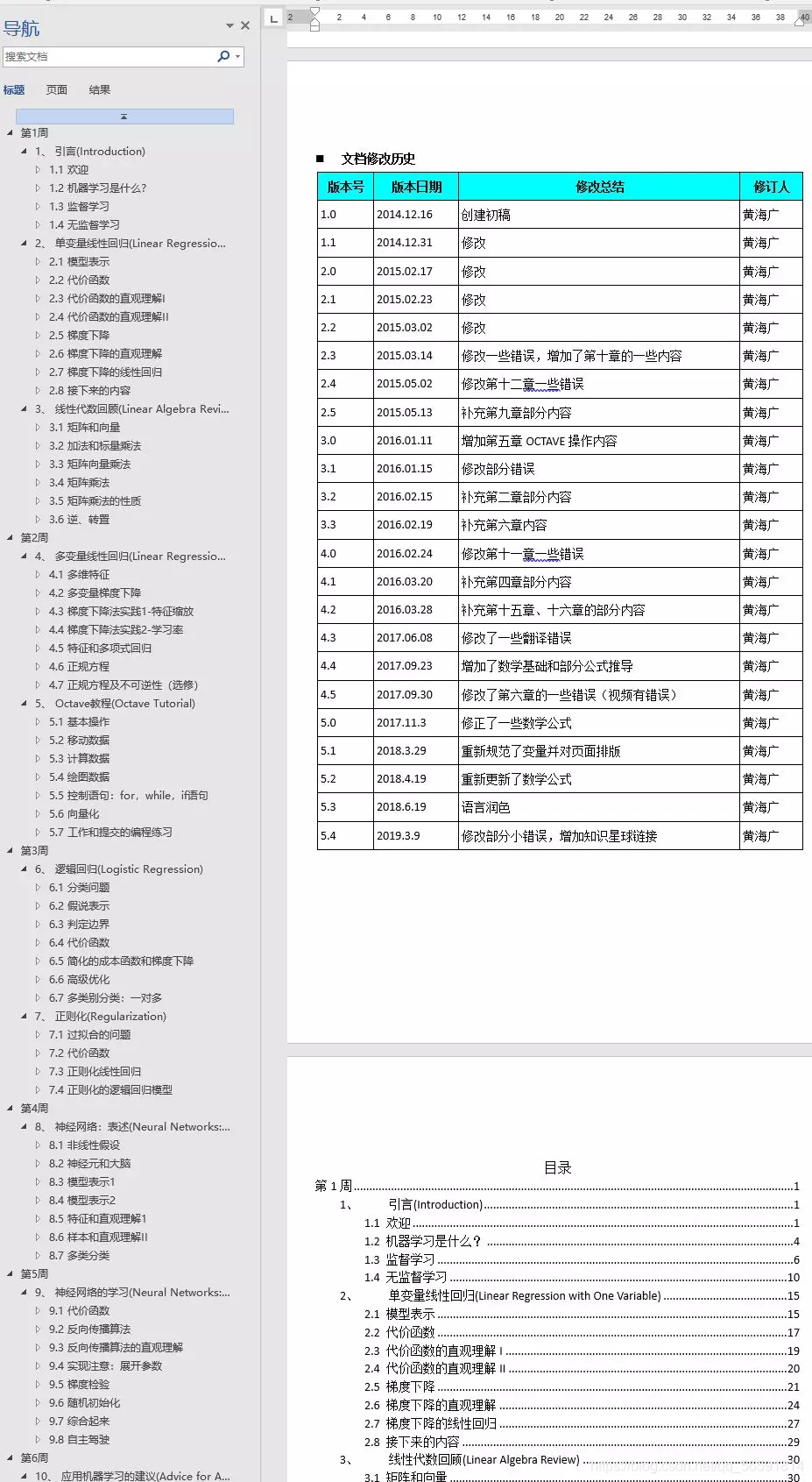
一、语义分割1.1 语义分割简介之前的目标检测都是用锚框来标注和预测图片中主体的位置,而锚框有时候框的是大概的位置。语义分割(semantic segmentation)可以识别并理解图像中每一个像素的内容,其语义区域的标注和预测是像素级的。所以,与目标检测相比,语义分割标注的像素级的边框显然更加精细。语义分割应用:无人驾驶:路面分割计算机视觉领域还有2个与语义分割相似的重要问题,即图像分割(im
当源数据文件夹中的文件数量不断增加时,刷新速度会越来越慢。假设一个解决方案运行了10年,每年有16个数据文件(4个区域 x 4个季度),到2030年时,需要处理的文件数量将超过176个。如果每个文件需要5秒钟来刷新,那么总刷新时间将超过14分钟,这会显著影响用户体验。其实用户完全没必要分析那么多数据,比如业务只需要与前一年的数据进行比较,那么可以通过按日期的降序对文件进行排序,并使用【保留最前面几

SQL Server是微软开发的关系型数据库管理系统(RDBMS),支持Windows和Linux平台。其核心架构包括数据库引擎(关系引擎和存储引擎)和SQLOS操作系统服务层。SQL Server提供丰富的数据管理和商业智能工具,如SSIS、SSAS、SSRS等,以及Python/R机器学习支持。主要版本包括免费的Developer/Express版,以及Enterprise/Standard/

##GitHub###1.个人主页 我的 Timeline,这部分你可以理解成微博,就是你关注的一些人的活动会出现在这里,比如如果你们关注我了,那么以后我 star、fork 了某些项目就会出现在你的时间线里。个人主页your profile###2.基本概念Repository 仓库的意思,即你的项目,你想在 GitHub 上开源一个项目,那就必须要新建一个 Repository,如果你开源
语句用于向表中添加一行或多行数据,其基本语法如下:表名:指定要插入数据的表名,通常包括架构名(如 )。列名列表:指定要插入数据的列名,列名之间用逗号分隔,并用括号括起来-。值列表:为指定的列提供对应的值,值之间用逗号分隔,并用括号括起来。如果表中的某些列未出现在列名列表中,SQL Server 会根据以下规则自动为这些列提供值:为了演示语句的用法,我们首先创建一个名为的表:以下是一个向表中插入新行

Power BI是微软推出的数据分析和可视化工具,可以从各种数据源中提取数据,并对数据进行整理分析,然后生成精美的图表,并且可以在电脑端和移动端与他人共享。:Windows 桌面应用程序,用于创建和设计报表,在本地处理数据,适合数据分析师和报表创建者。数据连接和转换:从多种数据源提取数据并进行清理和转换,使用功能强大的 Power Query 编辑器。数据建模:可创建复杂的模型关系、自定义计算、度

我也是从今年开始学人工智能 ,我的习惯是每听一门课就得做笔记。以前的python入门课、数据分析、算法课都做了,那个有时间再分享。吴恩达的机器学习和深度学习课视频qishihenduodifan