登录社区云,与社区用户共同成长
邀请您加入社区
小雷哔哔(ID:xiaoleibbb)查了一下,这位老哥是中国科学技术大学的计算机博士,华为首批八位「天才少年」之一,职级干到了 P20,在华为 2012 实验室负责过大模型训练的软硬协同和基础设施优化。离开华为后自己创业。结果面试官看到他频繁瞥向左边的屏幕,直接就认定他在抄代码,当场让他停止,还放话如果你不能证明你没有在抄代码,面试就无法继续下去了。尤其是现在大模型写代码越来越强的时代,企业更应
使用自定义拦截器# type指的是编写java代码所在目录的路径名(我的是在com.bigdata.zidingyi下)# 修改sink为kafka执行之前,先在kafka中创建消息队列(topic)中创建一个topic :zidingyi 数据将会导入到这个topic中创建好后执行conf文件即可可以使用把主题中所有的数据都读取出来(包括历史数据)并且还可以接收来自生产者的新数据。
简单来说,就是当pod重启的时候,会发起一系列的过程,其中在mutating admission controller 这里,k8s提供了一个webhooks,可以回调到指定的地方去,所以我们需要创建一个server来处理该回调,添加一个容器进去,完成容器注入的工作。出现了报错,这应该是由于envoy是监听10000端口,backend服务监听的也是10000端口,现在它们在一个net names
本文深入解析了 Flume 四大经典数据流场景的实战配置与核心原理,覆盖了从跨节点通信到不同文件采集场景的全流程。调试场景优先选择;单文件实时日志采集推荐;批量文件采集优先使用;多文件并行实时采集首选。
因为我们的数仓数据源是Kafka,离线数仓需要用Flume采集Kafka中的数据到HDFS中。在实际项目中,我们不可能一直在Xshell中启动Flume任务,一是因为项目的Flume任务很多,二是一旦Xshell页面关闭Flume任务就会停止。
本文详细介绍了Hadoop启动后的操作流程,包括HDFS基本操作、MapReduce示例运行、Flume日志采集配置以及ZooKeeper的核心概念。
Kafka+Flume实战笔记
从日志到 HBase 的这条实时链路,是大数据入门的一个经典实验。把 Flume、Kafka、Flink 串起来跑通之后,再去看生产架构会清晰很多。如果你在搭建过程中遇到问题,或者有自己想尝试的链路组合,欢迎评论区交流。我会尽量回复。
Noetra计划在遵循修改后的《外汇及对外贸易法》标准的前提下,向日本企业广泛公开模型,通过自主开发确保安全性,而非依赖外部模型,各参与企业也将根据自身场景利用Noetra大模型开发应用。NVIDIA CEO黄仁勋也出席发布会,称日本产业一线的智慧“是国家的瑰宝,不能失去”,并强调自主驱动机器和机器人的物理AI相关基础设施“应该在日本制造”。至于选择通用模型的原因,主要是由于在网络防御等最先进AI
本文介绍了用户行为数据采集平台的设计与实现方案。主要内容包括:1)数据仓库中用户行为数据的分类(页面浏览、动作记录、曝光记录等)和日志格式;2)采用代码埋点、可视化埋点和全埋点三种方式收集数据;3)设计Flume+Kafka+HDFS的数据采集链路,重点说明TailDirSource支持断点续传和KafkaChannel提高传输效率的优势;4)通过拦截器实现数据格式校验。该方案具有高可靠性和实时性
全速体育数据API为开发者提供全球100+职业联赛的足球数据支持,Python生态中的football-api-wrapper库简化了接入流程。通过3行核心代码即可获取实时比分、球员热区等30余项专业数据,支持缓存配置和高并发采集。该方案适用于媒体战报生成、俱乐部人才评估和竞猜风控等场景,配合7×24小时技术支持,成为体育科技创新的重要基础设施。
