




- @starzhou
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这也是DeepSeek官方自研Harness首次以正式命名出现,此前,梁文锋曾把AGI的实现路径比作爬楼梯:语言模型是第一级,去年解决的是CoT(思维链),今年的台阶是Agent,而Agent之后必须解决的问题,是持续学习——让模型像人一样长期积累经验,而不是每次都被喂入完整的上下文才能工作。再往后,才是自我迭代的“奇点”与具身智能。DeepSeek 用一个轻量模型的大幅进化,给行业出了一道新题

下载到本地后,一键一键安装,比OpenClaw安装,更加的简单,下一步下一步安装,没有遇到什么问题。这里有个大坑,如果没有内测码的同事需要等等,做个等等党,QClaw 安装万后需要。股市有风险,投资需谨慎!这里有6个专业的股票Skills, 如果您的顺序安装错了,无穷无尽的深渊等着您。这里有很多大坑,安装错了,你将永远是九菲特,永远也成不了巴菲特,教您避坑。给出了投资建议,太专业了,太专业了,必大

下载到本地后,一键一键安装,比OpenClaw安装,更加的简单,下一步下一步安装,没有遇到什么问题。这里有个大坑,如果没有内测码的同事需要等等,做个等等党,QClaw 安装万后需要。股市有风险,投资需谨慎!这里有6个专业的股票Skills, 如果您的顺序安装错了,无穷无尽的深渊等着您。这里有很多大坑,安装错了,你将永远是九菲特,永远也成不了巴菲特,教您避坑。给出了投资建议,太专业了,太专业了,必大

-\-gpu\-memory\-utilization 0\.85显存利用率限制,避免 OOM单卡建议 0.8,多卡可设 0.85~0.9。{"role": "user", "content": "请用 100 字介绍一下 DeepSeek-V4-Flash。\-\-tensor\-parallel\-size N多卡张量并行数,N 为显卡数量单卡设 1,2 卡设 2,以此类推。
系统开发高级工程师李帅介绍,因为AI进来的任务是爆发式的,他们可以通过一些调度策略,生图、生视频有的人可能很快几分钟就生成了,优先级高一些,有的可能生成一个几个小时的视频,这样对别人来说体验就不好,就可以适当放到晚上,比如闲散的时候去调度。国联民生证券研究所副总经理孔蓉表示,中国的大模型和中国的AI产品,在一开始就已经开始全球化,几家有代表性的模型公司在海外主流市场里面,开发者的评分和他们的评价是
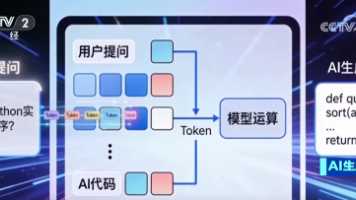
我们不讲晦涩的技术原理,只用最生活化的方式,帮你彻底搞懂Token这个AI世界的"基本单位"。比如"薛定谔的猫",它可能把"薛定谔"打包成一个Token,但并不知道这是个物理学概念。下次当你和AI对话时,不妨想象一下:你的每句话都在被"切配工"切成小块,送给"主厨"大模型烹饪,最后端出一道道"文字大餐"。训练数据中,“鸡蛋"出现频率远高于"鸭蛋”,"关羽"和"孙悟空"作为高频词被打包,而"沙悟净"
说实话,"Token"这个词,在AI圈里不新鲜。大模型处理文本、图像、视频,基本单位就是Token。你问ChatGPT一个问题,它按Token数计费;你让豆包生成一张图,背后也是Token在流转。Token就是AI时代的"流量单位"。以前卖的是网络流量(GB),现在卖的是智能流量(Token)。第一,把各种大模型的Token都接进来。闭源的、开源的、自研的,全部汇聚到移动云平台,让用户一站式调用。

企业客户面对的不再是“要不要用AI”,而是“Token账单谁来管、怎么管、怎么变成利润”。核心逻辑不再是贩卖Token原料,而是将Token与智能体一并封装,以“主从智能体协同”的方式交付可执行任务、可量化结果的服务成品。“卖原料”和“卖成品”之间,存在可观的定价差和客户黏性差。谁能先建立生产、营销、运营的完整闭环,谁能率先将Token封装为智能体产品,谁就能在AI投资回报率上拉开差距。掌握Tok

随着Token(词元)经营战略的密集落地,三大运营商在AI领域的竞争愈发激烈。在日前举行的2026移动云大会上,中国移动正式发布了Token运营生态体系与移动模型服务平台MoMA,宣布接入超300款模型,并通过Token集约化运营模式实现单位Token成本压降约30%;同时联合多家头部企业组建生态联盟,以统一标准破解AI模型调用碎片化难题。

企业客户面对的不再是“要不要用AI”,而是“Token账单谁来管、怎么管、怎么变成利润”。核心逻辑不再是贩卖Token原料,而是将Token与智能体一并封装,以“主从智能体协同”的方式交付可执行任务、可量化结果的服务成品。“卖原料”和“卖成品”之间,存在可观的定价差和客户黏性差。谁能先建立生产、营销、运营的完整闭环,谁能率先将Token封装为智能体产品,谁就能在AI投资回报率上拉开差距。掌握Tok