




- @weixin_54703767
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这些步骤将帮助你在Git中成功创建一个新的分支并提交你的更改。记得在进行更改时经常提交,这样可以更好地跟踪和管理更改的历史记录。使用git branch命令创建一个新的分支。使用git commit命令提交你的更改。你应该提供一个描述性的提交信息,说明你所做的更改。暂存更改:使用git add命令暂存你的更改。在你的项目中做出所需的更改。如果你的分支是与他人共享或与远程仓库同步的,你需要使用。使用

在输出中,您应该会看到“Registry Mirrors”行并显示您所添加的镜像站点URL。现在,您已经成功地配置了Docker镜像,可以更快地下载和部署容器。

2023年国内外前端框架优劣势对比,国内:Vue>React>Angular国外:React>Angular>Vue。

是用来管理和配置队列规则的命令。在 Linux 的网络堆栈中,每个网络接口都可以有自己的队列规则,这些规则决定了数据包如何在网络接口上排队、被处理和发送。通过不同的 qdisc 类型和参数,管理员可以精细地控制网络流量,例如限制带宽、控制延迟、优先处理特定类型的流量等。上添加一个新的队列规则(qdisc, queueing discipline)。是一个非常强大的工具,用于控制网络设备上的数据包队

请注意,你可能需要使用管理员权限运行命令提示符,具体方法是右键单击命令提示符图标并选择“以管理员身份运行”。并且‘pip’已经添加到了系统的环境变量中。如果你使用的是虚拟环境,确保你已经激活了虚拟环境。首先打开命令行终端或命令提示符(Command Prompt),win+R打开运行面板,输入cmd。文件是Python的二进制分发格式,通常用于更快地安装Python包一般可以在官网下载得到。在Py

在Docker中进行MySQL数据迁移通常涉及将数据从一个MySQL容器导出,并将其导入到另一个容器或主机上的MySQL实例中。
本文介绍了深度学习模型在训练和部署阶段的内存估算方法。训练阶段需计算模型参数量、优化器状态、梯度和激活值的内存占用,总内存约为这些部分之和。部署阶段则主要考虑量化后的模型参数和推理时的激活值内存,通常比训练阶段少50%-75%。文章提供了PyTorch、TensorRT等工具的具体实现代码,帮助开发者准确评估内存需求。
Jina.AI DeepSearch是一个多阶段研究优化系统,通过结构化流程进行深度信息检索与分析。系统首先进行参数预处理和语言/Schema初始化,随后构建上下文容器与生成器。核心采用主循环机制,包含"计划→行动→评估→记忆"的状态机流程,支持五种主要动作:访问网页(visit)、搜索(search)、直接回答(answer)、反思规划(reflect)和编码协助(codin
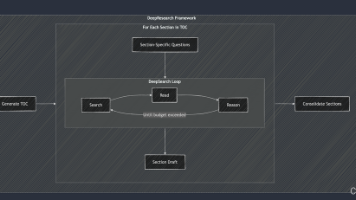
摘要 DeepResearch智能体是新一代能够自主上网搜索、整合信息的AI系统,代表从传统搜索向"提问-自动研究-结论"的范式转变。目前主要有两种技术路径:基于强化学习(RL)的端到端训练方案和基于提示词设计的模块化方案。RL方案通过真实网络环境训练模型掌握检索推理策略,具有更强的自主性和稳健性,如OpenAI DeepResearch、阿里通义DeepResearch等产品
CentOS是一种基于Red Hat Enterprise Linux(RHEL)的开源操作系统,因此与其他基于Linux的系统共享很多相似的命令。以下是一些在CentOS上常用的命令。这只是一小部分CentOS上可能用到的命令,具体的使用方式和参数可以通过命令后加上。此外,你也可以查阅相关文档来深入了解每个命令的用法和选项。