本文探讨了C++在工业物联网(IIoT)系统中的自动化测试策略与实践。面对多设备、异构协议、高并发和实时性等挑战,提出了分层测试框架:从单元测试到端到端测试,结合GoogleTest等工具验证功能正确性。重点介绍了数据驱动仿真测试、CI/CD集成及容错机制,通过故障注入验证系统可靠性。实践表明,该方法提高缺陷发现率35%,降低延迟25%,缩短故障恢复至2秒内,实现了90%的自动化测试覆盖率,有效保
本文探讨了C++在智能工业机器人调度系统中的应用及其自动化测试策略。系统通过实时监控与调度实现高效自动化生产,但面临多机器人协同、实时性、复杂场景等挑战。文章提出分层测试方法,包括单元测试、接口测试、集成测试等,并使用GoogleTest、clang-tidy等工具确保系统稳定性。通过数据驱动测试和仿真平台验证复杂场景下的调度性能,建立CI/CD流程实现持续集成。实践表明,该方法显著提升了系统稳定
本文探讨C++智能物流无人车调度系统的自动化测试策略,重点解决多无人车协同、实时性要求高、复杂物流场景等测试挑战。通过分层测试策略(单元/接口/集成/端到端测试)结合GoogleTest、仿真平台等工具,实现90%自动化覆盖率,关键缺陷发现率提升35%。测试优化使任务延迟降低25%,配送效率提升30%,并通过CI/CD集成将回归效率提高50%。系统在容错机制保障下实现2秒内异常响应,为智能物流提供
摘要:本文探讨了C++无人驾驶决策系统的测试与优化策略。面对多源数据融合、复杂场景验证和实时性等挑战,采用分层测试体系(单元测试、集成测试、仿真测试等),结合自动化工具(GoogleTest、CARLA等)实现高效验证。通过并行计算、内存优化等技术提升性能,测试结果显示决策延迟降低33ms,安全误判率下降47%。C++凭借高性能优势,结合分层测试和持续优化机制,为无人驾驶系统提供可靠保障,未来将向
企业级Java应用中的分布式缓存(如Redis、Memcached)面临多节点管理、高并发响应和缓存一致性等运维挑战。本文系统介绍了分布式缓存的全流程优化方案:通过Jedis、ELK等工具实现实时监控和日志分析;利用哨兵机制、SpringCache提升高可用性和热点数据处理;结合Python/Shell脚本实现自动化部署与扩容。实践表明,该方案使缓存命中率提升20%,故障切换成功率95%,平均延迟
本文对比分析了Java、C#和C++三种主流编程语言的特性与应用场景。Java凭借JVM跨平台优势在企业级开发和大数据处理领域占据重要地位;C#与微软生态紧密结合,在Web开发、游戏和桌面应用中表现突出;C++则以高性能和底层控制能力在系统编程和游戏开发中不可替代。文章详细探讨了各语言的优缺点,建议开发者根据项目需求(平台兼容性、性能要求、开发效率等)选择最合适的语言,以优化开发过程和系统效能。
本文对比分析了Java、C#和C++三大主流编程语言的特性与应用场景。Java凭借JVM实现跨平台能力,适合企业级应用和Android开发;C#依托.NET生态,在Web和游戏开发中优势明显;C++则以高性能和底层控制见长,适用于系统编程和游戏引擎。选择时应考虑项目需求、性能要求和技术栈匹配,Java适合企业应用,C#适合微软生态项目,C++则适用于高性能计算和系统级开发。
本文对比了Java、C#和C++三种主流编程语言的特点和适用场景。Java凭借跨平台性和强大的开发框架,成为企业级应用和大数据处理的首选,但存在性能瓶颈。C#在微软生态中表现优异,适合企业应用和游戏开发,但跨平台兼容性有限。C++则以高性能和底层控制能力见长,适用于系统级开发和高性能计算,但开发复杂度较高。开发者应根据项目需求、技术栈和性能要求选择最适合的语言。
Java:如果你需要开发跨平台的企业级应用,Java 是非常合适的选择,尤其适用于后台服务和 Android 应用开发。Python:如果你从事数据分析、机器学习或快速原型开发,Python 由于其简洁和强大的库支持,非常适合快速开发。C++:对于要求极高性能的应用(如游戏引擎、操作系统开发),C++ 依然是首选语言,能够提供最强的硬件控制和性能优化。C#:如果你在微软的生态系统中工作,特别是 W
GitHub技术趋势与选型指南:基于DeepSeek联网分析 摘要:本文通过DeepSeek联网能力分析GitHub热门仓库,揭示202X年Q1技术趋势。AI/LLM领域(LangChain、vLLM)增长迅猛,Rust生态扩展明显,开发者体验工具(drizzle-orm、Devbox)受追捧。
好的工具不会削弱这一过程的价值,反而会**增强我们的表达能力,释放更多精力专注于真正重要的科学思考**。更重要的是,它提供的不是僵化的模板,而是**可灵活调整的动态框架**。而书匠策AI的不同之处在于,它似乎真正理解**科研写作的独特语言体系**和**学术出版的隐形规则**。许多用户反馈,使用这类工具后,**写作时间平均缩短了30%-40%**,更重要的是,**写作过程从痛苦负担转变为有成就感的创
✅ 内置全协议:PD/QC/BC1.2,无需诱骗芯片,一芯搞定✅ 2–5串通用:8.4V–21V全覆盖,适配多串锂电✅ 2A大电流:35W快充,充电速度提升3倍+✅ 三段式智能充电:0V激活+恒流+恒压+满电自停✅ 全保护:OVP/UVP/OCP/OTP/SCP,安全无忧✅ 极简外围:开发快、成本低、量产易在多节锂电池设备全面快充化的今天,XSP33以内置协议、升降压、2A快充、全保护、极简设计的
汇铭达XSP16是一款高性能Type-C诱骗取电芯片,支持PD3.1全协议及140W大功率输出。该芯片具有全协议兼容(PD/QC/FCP/AFC)、28V/5A高功率输出、UART通信等核心优势,适用于电动工具、工业设备等场景。通过电阻配置或GPIO动态调压,可灵活设置输出电压。XSP16集成度高、体积小,能简化外围电路,是大功率设备和多串锂电池快充的理想解决方案。
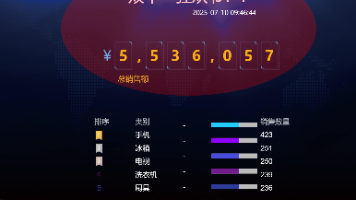
该流程实现了一个实时数据处理与展示系统:1. 数据采集层:Flume监听order.txt文件,实时采集新增订单数据并发送至Kafka消息队列。2. 数据处理层:Flink消费Kafka数据,通过流处理计算订单总金额和商品类型TopN,结果存储到Redis。3. 数据展示层:SpringBoot服务提供REST API,从Redis获取处理结果并返回JSON格式数据,最终在百度云Sugar大屏实时
1、日志系统(FLUME、kafka)1.1FLUME概念: Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制。特点:flume具有高可用,分布式,配置工具,其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中...
C#.net开发ABB机器人上位机操作机器人动作及读写数据ABB机器人操作类,程序包含运行数据记录,设备报警信息显示,项目比较完整,适合自己做二次开发。在自动化控制领域,ABB机器人以其高精度和稳定性备受青睐。今天咱就唠唠如何用C#.NET开发ABB机器人上位机,实现对机器人动作的精准操作以及数据的高效读写。
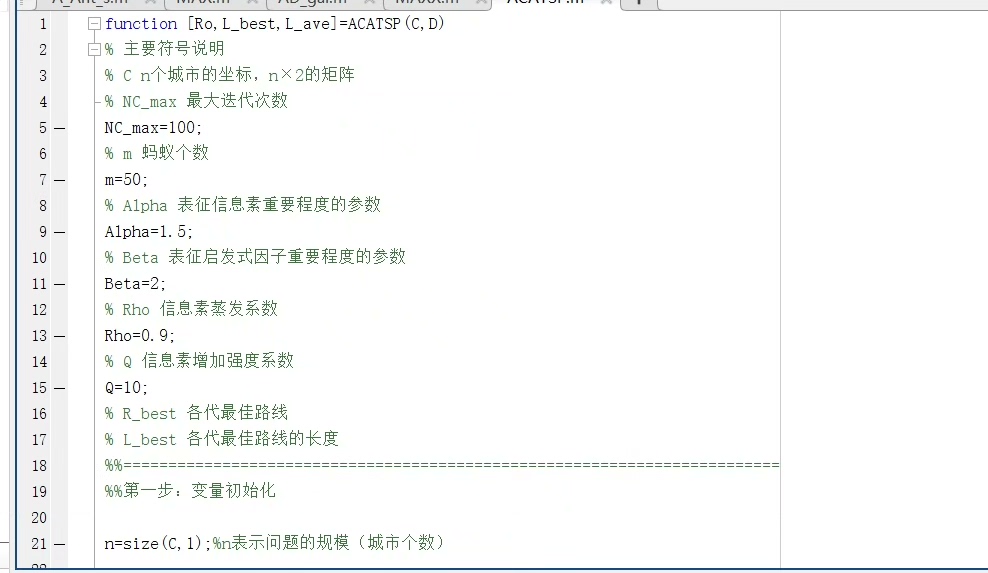
把所有点位两两之间的路径都算出来后,咱们就得到了一张路径代价矩阵——这相当于给后续的蚁群算法准备了城市距离表。厨房飘着咖喱香,送餐机器人小R盯着屏幕上闪烁的八个取餐点坐标,触角天线微微颤动——今天的路径规划挑战开始了。生成的0-3、3-1、1-2、2-0的路径片段连接起来。总路径长度校验时要注意转角处的距离计算——有些时候直接相加会比实际走出来的路线短,这时候需要重新跑一遍完整路径的A。2,蚁群算
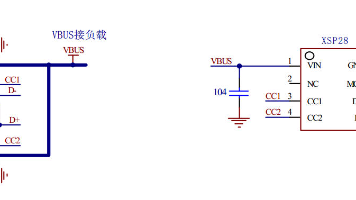
摘要:汇铭达XSP28快充电压诱骗芯片凭借多协议兼容、高安全性及简洁设计成为快充解决方案优选。该芯片支持PD3.0/2.0、QC3.0/2.0等主流快充协议,适配USB-C和USB-A双接口充电器,通过电阻设定灵活输出电压并具备自动降级功能。其21V高耐压设计增强安全性,极简外围电路(仅需1颗电容)显著降低开发成本,广泛应用于智能家居、小家电等领域,为设备提供高效稳定的快充支持。
企业在选择远程桌面方案时,需综合权衡安全合规、国产化适配、功能完善度及部署模式等多方面因素,其中安全保障更是决策的核心考量。TeamViewer在全球范围内享有较高知名度,支持Windows、macOS、iOS、Android等系统,技术积累深厚,尤其在AR远程协助方面表现突出,适用于设备类型复杂或具备海外协作需求的企业。平台兼容性上,向日葵全面支持Windows、macOS、iOS、Androi
通过 GLM-5.1 的全面支持和 Gemini CLI 的成功集成,HagiCode 进一步强化了其作为多模型、多 CLI AI 编程平台的能力。这些更新不仅为用户提供了更多的选择,也展示了 HagiCode 在架构设计上的前瞻性和可扩展性。GLM-5.1 的图片支持能力,结合 HagiCode 的截图上传功能,让"看图说话"成为可能——大大降低了问题描述的成本。而十个 CLI 的支持,意味着用
工具的价值,不在于替你干活,而在于帮你把时间花在真正值得思考的地方。*)做的事情,就是把选题、找文献、搭大纲这些最耗时间最让人焦虑的环节,用AI帮你压缩到几分钟。然后你把省下来的时间,用来打磨正文、用来跟导师沟通、用来真正提升论文质量。这才是AI写论文的正确打开方式。所以,如果你现在正对着空白文档发呆,别硬扛了。👉微信公众号搜一搜:书匠策AI👉你的论文破局之路,可能就从今天这一步开始。冲就完了
所以我做了一个 **Flume 实战模拟器**,它是一个**网页版的可视化实验工具**,你点一下按钮,就能看到一条“用户点击商品的日志”怎么从 Source 流到 Channel,再被 Sink 写进 HDFS(数据湖)。| Taildir Source | 监控 `/var/log/xxx/app.log` | 实时读文件,断点续传 || Memory Channel | 高性能场景,可容忍少量
Flume 是大数据生态的“血管”,负责将血液(数据)输送到各个器官(计算引擎)。通过这个模拟器,希望你不再死记硬背xxx.conf配置文件,而是真正理解Agent 内部的运作机制。如果觉得这个模拟器对你有帮助,欢迎,后续我会推出更多大数据组件的可视化教程!
##kafka.bootstrap.servers = master:9092:指定 Kafka 集群的地址和端口(master 是 Kafka 服务器的主机名,9092 是默认端口)###type = org.apache.flume.sink.kafka.KafkaSink:指定数据目的地类型为 KafkaSink,即数据最终会发送到 Kafka。###kafka.topic = order:
flume
——flume
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区








 DAMO开发者矩阵
DAMO开发者矩阵

 快递鸟社区
快递鸟社区
 AI Agent技术社区
AI Agent技术社区

















 HarmonyOS开发者社区
HarmonyOS开发者社区

 智能体开发者社区
智能体开发者社区
 AtomGit开源社区
AtomGit开源社区

 openEuler 社区
openEuler 社区

